Unlearning Concepts from Text-to-Video Diffusion Models

0
Sign in to get full access
Overview
- The paper explores methods for unlearning specific concepts from text-to-video diffusion models.
- It investigates techniques to remove unwanted concepts from the model's learned representations without significantly degrading its performance.
- The proposed approach aims to mitigate issues like dataset bias and copyright infringement in text-to-video generation.
Plain English Explanation
Unlearning Concepts from Text-to-Video Diffusion Models
Diffusion models are a type of machine learning algorithm that can generate high-quality images and videos from text descriptions. However, these models can sometimes learn unwanted or biased concepts from the data they're trained on, which can lead to problems like generating content that infringes on copyrights or reflects societal biases.
This paper explores ways to remove specific concepts from the model's learned representations without significantly degrading its overall performance. The goal is to mitigate issues like dataset bias and copyright infringement in text-to-video generation.
The researchers propose a technique called concept unlearning, which involves identifying the specific concepts the model has learned and then actively removing them from the model's representations. This could help prevent the model from generating content that reflects certain biases or infringes on copyrights.
The paper also discusses ways to probe the model's unlearned representations and techniques for making the unlearning process more robust. Overall, the research explores important ways to make text-to-video diffusion models more reliable and ethical.
Technical Explanation
The paper presents a framework for unlearning concepts from text-to-video diffusion models. The key components are:
-
Concept Identification: The researchers first identify the specific concepts that the model has learned, such as particular objects, scenes, or actions.
-
Concept Unlearning: They then develop techniques to actively remove these concepts from the model's learned representations, without significantly degrading its overall performance on the target task.
-
Concept Probing: The paper also explores methods to probe the model's unlearned representations, ensuring that the unlearning process has been effective.
-
Robust Unlearning: Finally, the researchers investigate techniques for making the unlearning process more robust, such as through adversarial training.
The proposed approach aims to mitigate issues like dataset bias and copyright infringement in text-to-video generation by removing unwanted concepts from the model's learned representations.
Critical Analysis
The paper presents a novel and important approach for enhancing the reliability and ethical considerations of text-to-video diffusion models. By allowing researchers to unlearn specific concepts from the model's representations, the proposed framework could help address issues like dataset bias and copyright infringement.
However, the paper does not provide a comprehensive evaluation of the unlearning process, and it remains unclear how well the approach scales to a larger number of concepts or to more complex text-to-video models. Additionally, the paper does not address potential negative consequences of the unlearning process, such as the risk of accidentally removing important conceptual representations.
Further research is needed to explore the long-term implications of this approach and to develop more robust and reliable methods for controlling the conceptual knowledge acquired by text-to-video diffusion models.
Conclusion
This paper introduces a framework for unlearning concepts from text-to-video diffusion models, with the goal of mitigating issues like dataset bias and copyright infringement in the generated content. The proposed approach involves identifying specific concepts learned by the model, developing techniques to remove these concepts from the model's representations, and ensuring the unlearning process is effective and robust.
The research represents an important step towards enhancing the reliability and ethical considerations of text-to-video generation models, which have significant potential for a wide range of applications. However, further work is needed to fully understand the implications and limitations of the unlearning approach. As the field of text-to-video generation continues to advance, the ability to control the conceptual knowledge of these models will become increasingly critical.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Unlearning Concepts from Text-to-Video Diffusion Models
Shiqi Liu, Yihua Tan
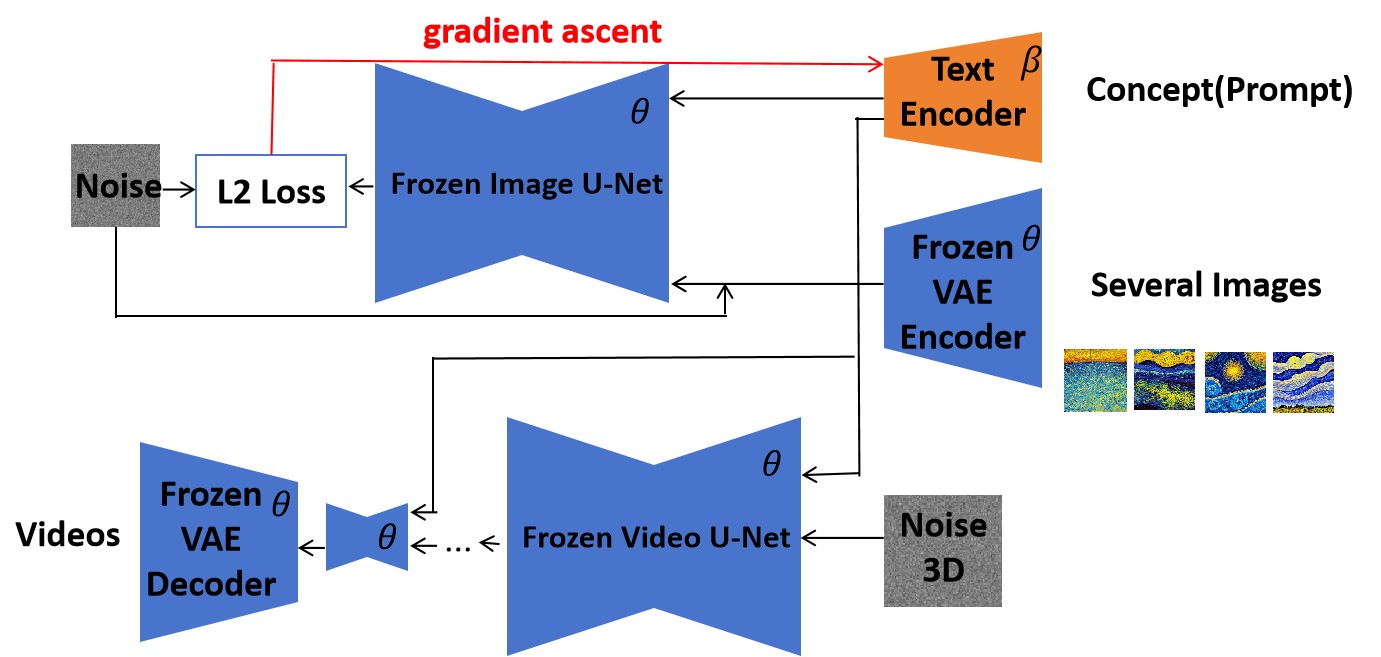
With the advancement of computer vision and natural language processing, text-to-video generation, enabled by text-to-video diffusion models, has become more prevalent. These models are trained using a large amount of data from the internet. However, the training data often contain copyrighted content, including cartoon character icons and artist styles, private portraits, and unsafe videos. Since filtering the data and retraining the model is challenging, methods for unlearning specific concepts from text-to-video diffusion models have been investigated. However, due to the high computational complexity and relative large optimization scale, there is little work on unlearning methods for text-to-video diffusion models. We propose a novel concept-unlearning method by transferring the unlearning capability of the text encoder of text-to-image diffusion models to text-to-video diffusion models. Specifically, the method optimizes the text encoder using few-shot unlearning, where several generated images are used. We then use the optimized text encoder in text-to-video diffusion models to generate videos. Our method costs low computation resources and has small optimization scale. We discuss the generated videos after unlearning a concept. The experiments demonstrates that our method can unlearn copyrighted cartoon characters, artist styles, objects and people's facial characteristics. Our method can unlearn a concept within about 100 seconds on an RTX 3070. Since there was no concept unlearning method for text-to-video diffusion models before, we make concept unlearning feasible and more accessible in the text-to-video domain.
Read more7/22/2024
📈
0
Erasing Concepts from Text-to-Image Diffusion Models with Few-shot Unlearning
Masane Fuchi, Tomohiro Takagi
Generating images from text has become easier because of the scaling of diffusion models and advancements in the field of vision and language. These models are trained using vast amounts of data from the Internet. Hence, they often contain undesirable content such as copyrighted material. As it is challenging to remove such data and retrain the models, methods for erasing specific concepts from pre-trained models have been investigated. We propose a novel concept-erasure method that updates the text encoder using few-shot unlearning in which a few real images are used. The discussion regarding the generated images after erasing a concept has been lacking. While there are methods for specifying the transition destination for concepts, the validity of the specified concepts is unclear. Our method implicitly achieves this by transitioning to the latent concepts inherent in the model or the images. Our method can erase a concept within 10 s, making concept erasure more accessible than ever before. Implicitly transitioning to related concepts leads to more natural concept erasure. We applied the proposed method to various concepts and confirmed that concept erasure can be achieved tens to hundreds of times faster than with current methods. By varying the parameters to be updated, we obtained results suggesting that, like previous research, knowledge is primarily accumulated in the feed-forward networks of the text encoder. Our code is available at url{https://github.com/fmp453/few-shot-erasing}
Read more8/30/2024

0
A Dataset and Benchmark for Copyright Infringement Unlearning from Text-to-Image Diffusion Models
Rui Ma, Qiang Zhou, Yizhu Jin, Daquan Zhou, Bangjun Xiao, Xiuyu Li, Yi Qu, Aishani Singh, Kurt Keutzer, Jingtong Hu, Xiaodong Xie, Zhen Dong, Shanghang Zhang, Shiji Zhou
Copyright law confers upon creators the exclusive rights to reproduce, distribute, and monetize their creative works. However, recent progress in text-to-image generation has introduced formidable challenges to copyright enforcement. These technologies enable the unauthorized learning and replication of copyrighted content, artistic creations, and likenesses, leading to the proliferation of unregulated content. Notably, models like stable diffusion, which excel in text-to-image synthesis, heighten the risk of copyright infringement and unauthorized distribution.Machine unlearning, which seeks to eradicate the influence of specific data or concepts from machine learning models, emerges as a promising solution by eliminating the enquote{copyright memories} ingrained in diffusion models. Yet, the absence of comprehensive large-scale datasets and standardized benchmarks for evaluating the efficacy of unlearning techniques in the copyright protection scenarios impedes the development of more effective unlearning methods. To address this gap, we introduce a novel pipeline that harmonizes CLIP, ChatGPT, and diffusion models to curate a dataset. This dataset encompasses anchor images, associated prompts, and images synthesized by text-to-image models. Additionally, we have developed a mixed metric based on semantic and style information, validated through both human and artist assessments, to gauge the effectiveness of unlearning approaches. Our dataset, benchmark library, and evaluation metrics will be made publicly available to foster future research and practical applications (https://rmpku.github.io/CPDM-page/, website / http://149.104.22.83/unlearning.tar.gz, dataset).
Read more6/24/2024
📈
0
Unlearning Concepts in Diffusion Model via Concept Domain Correction and Concept Preserving Gradient
Yongliang Wu, Shiji Zhou, Mingzhuo Yang, Lianzhe Wang, Wenbo Zhu, Heng Chang, Xiao Zhou, Xu Yang
Current text-to-image diffusion models have achieved groundbreaking results in image generation tasks. However, the unavoidable inclusion of sensitive information during pre-training introduces significant risks such as copyright infringement and privacy violations in the generated images. Machine Unlearning (MU) provides a effective way to the sensitive concepts captured by the model, has been shown to be a promising approach to addressing these issues. Nonetheless, existing MU methods for concept erasure encounter two primary bottlenecks: 1) generalization issues, where concept erasure is effective only for the data within the unlearn set, and prompts outside the unlearn set often still result in the generation of sensitive concepts; and 2) utility drop, where erasing target concepts significantly degrades the model's performance. To this end, this paper first proposes a concept domain correction framework for unlearning concepts in diffusion models. By aligning the output domains of sensitive concepts and anchor concepts through adversarial training, we enhance the generalizability of the unlearning results. Secondly, we devise a concept-preserving scheme based on gradient surgery. This approach alleviates the parts of the unlearning gradient that contradict the relearning gradient, ensuring that the process of unlearning minimally disrupts the model's performance. Finally, extensive experiments validate the effectiveness of our model, demonstrating our method's capability to address the challenges of concept unlearning in diffusion models while preserving model utility.
Read more5/27/2024