Towards Spoken Language Understanding via Multi-level Multi-grained Contrastive Learning
2405.20852
0
0

Abstract
Spoken language understanding (SLU) is a core task in task-oriented dialogue systems, which aims at understanding the user's current goal through constructing semantic frames. SLU usually consists of two subtasks, including intent detection and slot filling. Although there are some SLU frameworks joint modeling the two subtasks and achieving high performance, most of them still overlook the inherent relationships between intents and slots and fail to achieve mutual guidance between the two subtasks. To solve the problem, we propose a multi-level multi-grained SLU framework MMCL to apply contrastive learning at three levels, including utterance level, slot level, and word level to enable intent and slot to mutually guide each other. For the utterance level, our framework implements coarse granularity contrastive learning and fine granularity contrastive learning simultaneously. Besides, we also apply the self-distillation method to improve the robustness of the model. Experimental results and further analysis demonstrate that our proposed model achieves new state-of-the-art results on two public multi-intent SLU datasets, obtaining a 2.6 overall accuracy improvement on the MixATIS dataset compared to previous best models.
Create account to get full access
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
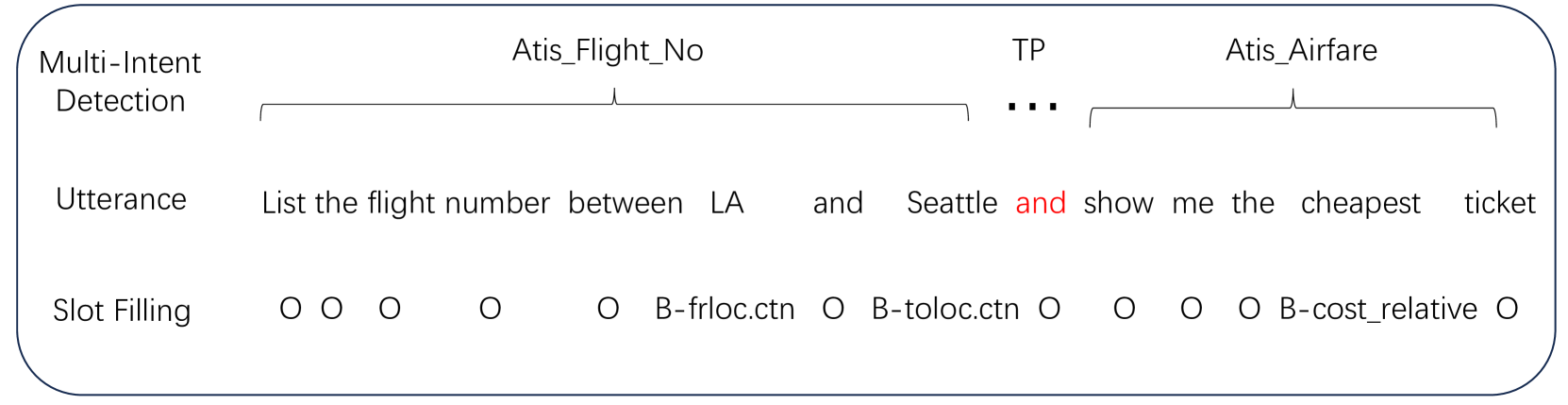
Do Large Language Model Understand Multi-Intent Spoken Language ?
Shangjian Yin, Peijie Huang, Yuhong Xu, Haojing Huang, Jiatian Chen
0
0
This research signifies a considerable breakthrough in leveraging Large Language Models (LLMs) for multi-intent spoken language understanding (SLU). Our approach re-imagines the use of entity slots in multi-intent SLU applications, making the most of the generative potential of LLMs within the SLU landscape, leading to the development of the EN-LLM series. Furthermore, we introduce the concept of Sub-Intent Instruction (SII) to amplify the analysis and interpretation of complex, multi-intent communications, which further supports the creation of the ENSI-LLM models series. Our novel datasets, identified as LM-MixATIS and LM-MixSNIPS, are synthesized from existing benchmarks. The study evidences that LLMs may match or even surpass the performance of the current best multi-intent SLU models. We also scrutinize the performance of LLMs across a spectrum of intent configurations and dataset distributions. On top of this, we present two revolutionary metrics - Entity Slot Accuracy (ESA) and Combined Semantic Accuracy (CSA) - to facilitate a detailed assessment of LLM competence in this multifaceted field. Our code and datasets are available at url{https://github.com/SJY8460/SLM}.
4/16/2024
💬
UniverSLU: Universal Spoken Language Understanding for Diverse Tasks with Natural Language Instructions
Siddhant Arora, Hayato Futami, Jee-weon Jung, Yifan Peng, Roshan Sharma, Yosuke Kashiwagi, Emiru Tsunoo, Karen Livescu, Shinji Watanabe
0
0
Recent studies leverage large language models with multi-tasking capabilities, using natural language prompts to guide the model's behavior and surpassing performance of task-specific models. Motivated by this, we ask: can we build a single model that jointly performs various spoken language understanding (SLU) tasks? We start by adapting a pre-trained automatic speech recognition model to additional tasks using single-token task specifiers. We enhance this approach through instruction tuning, i.e., finetuning by describing the task using natural language instructions followed by the list of label options. Our approach can generalize to new task descriptions for the seen tasks during inference, thereby enhancing its user-friendliness. We demonstrate the efficacy of our single multi-task learning model UniverSLU for 12 speech classification and sequence generation task types spanning 17 datasets and 9 languages. On most tasks, UniverSLU achieves competitive performance and often even surpasses task-specific models. Additionally, we assess the zero-shot capabilities, finding that the model generalizes to new datasets and languages for seen task types.
4/4/2024
💬
Large Language Models for Expansion of Spoken Language Understanding Systems to New Languages
Jakub Hoscilowicz, Pawel Pawlowski, Marcin Skorupa, Marcin Sowa'nski, Artur Janicki
0
0
Spoken Language Understanding (SLU) models are a core component of voice assistants (VA), such as Alexa, Bixby, and Google Assistant. In this paper, we introduce a pipeline designed to extend SLU systems to new languages, utilizing Large Language Models (LLMs) that we fine-tune for machine translation of slot-annotated SLU training data. Our approach improved on the MultiATIS++ benchmark, a primary multi-language SLU dataset, in the cloud scenario using an mBERT model. Specifically, we saw an improvement in the Overall Accuracy metric: from 53% to 62.18%, compared to the existing state-of-the-art method, Fine and Coarse-grained Multi-Task Learning Framework (FC-MTLF). In the on-device scenario (tiny and not pretrained SLU), our method improved the Overall Accuracy from 5.31% to 22.06% over the baseline Global-Local Contrastive Learning Framework (GL-CLeF) method. Contrary to both FC-MTLF and GL-CLeF, our LLM-based machine translation does not require changes in the production architecture of SLU. Additionally, our pipeline is slot-type independent: it does not require any slot definitions or examples.
4/4/2024
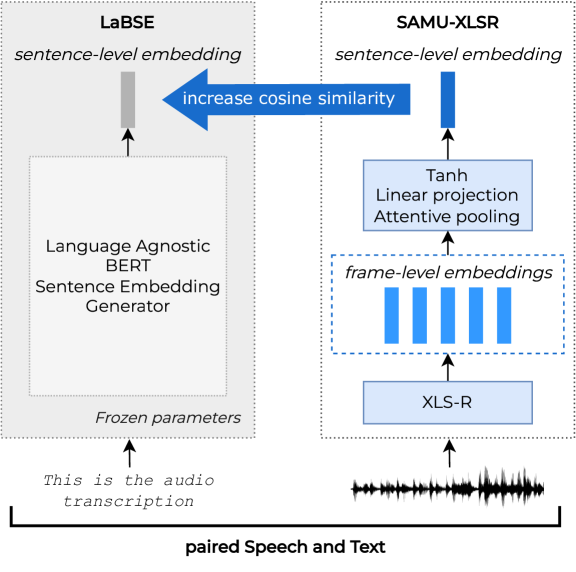
A dual task learning approach to fine-tune a multilingual semantic speech encoder for Spoken Language Understanding
Gaelle Laperri`ere, Sahar Ghannay, Bassam Jabaian, Yannick Est`eve
0
0
Self-Supervised Learning is vastly used to efficiently represent speech for Spoken Language Understanding, gradually replacing conventional approaches. Meanwhile, textual SSL models are proposed to encode language-agnostic semantics. SAMU-XLSR framework employed this semantic information to enrich multilingual speech representations. A recent study investigated SAMU-XLSR in-domain semantic enrichment by specializing it on downstream transcriptions, leading to state-of-the-art results on a challenging SLU task. This study's interest lies in the loss of multilingual performances and lack of specific-semantics training induced by such specialization in close languages without any SLU implication. We also consider SAMU-XLSR's loss of initial cross-lingual abilities due to a separate SLU fine-tuning. Therefore, this paper proposes a dual task learning approach to improve SAMU-XLSR semantic enrichment while considering distant languages for multilingual and language portability experiments.
6/19/2024