CLIP with Quality Captions: A Strong Pretraining for Vision Tasks
2405.08911
0
0

Abstract
CLIP models perform remarkably well on zero-shot classification and retrieval tasks. But recent studies have shown that learnt representations in CLIP are not well suited for dense prediction tasks like object detection, semantic segmentation or depth estimation. More recently, multi-stage training methods for CLIP models was introduced to mitigate the weak performance of CLIP on downstream tasks. In this work, we find that simply improving the quality of captions in image-text datasets improves the quality of CLIP's visual representations, resulting in significant improvement on downstream dense prediction vision tasks. In fact, we find that CLIP pretraining with good quality captions can surpass recent supervised, self-supervised and weakly supervised pretraining methods. We show that when CLIP model with ViT-B/16 as image encoder is trained on well aligned image-text pairs it obtains 12.1% higher mIoU and 11.5% lower RMSE on semantic segmentation and depth estimation tasks over recent state-of-the-art Masked Image Modeling (MIM) pretraining methods like Masked Autoencoder (MAE). We find that mobile architectures also benefit significantly from CLIP pretraining. A recent mobile vision architecture, MCi2, with CLIP pretraining obtains similar performance as Swin-L, pretrained on ImageNet-22k for semantic segmentation task while being 6.1$times$ smaller. Moreover, we show that improving caption quality results in $10times$ data efficiency when finetuning for dense prediction tasks.
Create account to get full access
Overview
- This paper introduces CLIP with Quality Captions (CQC), a novel approach to pretraining vision-language models that leverages high-quality image captions to improve performance on a variety of visual tasks.
- CQC builds upon the foundational CLIP model, which excels at learning robust visual representations through contrastive pretraining on image-text pairs.
- The key innovation in CQC is the use of high-quality captions, rather than the web-scraped captions typically used in CLIP pretraining, to further enhance the model's visual understanding.
- The authors demonstrate that CQC outperforms CLIP on a range of vision tasks, including image classification, object detection, and few-shot recognition, highlighting the benefits of using higher-quality textual supervision during pretraining.
Plain English Explanation
The paper presents a new way to train vision-language models, which are AI systems that can understand and work with both images and text. These models are very useful for a wide range of applications, from image recognition to language generation.
The key insight of this work is that the quality of the text data used to train these models matters a lot. Typically, vision-language models are trained on image-text pairs scraped from the internet, which can be noisy and of variable quality.
CQC takes a different approach by using high-quality captions - descriptions of images that are carefully written by humans. The authors show that training on these high-quality captions leads to vision-language models that perform better on a wide range of tasks, like classifying objects in images or recognizing objects in new images that the model hasn't seen before.
This work builds on the success of the CLIP model, which was a breakthrough in vision-language pretraining. CQC takes CLIP's core approach and enhances it by using better-quality text data, resulting in even more powerful and versatile vision-language models.
Technical Explanation
The key technical contribution of this paper is the CQC pretraining approach, which builds upon the successful CLIP framework. CLIP CLIP is a vision-language model that is pretrained on a large corpus of image-text pairs scraped from the internet, enabling it to learn robust visual representations that are aligned with natural language.
CQC takes this a step further by using high-quality captions, rather than the noisy web-scraped captions typically used in CLIP pretraining. These captions are carefully written by humans to accurately and comprehensively describe the contents of images. The authors hypothesize that this higher-quality textual supervision will lead to vision-language models with enhanced visual understanding.
To validate this hypothesis, the authors conduct extensive experiments comparing the performance of CQC and CLIP on a variety of visual tasks, including image classification, object detection, and few-shot recognition. The results demonstrate that CQC consistently outperforms CLIP, highlighting the benefits of using high-quality captions during pretraining.
The authors also provide insights into the properties of the CLIP dataset and the challenges of detecting AI-generated images, which are relevant to the broader development of robust vision-language models.
Critical Analysis
The CQC approach presented in this paper represents a significant advancement in vision-language pretraining, demonstrating the value of using high-quality textual supervision to enhance the visual understanding of these models. However, the authors acknowledge several limitations and areas for further research.
One key limitation is the reliance on manually-curated captions, which may not be scalable to the same extent as the web-scraped data typically used in CLIP pretraining. The authors discuss the potential for semi-automated or automated approaches to generating high-quality captions, which could help address this scalability challenge.
Additionally, the paper does not delve deeply into the specific mechanisms by which the high-quality captions improve CQC's performance relative to CLIP. Further analysis of the learned representations and the model's behavior on different types of visual tasks could provide additional insights into the underlying reasons for CQC's superior performance.
Lastly, the authors note that CQC, like CLIP, may still exhibit biases and limitations inherent in the pretraining data and methodology. Exploring ways to mitigate these biases and ensure the fairness and robustness of vision-language models remains an important area for future research.
Conclusion
This paper presents a novel approach to vision-language pretraining, CQC, that leverages high-quality image captions to enhance the visual understanding of the resulting models. The authors demonstrate that CQC outperforms the foundational CLIP model on a range of visual tasks, highlighting the benefits of using higher-quality textual supervision during pretraining.
The CQC framework represents a significant step forward in the development of robust and versatile vision-language models, with potential applications across a wide range of domains, from image recognition to multimodal content generation. As the field of AI continues to advance, the insights and techniques presented in this paper are likely to have a lasting impact on the future of vision-language modeling and its real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
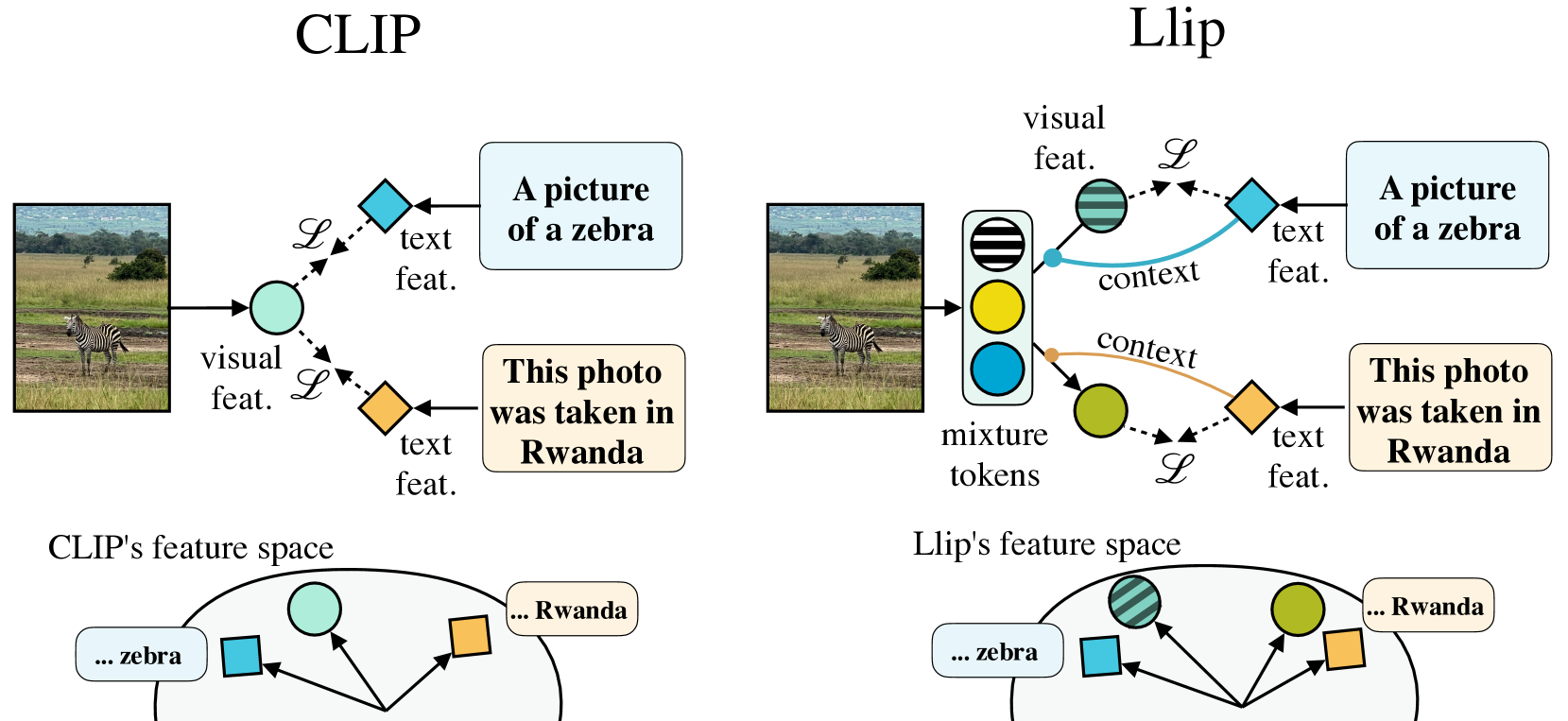
Modeling Caption Diversity in Contrastive Vision-Language Pretraining
Samuel Lavoie, Polina Kirichenko, Mark Ibrahim, Mahmoud Assran, Andrew Gordon Wilson, Aaron Courville, Nicolas Ballas
0
0
There are a thousand ways to caption an image. Contrastive Language Pretraining (CLIP) on the other hand, works by mapping an image and its caption to a single vector -- limiting how well CLIP-like models can represent the diverse ways to describe an image. In this work, we introduce Llip, Latent Language Image Pretraining, which models the diversity of captions that could match an image. Llip's vision encoder outputs a set of visual features that are mixed into a final representation by conditioning on information derived from the text. We show that Llip outperforms non-contextualized baselines like CLIP and SigLIP on a variety of tasks even with large-scale encoders. Llip improves zero-shot classification by an average of 2.9% zero-shot classification benchmarks with a ViT-G/14 encoder. Specifically, Llip attains a zero-shot top-1 accuracy of 83.5% on ImageNet outperforming a similarly sized CLIP by 1.4%. We also demonstrate improvement on zero-shot retrieval on MS-COCO by 6.0%. We provide a comprehensive analysis of the components introduced by the method and demonstrate that Llip leads to richer visual representations.
5/15/2024
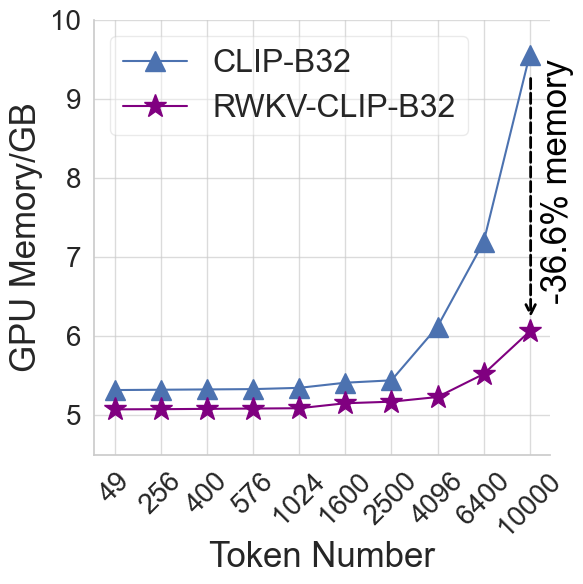
RWKV-CLIP: A Robust Vision-Language Representation Learner
Tiancheng Gu, Kaicheng Yang, Xiang An, Ziyong Feng, Dongnan Liu, Weidong Cai, Jiankang Deng
0
0
Contrastive Language-Image Pre-training (CLIP) has significantly improved performance in various vision-language tasks by expanding the dataset with image-text pairs obtained from websites. This paper further explores CLIP from the perspectives of data and model architecture. To address the prevalence of noisy data and enhance the quality of large-scale image-text data crawled from the internet, we introduce a diverse description generation framework that can leverage Large Language Models (LLMs) to synthesize and refine content from web-based texts, synthetic captions, and detection tags. Furthermore, we propose RWKV-CLIP, the first RWKV-driven vision-language representation learning model that combines the effective parallel training of transformers with the efficient inference of RNNs. Comprehensive experiments across various model scales and pre-training datasets demonstrate that RWKV-CLIP is a robust and efficient vision-language representation learner, it achieves state-of-the-art performance in several downstream tasks, including linear probe, zero-shot classification, and zero-shot image-text retrieval. To facilitate future research, the code and pre-trained models are released at https://github.com/deepglint/RWKV-CLIP
6/12/2024

RankCLIP: Ranking-Consistent Language-Image Pretraining
Yiming Zhang, Zhuokai Zhao, Zhaorun Chen, Zhili Feng, Zenghui Ding, Yining Sun
0
0
Self-supervised contrastive learning models, such as CLIP, have set new benchmarks for vision-language models in many downstream tasks. However, their dependency on rigid one-to-one mappings overlooks the complex and often multifaceted relationships between and within texts and images. To this end, we introduce RANKCLIP, a novel pretraining method that extends beyond the rigid one-to-one matching framework of CLIP and its variants. By extending the traditional pair-wise loss to list-wise, and leveraging both in-modal and cross-modal ranking consistency, RANKCLIP improves the alignment process, enabling it to capture the nuanced many-to-many relationships between and within each modality. Through comprehensive experiments, we demonstrate the effectiveness of RANKCLIP in various downstream tasks, notably achieving significant gains in zero-shot classifications over state-of-the-art methods, underscoring the importance of this enhanced learning process.
6/21/2024

Updating CLIP to Prefer Descriptions Over Captions
Amir Zur, Elisa Kreiss, Karel D'Oosterlinck, Christopher Potts, Atticus Geiger
0
0
Although CLIPScore is a powerful generic metric that captures the similarity between a text and an image, it fails to distinguish between a caption that is meant to complement the information in an image and a description that is meant to replace an image entirely, e.g., for accessibility. We address this shortcoming by updating the CLIP model with the Concadia dataset to assign higher scores to descriptions than captions using parameter efficient fine-tuning and a loss objective derived from work on causal interpretability. This model correlates with the judgements of blind and low-vision people while preserving transfer capabilities and has interpretable structure that sheds light on the caption--description distinction.
6/17/2024