Unlearnable Examples Detection via Iterative Filtering

0

Sign in to get full access
Overview
- The provided paper explores a method for detecting "unlearnable examples" - data points that are difficult or impossible for machine learning models to learn from.
- The key idea is to use an iterative filtering process to identify these unlearnable examples and remove them from the training data.
- The authors show that this approach can improve model performance on challenging datasets.
Plain English Explanation
The paper is about a technique to identify and remove "unlearnable examples" from machine learning datasets. These are data points that are particularly difficult or even impossible for AI models to learn from, often due to noise, ambiguity, or other issues in the data.
The core idea is to use an iterative filtering process to gradually identify and remove these troublesome examples from the training data. This helps the machine learning model focus on the more learnable portions of the dataset, potentially leading to better overall performance.
The authors demonstrate that this approach can be effective for improving model accuracy, especially on challenging datasets that contain a lot of "ungeneralizable examples" - data points that are hard for the model to generalize from.
Technical Explanation
The paper presents a method called "Unlearnable Examples Detection via Iterative Filtering" (UEDF). The key steps are:
- Train an initial machine learning model on the full dataset.
- Identify examples that the model struggles to correctly classify, indicating they may be "unlearnable."
- Remove these unlearnable examples from the training data.
- Retrain the model on the filtered dataset.
- Repeat steps 2-4 iteratively until convergence.
The authors test this approach on several benchmark datasets and show that it can lead to significant improvements in model performance compared to training on the full dataset. They also analyze the types of examples that are identified as unlearnable, providing insights into the nature of these challenging data points.
Critical Analysis
The paper provides a novel and promising approach for dealing with unlearnable examples in machine learning datasets. However, there are a few potential limitations and areas for further research:
- The iterative filtering process can be computationally intensive, especially for large datasets. More efficient techniques for identifying unlearnable examples may be needed for practical applications.
- The definition and identification of "unlearnable" examples is not always clear-cut, and may depend on the specific model, task, and dataset. Further work is needed to better characterize and detect these problematic data points.
- While the authors demonstrate improvements on benchmark datasets, it's unclear how well the UEDF method will generalize to real-world, noisy datasets encountered in practice. Validation on a wider range of applications would be valuable.
Overall, the UEDF approach represents an important step towards more robust and reliable machine learning systems. As AI models are increasingly deployed in high-stakes domains, techniques for identifying and mitigating unlearnable examples will become increasingly crucial.
Conclusion
The paper presents a novel method for detecting and removing "unlearnable examples" from machine learning datasets. By iteratively filtering out these problematic data points, the authors show that model performance can be significantly improved, especially on challenging datasets.
While the technique has some limitations and areas for further research, it represents an important contribution to the field of machine learning. As AI systems become more widely deployed, the ability to identify and handle unlearnable examples will be crucial for ensuring the reliability and robustness of these technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Unlearnable Examples Detection via Iterative Filtering
Yi Yu, Qichen Zheng, Siyuan Yang, Wenhan Yang, Jun Liu, Shijian Lu, Yap-Peng Tan, Kwok-Yan Lam, Alex Kot
Deep neural networks are proven to be vulnerable to data poisoning attacks. Recently, a specific type of data poisoning attack known as availability attacks has led to the failure of data utilization for model learning by adding imperceptible perturbations to images. Consequently, it is quite beneficial and challenging to detect poisoned samples, also known as Unlearnable Examples (UEs), from a mixed dataset. In response, we propose an Iterative Filtering approach for UEs identification. This method leverages the distinction between the inherent semantic mapping rules and shortcuts, without the need for any additional information. We verify that when training a classifier on a mixed dataset containing both UEs and clean data, the model tends to quickly adapt to the UEs compared to the clean data. Due to the accuracy gaps between training with clean/poisoned samples, we employ a model to misclassify clean samples while correctly identifying the poisoned ones. The incorporation of additional classes and iterative refinement enhances the model's ability to differentiate between clean and poisoned samples. Extensive experiments demonstrate the superiority of our method over state-of-the-art detection approaches across various attacks, datasets, and poison ratios, significantly reducing the Half Total Error Rate (HTER) compared to existing methods.
Read more8/16/2024
🔗
0
Provably Unlearnable Examples
Derui Wang, Minhui Xue, Bo Li, Seyit Camtepe, Liming Zhu
The exploitation of publicly accessible data has led to escalating concerns regarding data privacy and intellectual property (IP) breaches in the age of artificial intelligence. As a strategy to safeguard both data privacy and IP-related domain knowledge, efforts have been undertaken to render shared data unlearnable for unauthorized models in the wild. Existing methods apply empirically optimized perturbations to the data in the hope of disrupting the correlation between the inputs and the corresponding labels such that the data samples are converted into Unlearnable Examples (UEs). Nevertheless, the absence of mechanisms that can verify how robust the UEs are against unknown unauthorized models and train-time techniques engenders several problems. First, the empirically optimized perturbations may suffer from the problem of cross-model generalization, which echoes the fact that the unauthorized models are usually unknown to the defender. Second, UEs can be mitigated by train-time techniques such as data augmentation and adversarial training. Furthermore, we find that a simple recovery attack can restore the clean-task performance of the classifiers trained on UEs by slightly perturbing the learned weights. To mitigate the aforementioned problems, in this paper, we propose a mechanism for certifying the so-called $(q, eta)$-Learnability of an unlearnable dataset via parametric smoothing. A lower certified $(q, eta)$-Learnability indicates a more robust protection over the dataset. Finally, we try to 1) improve the tightness of certified $(q, eta)$-Learnability and 2) design Provably Unlearnable Examples (PUEs) which have reduced $(q, eta)$-Learnability. According to experimental results, PUEs demonstrate both decreased certified $(q, eta)$-Learnability and enhanced empirical robustness compared to existing UEs.
Read more5/7/2024
📈
0
Purify Unlearnable Examples via Rate-Constrained Variational Autoencoders
Yi Yu, Yufei Wang, Song Xia, Wenhan Yang, Shijian Lu, Yap-Peng Tan, Alex C. Kot
Unlearnable examples (UEs) seek to maximize testing error by making subtle modifications to training examples that are correctly labeled. Defenses against these poisoning attacks can be categorized based on whether specific interventions are adopted during training. The first approach is training-time defense, such as adversarial training, which can mitigate poisoning effects but is computationally intensive. The other approach is pre-training purification, e.g., image short squeezing, which consists of several simple compressions but often encounters challenges in dealing with various UEs. Our work provides a novel disentanglement mechanism to build an efficient pre-training purification method. Firstly, we uncover rate-constrained variational autoencoders (VAEs), demonstrating a clear tendency to suppress the perturbations in UEs. We subsequently conduct a theoretical analysis for this phenomenon. Building upon these insights, we introduce a disentangle variational autoencoder (D-VAE), capable of disentangling the perturbations with learnable class-wise embeddings. Based on this network, a two-stage purification approach is naturally developed. The first stage focuses on roughly eliminating perturbations, while the second stage produces refined, poison-free results, ensuring effectiveness and robustness across various scenarios. Extensive experiments demonstrate the remarkable performance of our method across CIFAR-10, CIFAR-100, and a 100-class ImageNet-subset. Code is available at https://github.com/yuyi-sd/D-VAE.
Read more5/7/2024
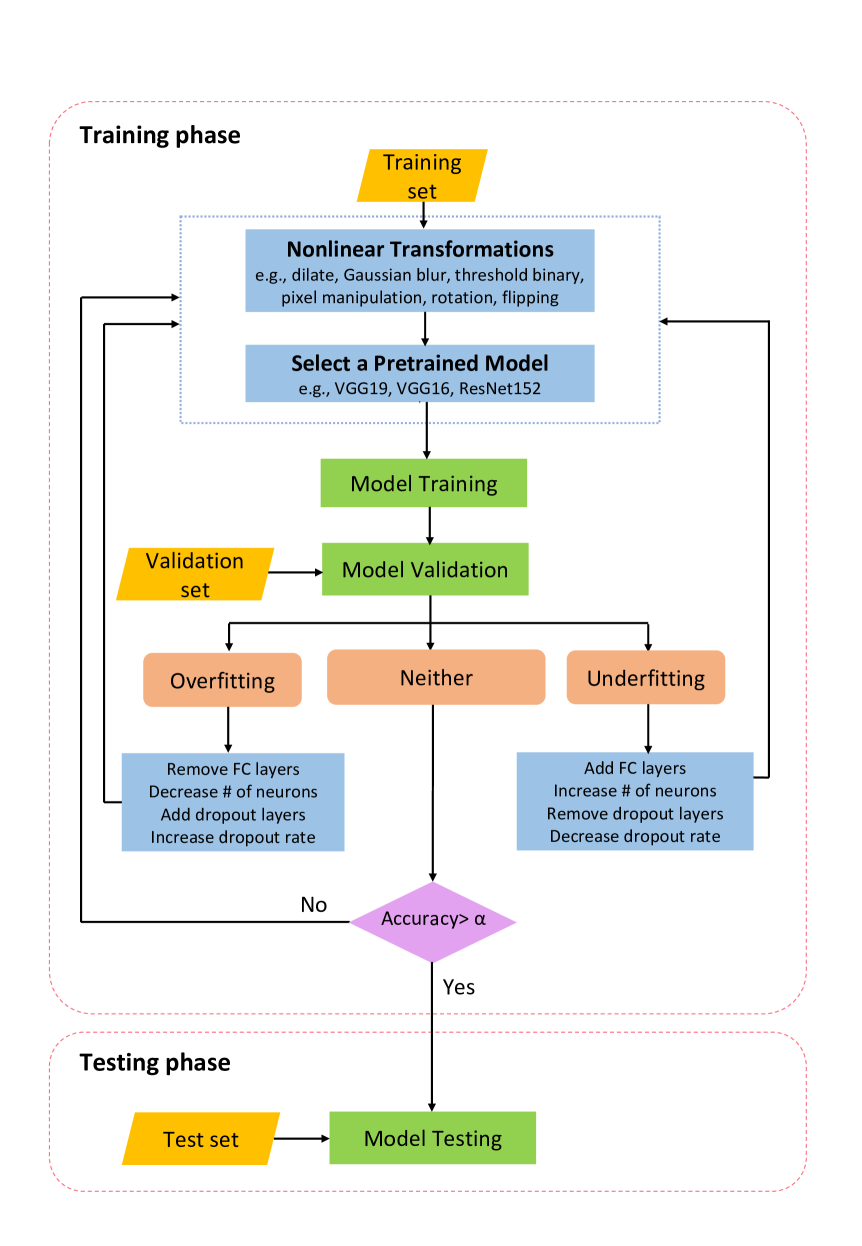
0
Nonlinear Transformations Against Unlearnable Datasets
Thushari Hapuarachchi, Jing Lin, Kaiqi Xiong, Mohamed Rahouti, Gitte Ost
Automated scraping stands out as a common method for collecting data in deep learning models without the authorization of data owners. Recent studies have begun to tackle the privacy concerns associated with this data collection method. Notable approaches include Deepconfuse, error-minimizing, error-maximizing (also known as adversarial poisoning), Neural Tangent Generalization Attack, synthetic, autoregressive, One-Pixel Shortcut, Self-Ensemble Protection, Entangled Features, Robust Error-Minimizing, Hypocritical, and TensorClog. The data generated by those approaches, called unlearnable examples, are prevented learning by deep learning models. In this research, we investigate and devise an effective nonlinear transformation framework and conduct extensive experiments to demonstrate that a deep neural network can effectively learn from the data/examples traditionally considered unlearnable produced by the above twelve approaches. The resulting approach improves the ability to break unlearnable data compared to the linear separable technique recently proposed by researchers. Specifically, our extensive experiments show that the improvement ranges from 0.34% to 249.59% for the unlearnable CIFAR10 datasets generated by those twelve data protection approaches, except for One-Pixel Shortcut. Moreover, the proposed framework achieves over 100% improvement of test accuracy for Autoregressive and REM approaches compared to the linear separable technique. Our findings suggest that these approaches are inadequate in preventing unauthorized uses of data in machine learning models. There is an urgent need to develop more robust protection mechanisms that effectively thwart an attacker from accessing data without proper authorization from the owners.
Read more6/6/2024