On the Universal Truthfulness Hyperplane Inside LLMs

0

Sign in to get full access
Overview
- This paper explores a "universal truthfulness hyperplane" within large language models (LLMs), which could help mitigate the problem of hallucination - when LLMs generate plausible-sounding but factually incorrect outputs.
- The researchers propose that there is a subspace within the high-dimensional hidden representations of LLMs that is particularly aligned with truthful outputs, and they aim to identify and leverage this "truthfulness hyperplane."
- By probing the hidden states of LLMs and aligning their outputs to this truthfulness hyperplane, the researchers hope to improve the factual reliability of these powerful AI models.
Plain English Explanation
Large language models (LLMs) like GPT-3 and BERT have become incredibly powerful at generating human-like text. However, they can sometimes produce outputs that sound convincing but are actually factually incorrect - a phenomenon known as "hallucination." This paper explores the idea that there may be a specific subspace within the hidden representations of LLMs that is particularly aligned with truthful, factual outputs.
The researchers hypothesize that there is a "truthfulness hyperplane" inside these LLMs - a higher-dimensional plane or space that captures the model's understanding of what is truthful and factual. By identifying this truthfulness hyperplane and aligning the model's outputs to it, the researchers hope to mitigate the problem of hallucination and improve the factual reliability of these powerful AI systems. [This builds on prior work on identifying hallucinations in LLMs and ways to improve their factual knowledge and grounding](https://aimodels.fyi/papers/arxiv/large-language-models-hallucination-regard-to-known, https://aimodels.fyi/papers/arxiv/towards-holistic-evaluation-llms-factual-knowledge-recall, https://aimodels.fyi/papers/arxiv/self-alignment-factuality-mitigating-hallucinations-llms-via).
By probing the hidden activations and internal representations of LLMs, the researchers aim to uncover this truthfulness hyperplane and leverage it to produce more trustworthy and factually-grounded outputs from these models. This could have significant implications for real-world applications of LLMs where reliability and truthfulness are paramount.
Technical Explanation
The core idea of this paper is that there exists a "universal truthfulness hyperplane" within the high-dimensional hidden representations of large language models (LLMs) that encodes the model's understanding of what is truthful and factual.
The researchers hypothesize that by identifying and aligning the model's outputs to this truthfulness hyperplane, they can mitigate the problem of hallucination - when LLMs generate plausible-sounding but factually incorrect outputs. [This builds on prior work on analyzing and improving the factual knowledge and reliability of LLMs](https://aimodels.fyi/papers/arxiv/large-language-models-hallucination-regard-to-known, https://aimodels.fyi/papers/arxiv/towards-holistic-evaluation-llms-factual-knowledge-recall, https://aimodels.fyi/papers/arxiv/self-alignment-factuality-mitigating-hallucinations-llms-via).
Through a series of experiments, the researchers probe the hidden representations of pre-trained LLMs like GPT-3 and BERT to try to uncover this truthfulness hyperplane. They develop techniques to identify the directions in the hidden state space that are most strongly correlated with factual correctness, and then use this information to edit and refine the model's outputs to be more truthful and reliable.
The results suggest that there does indeed appear to be a subspace within the high-dimensional hidden representations of LLMs that is particularly aligned with truthful, factual outputs. By identifying and leveraging this "truthfulness hyperplane," the researchers are able to improve the factual reliability of the models' generation, reducing hallucination without significantly impacting performance on other tasks.
Critical Analysis
The central premise of this paper - that there exists a "truthfulness hyperplane" within LLMs that can be identified and exploited - is a compelling one. The researchers provide evidence that such a subspace exists and that aligning model outputs to it can improve factual reliability. However, the work also raises some important caveats and areas for further research.
One key limitation is the reliance on probing techniques to uncover the truthfulness hyperplane. While the methods used seem promising, they may not fully capture the nuances and complexities of how truthfulness is encoded within these massive neural networks. There could be more subtle or non-linear relationships between the hidden representations and factual correctness that are not easily uncovered.
Additionally, the experiments in this paper focus on a relatively narrow set of evaluation tasks and datasets. It remains to be seen how well the findings generalize to a broader range of real-world applications and use cases where factual reliability is paramount. Continued research and validation across diverse domains will be crucial.
Finally, the paper does not delve deeply into the potential risks or downsides of over-relying on the truthfulness hyperplane. Over-optimization towards this subspace could potentially lead to other unintended consequences or biases in the model's outputs. Careful consideration of these tradeoffs will be important as this line of research progresses.
Conclusion
Overall, this paper presents a promising direction for improving the factual reliability of large language models by identifying and leveraging a "universal truthfulness hyperplane" within their hidden representations. By probing the internal workings of these powerful AI systems, the researchers have uncovered an intriguing property that could help mitigate the problem of hallucination and build more trustworthy, factually-grounded language models.
While the work has some caveats and limitations that warrant further exploration, the core idea of aligning LLMs to a truthfulness subspace is an exciting development that could have significant implications for real-world applications of these transformative technologies. Continued research in this area has the potential to make important strides towards more reliable and trustworthy artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
On the Universal Truthfulness Hyperplane Inside LLMs
Junteng Liu, Shiqi Chen, Yu Cheng, Junxian He
While large language models (LLMs) have demonstrated remarkable abilities across various fields, hallucination remains a significant challenge. Recent studies have explored hallucinations through the lens of internal representations, proposing mechanisms to decipher LLMs' adherence to facts. However, these approaches often fail to generalize to out-of-distribution data, leading to concerns about whether internal representation patterns reflect fundamental factual awareness, or only overfit spurious correlations on the specific datasets. In this work, we investigate whether a universal truthfulness hyperplane that distinguishes the model's factually correct and incorrect outputs exists within the model. To this end, we scale up the number of training datasets and conduct an extensive evaluation -- we train the truthfulness hyperplane on a diverse collection of over 40 datasets and examine its cross-task, cross-domain, and in-domain generalization. Our results indicate that increasing the diversity of the training datasets significantly enhances the performance in all scenarios, while the volume of data samples plays a less critical role. This finding supports the optimistic hypothesis that a universal truthfulness hyperplane may indeed exist within the model, offering promising directions for future research.
Read more7/12/2024

0
TruthX: Alleviating Hallucinations by Editing Large Language Models in Truthful Space
Shaolei Zhang, Tian Yu, Yang Feng
Large Language Models (LLMs) sometimes suffer from producing hallucinations, especially LLMs may generate untruthful responses despite knowing the correct knowledge. Activating the truthfulness within LLM is the key to fully unlocking LLM's knowledge potential. In this paper, we propose TruthX, an inference-time intervention method to activate the truthfulness of LLM by identifying and editing the features within LLM's internal representations that govern the truthfulness. TruthX employs an auto-encoder to map LLM's representations into semantic and truthful latent spaces respectively, and applies contrastive learning to identify a truthful editing direction within the truthful space. During inference, by editing LLM's internal representations in truthful space, TruthX effectively enhances the truthfulness of LLM. Experiments show that TruthX improves the truthfulness of 13 advanced LLMs by an average of 20% on TruthfulQA benchmark. Further analyses suggest that TruthX can control LLM to produce truthful or hallucinatory responses via editing only one vector in LLM's internal representations.
Read more6/6/2024

0
WildHallucinations: Evaluating Long-form Factuality in LLMs with Real-World Entity Queries
Wenting Zhao, Tanya Goyal, Yu Ying Chiu, Liwei Jiang, Benjamin Newman, Abhilasha Ravichander, Khyathi Chandu, Ronan Le Bras, Claire Cardie, Yuntian Deng, Yejin Choi
While hallucinations of large language models (LLMs) prevail as a major challenge, existing evaluation benchmarks on factuality do not cover the diverse domains of knowledge that the real-world users of LLMs seek information about. To bridge this gap, we introduce WildHallucinations, a benchmark that evaluates factuality. It does so by prompting LLMs to generate information about entities mined from user-chatbot conversations in the wild. These generations are then automatically fact-checked against a systematically curated knowledge source collected from web search. Notably, half of these real-world entities do not have associated Wikipedia pages. We evaluate 118,785 generations from 15 LLMs on 7,919 entities. We find that LLMs consistently hallucinate more on entities without Wikipedia pages and exhibit varying hallucination rates across different domains. Finally, given the same base models, adding a retrieval component only slightly reduces hallucinations but does not eliminate hallucinations.
Read more7/25/2024
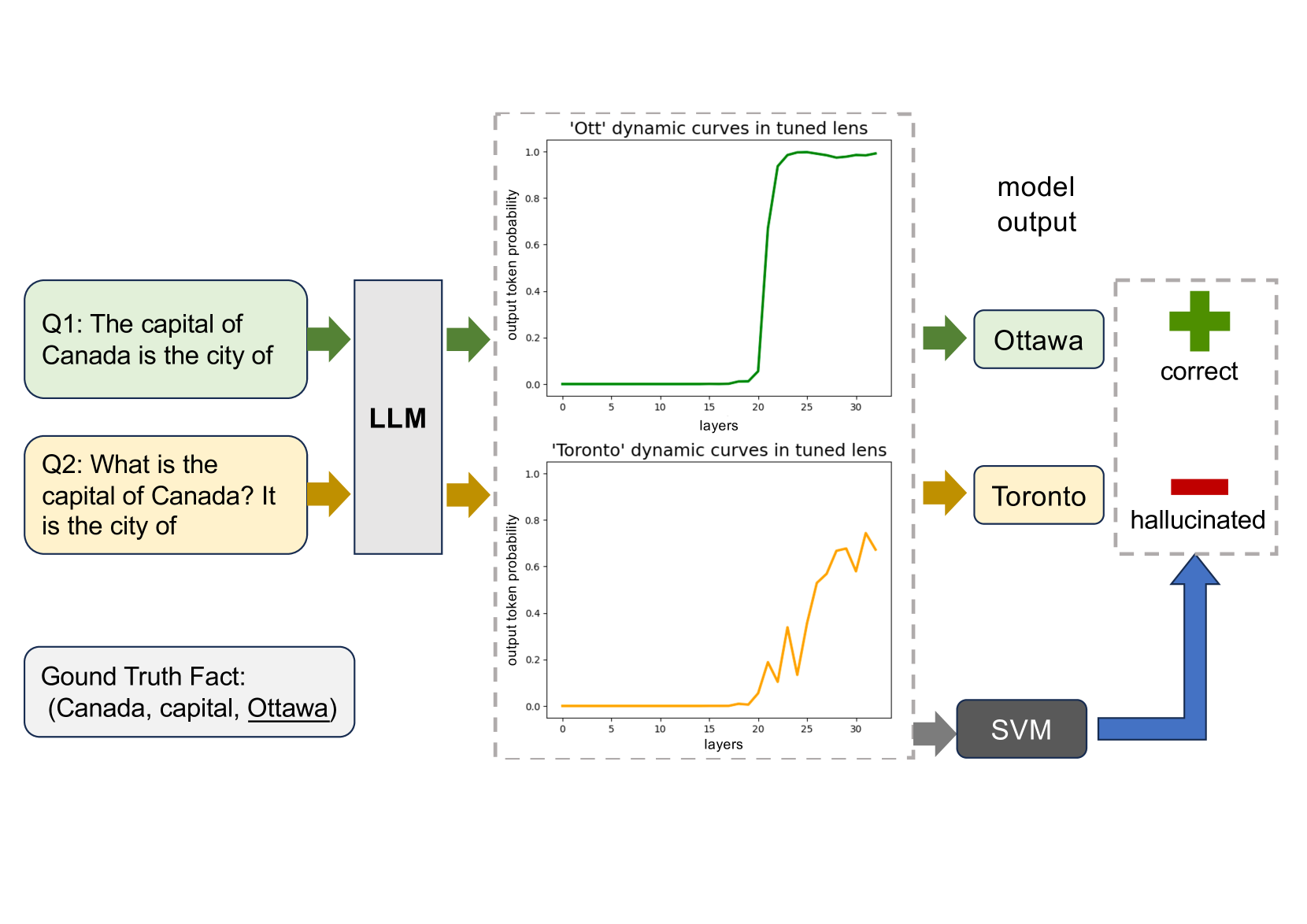
0
On Large Language Models' Hallucination with Regard to Known Facts
Che Jiang, Biqing Qi, Xiangyu Hong, Dayuan Fu, Yang Cheng, Fandong Meng, Mo Yu, Bowen Zhou, Jie Zhou
Large language models are successful in answering factoid questions but are also prone to hallucination.We investigate the phenomenon of LLMs possessing correct answer knowledge yet still hallucinating from the perspective of inference dynamics, an area not previously covered in studies on hallucinations.We are able to conduct this analysis via two key ideas.First, we identify the factual questions that query the same triplet knowledge but result in different answers. The difference between the model behaviors on the correct and incorrect outputs hence suggests the patterns when hallucinations happen. Second, to measure the pattern, we utilize mappings from the residual streams to vocabulary space. We reveal the different dynamics of the output token probabilities along the depths of layers between the correct and hallucinated cases. In hallucinated cases, the output token's information rarely demonstrates abrupt increases and consistent superiority in the later stages of the model. Leveraging the dynamic curve as a feature, we build a classifier capable of accurately detecting hallucinatory predictions with an 88% success rate. Our study shed light on understanding the reasons for LLMs' hallucinations on their known facts, and more importantly, on accurately predicting when they are hallucinating.
Read more4/1/2024