Unlearning Concepts in Diffusion Model via Concept Domain Correction and Concept Preserving Gradient

0
📈
Sign in to get full access
Overview
- This paper introduces a new technique called "concept erasure" that allows text-to-image diffusion models to remove specific concepts from the generated images.
- The authors also present several related techniques, such as "defensive unlearning" to make models more robust against adversarial attacks targeting concept erasure.
- The paper explores the implications of these methods for both beneficial and potentially harmful applications, highlighting the need for careful consideration of the ethical implications.
Plain English Explanation
The paper describes ways to modify AI models that generate images from text, allowing them to remove or "erase" certain concepts or ideas from the generated images. For example, an AI model could be trained to remove depictions of violence or certain political symbols from its image outputs.
The researchers developed a few different techniques to achieve this concept erasure. One method, called "defensive unlearning," trains the model to be more resistant to attempts to manipulate it and force it to remove specific concepts. Another technique, "probing unlearned diffusion models," looks at how an adversary could potentially attack the model and find ways to exploit its weaknesses.
The paper argues that these concept erasure capabilities could have both beneficial and concerning applications. On the positive side, they could allow AI systems to generate more inclusive and appropriate content. However, the authors also caution that the techniques could be misused to censor or manipulate information. The paper emphasizes the importance of carefully considering the ethical implications as this technology continues to develop.
Technical Explanation
The paper proposes a framework for "concept erasure" in text-to-image diffusion models, which allows these models to remove specific concepts or ideas from the generated images. The authors introduce several related techniques:
- Defensive Unlearning: A method to train diffusion models to be more robust against adversarial attacks targeting concept erasure.
- Probing Unlearned Diffusion Models: Techniques to identify and exploit weaknesses in diffusion models that may allow an adversary to force concept erasure.
- Non-Confusing Generation: A method to customize the set of concepts that a diffusion model can erase, avoiding unintended or confusing results.
- Class-Machine Unlearning: An approach to selectively "unlearn" specific concepts from a diffusion model while preserving its overall performance.
The paper evaluates these techniques through a series of experiments, demonstrating their effectiveness in erasing targeted concepts from generated images while maintaining the model's overall performance. The authors also discuss the potential implications, both beneficial and concerning, of these concept erasure capabilities.
Critical Analysis
The paper raises important points about the potential applications and ethical considerations of concept erasure capabilities in text-to-image diffusion models. While the techniques could be used to create more inclusive and appropriate content, the authors rightly caution that the same methods could also be used for harmful censorship or manipulation.
One limitation is that the paper focuses primarily on the technical implementation of concept erasure, without a deep exploration of the broader societal impacts. The authors acknowledge this, stating that "a comprehensive study of the implications of concept erasure is an important direction for future work."
Additionally, the paper does not address potential biases or limitations in the datasets and models used, which could lead to unintended consequences or reinforce existing societal biases. Further research is needed to understand how these techniques may interact with and potentially amplify such biases.
Overall, the paper makes a valuable contribution by introducing the concept of concept erasure and highlighting the need for careful consideration of the ethical implications as this technology continues to evolve. Readers are encouraged to think critically about the research and form their own opinions on the appropriate use of these techniques.
Conclusion
This paper presents a novel framework for "concept erasure" in text-to-image diffusion models, allowing these AI systems to remove specific concepts or ideas from the generated images. The authors introduce several related techniques, such as defensive unlearning and probing unlearned diffusion models, to enhance the robustness and control of these concept erasure capabilities.
The paper emphasizes the potential for both beneficial and concerning applications of these methods, underscoring the need to carefully consider the ethical implications as the technology develops. While concept erasure could enable the creation of more inclusive and appropriate content, the same techniques could also be misused for harmful censorship or manipulation.
As AI-generated content becomes more prevalent, the issues raised in this paper will only become more pressing. Ongoing research and public discourse will be crucial to ensure these powerful technologies are developed and deployed responsibly, with a focus on promoting the common good and safeguarding fundamental rights and freedoms.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
Unlearning Concepts in Diffusion Model via Concept Domain Correction and Concept Preserving Gradient
Yongliang Wu, Shiji Zhou, Mingzhuo Yang, Lianzhe Wang, Wenbo Zhu, Heng Chang, Xiao Zhou, Xu Yang
Current text-to-image diffusion models have achieved groundbreaking results in image generation tasks. However, the unavoidable inclusion of sensitive information during pre-training introduces significant risks such as copyright infringement and privacy violations in the generated images. Machine Unlearning (MU) provides a effective way to the sensitive concepts captured by the model, has been shown to be a promising approach to addressing these issues. Nonetheless, existing MU methods for concept erasure encounter two primary bottlenecks: 1) generalization issues, where concept erasure is effective only for the data within the unlearn set, and prompts outside the unlearn set often still result in the generation of sensitive concepts; and 2) utility drop, where erasing target concepts significantly degrades the model's performance. To this end, this paper first proposes a concept domain correction framework for unlearning concepts in diffusion models. By aligning the output domains of sensitive concepts and anchor concepts through adversarial training, we enhance the generalizability of the unlearning results. Secondly, we devise a concept-preserving scheme based on gradient surgery. This approach alleviates the parts of the unlearning gradient that contradict the relearning gradient, ensuring that the process of unlearning minimally disrupts the model's performance. Finally, extensive experiments validate the effectiveness of our model, demonstrating our method's capability to address the challenges of concept unlearning in diffusion models while preserving model utility.
Read more5/27/2024
📈
0
Erasing Concepts from Text-to-Image Diffusion Models with Few-shot Unlearning
Masane Fuchi, Tomohiro Takagi
Generating images from text has become easier because of the scaling of diffusion models and advancements in the field of vision and language. These models are trained using vast amounts of data from the Internet. Hence, they often contain undesirable content such as copyrighted material. As it is challenging to remove such data and retrain the models, methods for erasing specific concepts from pre-trained models have been investigated. We propose a novel concept-erasure method that updates the text encoder using few-shot unlearning in which a few real images are used. The discussion regarding the generated images after erasing a concept has been lacking. While there are methods for specifying the transition destination for concepts, the validity of the specified concepts is unclear. Our method implicitly achieves this by transitioning to the latent concepts inherent in the model or the images. Our method can erase a concept within 10 s, making concept erasure more accessible than ever before. Implicitly transitioning to related concepts leads to more natural concept erasure. We applied the proposed method to various concepts and confirmed that concept erasure can be achieved tens to hundreds of times faster than with current methods. By varying the parameters to be updated, we obtained results suggesting that, like previous research, knowledge is primarily accumulated in the feed-forward networks of the text encoder. Our code is available at url{https://github.com/fmp453/few-shot-erasing}
Read more8/30/2024
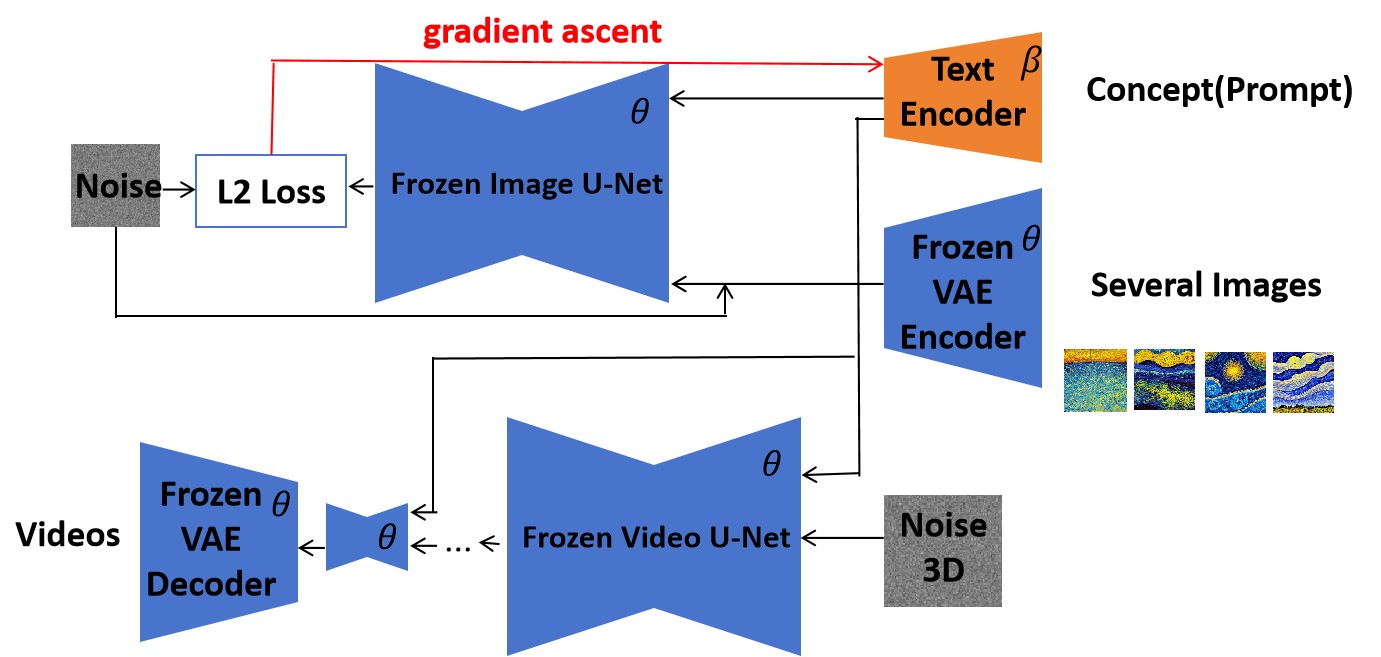
0
Unlearning Concepts from Text-to-Video Diffusion Models
Shiqi Liu, Yihua Tan
With the advancement of computer vision and natural language processing, text-to-video generation, enabled by text-to-video diffusion models, has become more prevalent. These models are trained using a large amount of data from the internet. However, the training data often contain copyrighted content, including cartoon character icons and artist styles, private portraits, and unsafe videos. Since filtering the data and retraining the model is challenging, methods for unlearning specific concepts from text-to-video diffusion models have been investigated. However, due to the high computational complexity and relative large optimization scale, there is little work on unlearning methods for text-to-video diffusion models. We propose a novel concept-unlearning method by transferring the unlearning capability of the text encoder of text-to-image diffusion models to text-to-video diffusion models. Specifically, the method optimizes the text encoder using few-shot unlearning, where several generated images are used. We then use the optimized text encoder in text-to-video diffusion models to generate videos. Our method costs low computation resources and has small optimization scale. We discuss the generated videos after unlearning a concept. The experiments demonstrates that our method can unlearn copyrighted cartoon characters, artist styles, objects and people's facial characteristics. Our method can unlearn a concept within about 100 seconds on an RTX 3070. Since there was no concept unlearning method for text-to-video diffusion models before, we make concept unlearning feasible and more accessible in the text-to-video domain.
Read more7/22/2024

0
ConceptPrune: Concept Editing in Diffusion Models via Skilled Neuron Pruning
Ruchika Chavhan, Da Li, Timothy Hospedales
While large-scale text-to-image diffusion models have demonstrated impressive image-generation capabilities, there are significant concerns about their potential misuse for generating unsafe content, violating copyright, and perpetuating societal biases. Recently, the text-to-image generation community has begun addressing these concerns by editing or unlearning undesired concepts from pre-trained models. However, these methods often involve data-intensive and inefficient fine-tuning or utilize various forms of token remapping, rendering them susceptible to adversarial jailbreaks. In this paper, we present a simple and effective training-free approach, ConceptPrune, wherein we first identify critical regions within pre-trained models responsible for generating undesirable concepts, thereby facilitating straightforward concept unlearning via weight pruning. Experiments across a range of concepts including artistic styles, nudity, object erasure, and gender debiasing demonstrate that target concepts can be efficiently erased by pruning a tiny fraction, approximately 0.12% of total weights, enabling multi-concept erasure and robustness against various white-box and black-box adversarial attacks.
Read more5/30/2024