WildHallucinations: Evaluating Long-form Factuality in LLMs with Real-World Entity Queries

0

Sign in to get full access
Overview
- The paper "WildHallucinations: Evaluating Long-form Factuality in LLMs with Real-World Entity Queries" proposes a new benchmark for assessing the factuality of long-form text generated by large language models (LLMs).
- The benchmark, called WildHallucinations, challenges LLMs to answer queries about real-world entities, evaluating their ability to generate factual and coherent long-form responses.
- The authors find that current LLMs struggle with this task, often hallucinating details or making factual errors, highlighting the need for further research to improve the factuality of LLM outputs.
Plain English Explanation
The paper introduces a new way to test the accuracy and truthfulness of long passages generated by large language models (LLMs), which are AI systems trained on vast amounts of text data. These models can create human-like text on a wide range of topics, but they don't always get the facts right.
The authors created the WildHallucinations benchmark, which asks LLMs to answer specific questions about real-world entities, like famous people or historical events. This tests the models' ability to generate long, coherent responses that are grounded in factual information, rather than making up details (a problem known as "hallucination").
Through their experiments, the researchers found that current LLMs struggle with this task. The models often include inaccurate or made-up information in their responses, revealing limitations in their understanding of the real world. This highlights the need for further advancements to improve the factual reliability of these powerful language generation systems.
Technical Explanation
The paper introduces the WildHallucinations benchmark, which aims to evaluate the factuality of long-form text generated by large language models (LLMs) in response to queries about real-world entities.
The benchmark consists of a set of prompts that ask LLMs to provide long-form, open-ended responses to questions about famous people, historical events, and other real-world entities. The responses are then evaluated for factual accuracy by comparing them to ground truth information from reliable sources.
The authors test several state-of-the-art LLMs, including GPT-3, InstructGPT, and LLaMA, on the WildHallucinations benchmark. They find that the models struggle to generate responses that are both factually accurate and coherent, often hallucinating details or making factual errors.
The paper's analysis highlights key limitations in the factual knowledge and reasoning capabilities of current LLMs, which have important implications for the deployment of these systems in real-world applications. The authors argue that the WildHallucinations benchmark provides a valuable tool for measuring and improving the factuality of LLM outputs.
Critical Analysis
The paper makes a compelling case for the need to rigorously evaluate the factuality of long-form text generated by LLMs, as evidenced by the limitations the authors uncover through the WildHallucinations benchmark.
One potential limitation of the study is the relatively small size of the benchmark dataset, which may not capture the full range of challenges LLMs face when generating factual long-form text. Additionally, the evaluation methodology relies on manually curated ground truth information, which could introduce some subjective bias.
Further research could explore ways to expand the WildHallucinations benchmark, perhaps by incorporating automated fact-checking methods or crowdsourcing approaches to validate the accuracy of model outputs. Investigating the underlying causes of hallucination in LLMs, such as biases in the training data or limitations in the models' knowledge representation and reasoning, could also yield valuable insights.
Overall, the paper makes an important contribution by highlighting the pressing need to address the factuality challenges of LLMs, which will be crucial as these powerful language models are increasingly deployed in real-world applications that require reliable and truthful information.
Conclusion
The "WildHallucinations" paper introduces a new benchmark for evaluating the factuality of long-form text generated by large language models (LLMs). The authors find that current state-of-the-art LLMs struggle to consistently produce responses that are both factually accurate and coherent, often hallucinating details or making errors.
This work underscores the importance of developing more robust and reliable language models that can generate truthful and grounded information, particularly as these systems are increasingly integrated into applications that have real-world impact. The WildHallucinations benchmark provides a valuable tool for measuring and improving the factuality of LLM outputs, paving the way for further advancements in this critical area of AI research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
WildHallucinations: Evaluating Long-form Factuality in LLMs with Real-World Entity Queries
Wenting Zhao, Tanya Goyal, Yu Ying Chiu, Liwei Jiang, Benjamin Newman, Abhilasha Ravichander, Khyathi Chandu, Ronan Le Bras, Claire Cardie, Yuntian Deng, Yejin Choi
While hallucinations of large language models (LLMs) prevail as a major challenge, existing evaluation benchmarks on factuality do not cover the diverse domains of knowledge that the real-world users of LLMs seek information about. To bridge this gap, we introduce WildHallucinations, a benchmark that evaluates factuality. It does so by prompting LLMs to generate information about entities mined from user-chatbot conversations in the wild. These generations are then automatically fact-checked against a systematically curated knowledge source collected from web search. Notably, half of these real-world entities do not have associated Wikipedia pages. We evaluate 118,785 generations from 15 LLMs on 7,919 entities. We find that LLMs consistently hallucinate more on entities without Wikipedia pages and exhibit varying hallucination rates across different domains. Finally, given the same base models, adding a retrieval component only slightly reduces hallucinations but does not eliminate hallucinations.
Read more7/25/2024
0
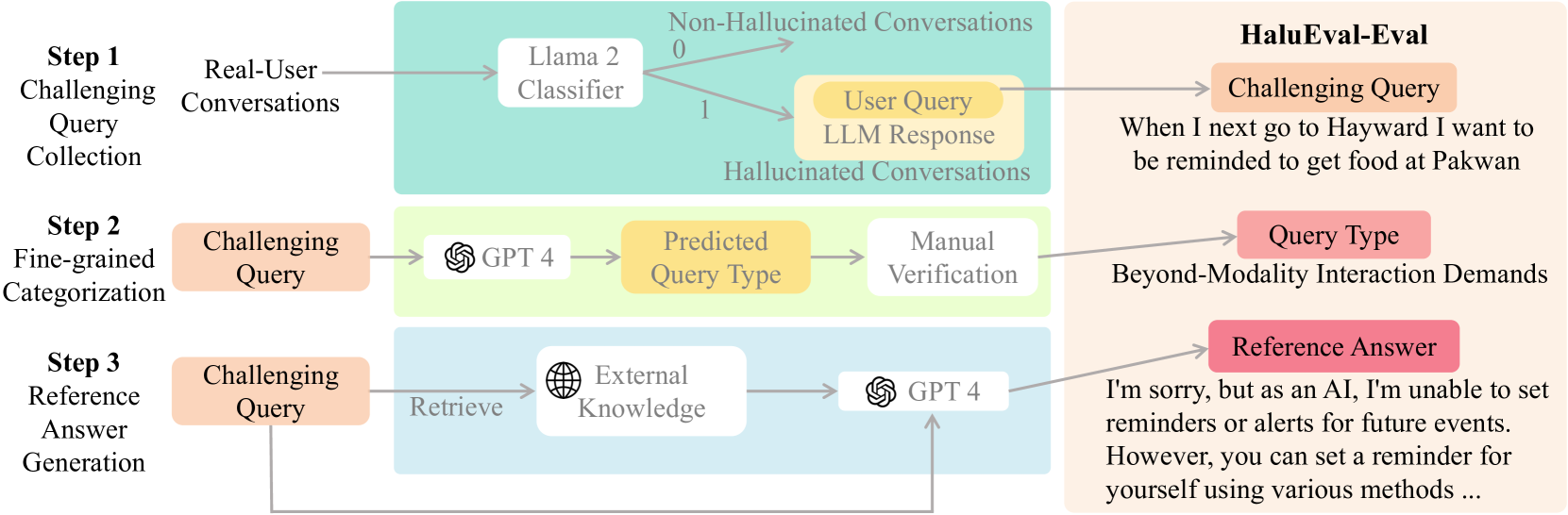
HaluEval-Wild: Evaluating Hallucinations of Language Models in the Wild
Zhiying Zhu, Yiming Yang, Zhiqing Sun
Hallucinations pose a significant challenge to the reliability of large language models (LLMs) in critical domains. Recent benchmarks designed to assess LLM hallucinations within conventional NLP tasks, such as knowledge-intensive question answering (QA) and summarization, are insufficient for capturing the complexities of user-LLM interactions in dynamic, real-world settings. To address this gap, we introduce HaluEval-Wild, the first benchmark specifically designed to evaluate LLM hallucinations in the wild. We meticulously collect challenging (adversarially filtered by Alpaca) user queries from ShareGPT, an existing real-world user-LLM interaction datasets, to evaluate the hallucination rates of various LLMs. Upon analyzing the collected queries, we categorize them into five distinct types, which enables a fine-grained analysis of the types of hallucinations LLMs exhibit, and synthesize the reference answers with the powerful GPT-4 model and retrieval-augmented generation (RAG). Our benchmark offers a novel approach towards enhancing our comprehension of and improving LLM reliability in scenarios reflective of real-world interactions. Our benchmark is available at https://github.com/HaluEval-Wild/HaluEval-Wild.
Read more9/17/2024
⚙️
0
Self-Alignment for Factuality: Mitigating Hallucinations in LLMs via Self-Evaluation
Xiaoying Zhang, Baolin Peng, Ye Tian, Jingyan Zhou, Lifeng Jin, Linfeng Song, Haitao Mi, Helen Meng
Despite showing increasingly human-like abilities, large language models (LLMs) often struggle with factual inaccuracies, i.e. hallucinations, even when they hold relevant knowledge. To address these hallucinations, current approaches typically necessitate high-quality human factuality annotations. In this work, we explore Self-Alignment for Factuality, where we leverage the self-evaluation capability of an LLM to provide training signals that steer the model towards factuality. Specifically, we incorporate Self-Eval, a self-evaluation component, to prompt an LLM to validate the factuality of its own generated responses solely based on its internal knowledge. Additionally, we design Self-Knowledge Tuning (SK-Tuning) to augment the LLM's self-evaluation ability by improving the model's confidence estimation and calibration. We then utilize these self-annotated responses to fine-tune the model via Direct Preference Optimization algorithm. We show that the proposed self-alignment approach substantially enhances factual accuracy over Llama family models across three key knowledge-intensive tasks on TruthfulQA and BioGEN.
Read more6/12/2024
0
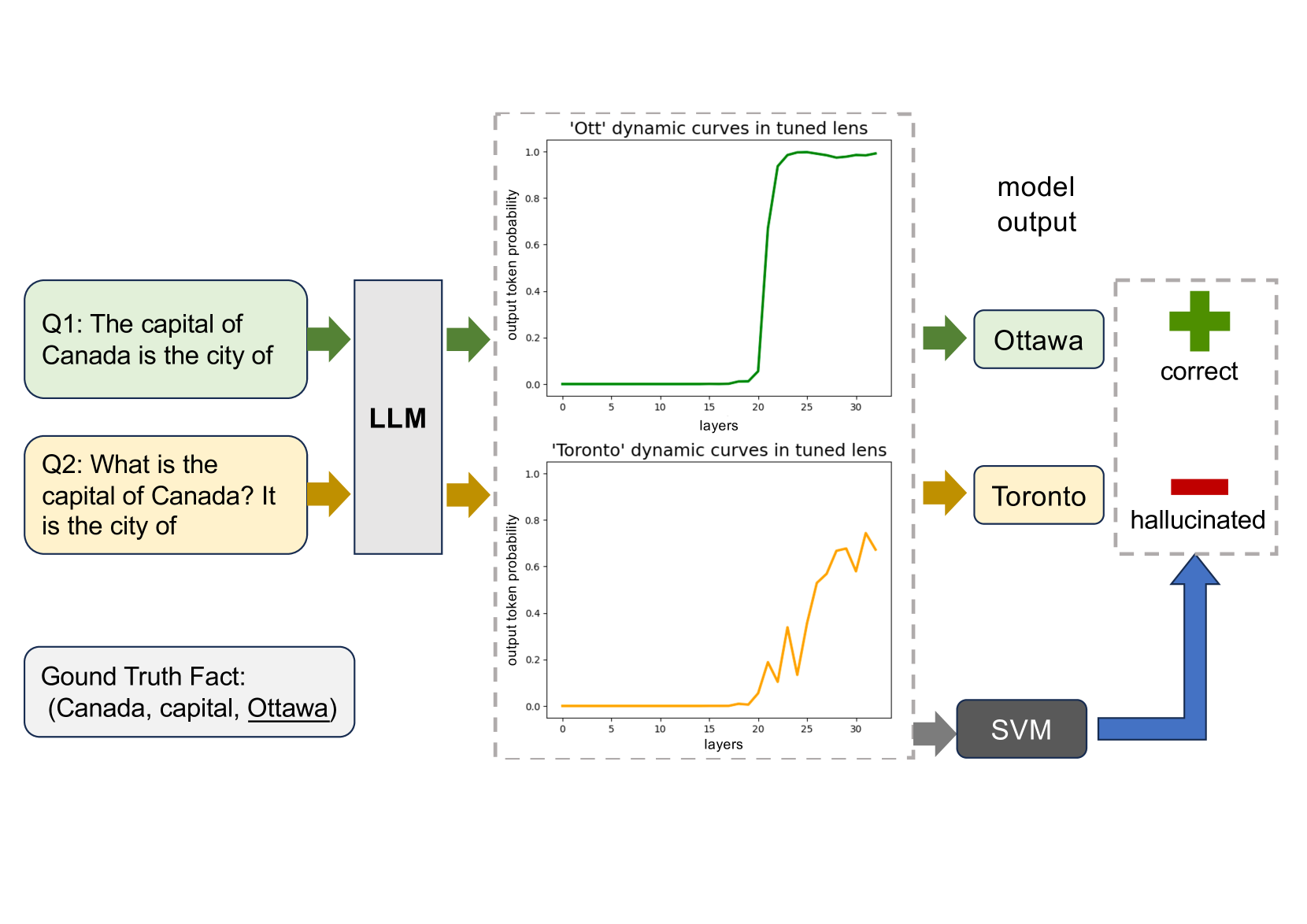
On Large Language Models' Hallucination with Regard to Known Facts
Che Jiang, Biqing Qi, Xiangyu Hong, Dayuan Fu, Yang Cheng, Fandong Meng, Mo Yu, Bowen Zhou, Jie Zhou
Large language models are successful in answering factoid questions but are also prone to hallucination.We investigate the phenomenon of LLMs possessing correct answer knowledge yet still hallucinating from the perspective of inference dynamics, an area not previously covered in studies on hallucinations.We are able to conduct this analysis via two key ideas.First, we identify the factual questions that query the same triplet knowledge but result in different answers. The difference between the model behaviors on the correct and incorrect outputs hence suggests the patterns when hallucinations happen. Second, to measure the pattern, we utilize mappings from the residual streams to vocabulary space. We reveal the different dynamics of the output token probabilities along the depths of layers between the correct and hallucinated cases. In hallucinated cases, the output token's information rarely demonstrates abrupt increases and consistent superiority in the later stages of the model. Leveraging the dynamic curve as a feature, we build a classifier capable of accurately detecting hallucinatory predictions with an 88% success rate. Our study shed light on understanding the reasons for LLMs' hallucinations on their known facts, and more importantly, on accurately predicting when they are hallucinating.
Read more4/1/2024