Dual-Image Enhanced CLIP for Zero-Shot Anomaly Detection
2405.04782
0
0
Abstract
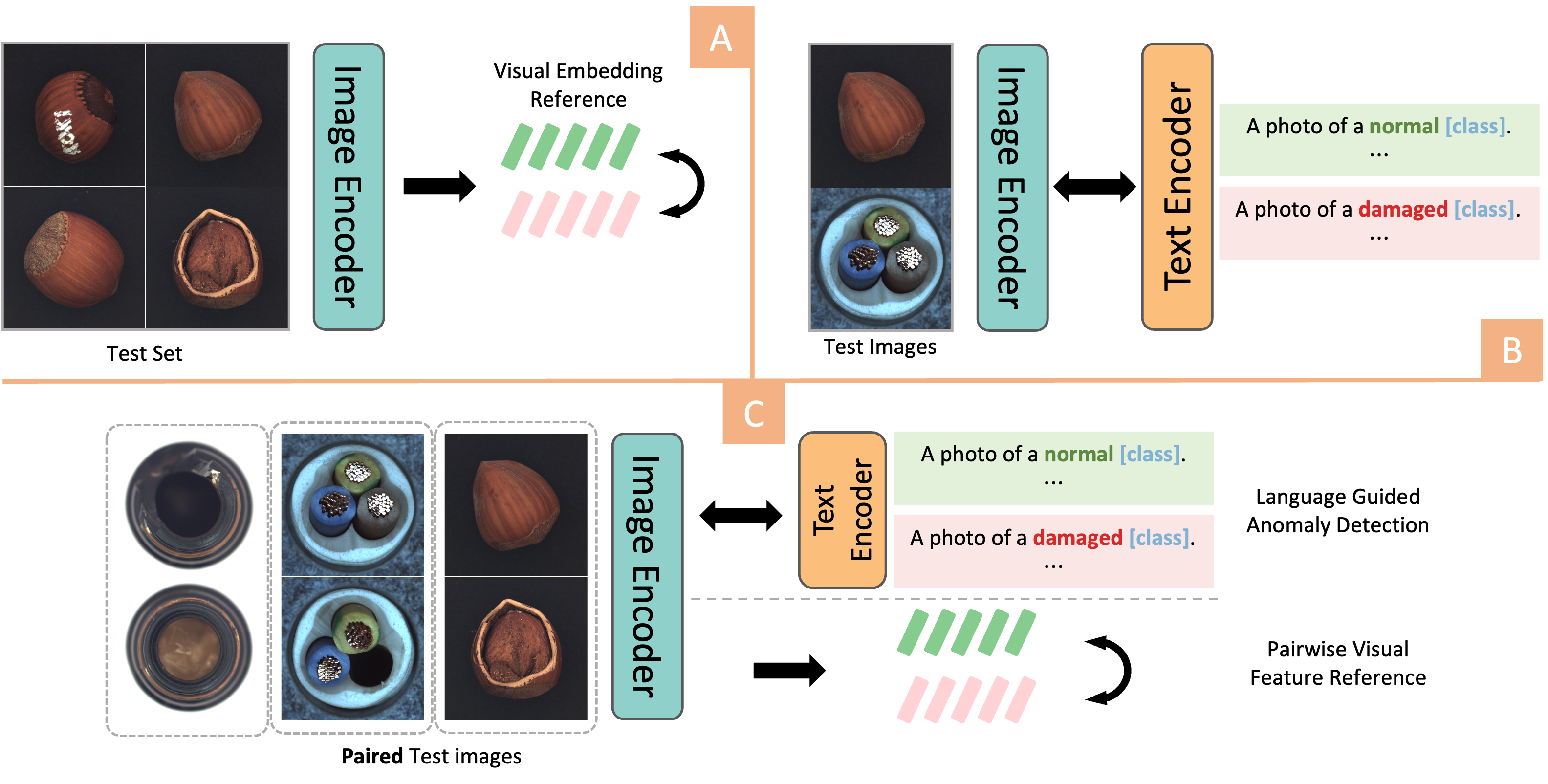
Image Anomaly Detection has been a challenging task in Computer Vision field. The advent of Vision-Language models, particularly the rise of CLIP-based frameworks, has opened new avenues for zero-shot anomaly detection. Recent studies have explored the use of CLIP by aligning images with normal and prompt descriptions. However, the exclusive dependence on textual guidance often falls short, highlighting the critical importance of additional visual references. In this work, we introduce a Dual-Image Enhanced CLIP approach, leveraging a joint vision-language scoring system. Our methods process pairs of images, utilizing each as a visual reference for the other, thereby enriching the inference process with visual context. This dual-image strategy markedly enhanced both anomaly classification and localization performances. Furthermore, we have strengthened our model with a test-time adaptation module that incorporates synthesized anomalies to refine localization capabilities. Our approach significantly exploits the potential of vision-language joint anomaly detection and demonstrates comparable performance with current SOTA methods across various datasets.
Create account to get full access
Overview
- Proposes a novel "Dual-Image Enhanced CLIP" model for zero-shot anomaly detection
- Leverages the strengths of CLIP (Contrastive Language-Image Pre-training) to detect anomalies in images without any labeled training data
- Enhances the CLIP model by incorporating a "dual-image" input, where the model learns to compare a target image against a normal reference image
- Achieves state-of-the-art performance on several anomaly detection benchmarks
Plain English Explanation
"Dual-Image Enhanced CLIP" is a new AI model that can detect unusual or anomalous things in images, without being trained on labeled examples of those anomalies. It works by comparing the target image to a "normal" reference image, and looking for differences that might indicate something out of the ordinary.
This is a useful capability because in many real-world scenarios, we don't have access to labeled datasets of all the possible anomalies we might want to detect. The RankCLIP model and the Raising the Bar for AI-Generated Image Detection with CLIP work have shown the power of CLIP, a pre-trained model that can understand the relationship between images and text. The researchers here build on CLIP's capabilities by having it compare two images - the target and the reference - to spot differences that could signal an anomaly.
This "dual-image" approach allows the model to learn what "normal" looks like, and then identify things that deviate from that. The authors show this method outperforms previous anomaly detection techniques on several benchmark datasets, making it a promising tool for real-world applications like medical imaging, manufacturing inspection, and security monitoring.
Technical Explanation
The key innovation in this work is the "Dual-Image Enhanced CLIP" (DICE-CLIP) model, which extends the original CLIP architecture to handle a pair of input images rather than a single image.
In the standard CLIP setup, the model is trained on a large dataset of image-text pairs to learn a joint embedding space where visually similar images and semantically related text are mapped close together. DICE-CLIP builds on this by taking two images as input - the target image that may contain an anomaly, and a "normal" reference image.
The model then computes two separate CLIP embeddings, one for each input image. It then compares these two embeddings to identify significant differences, which are interpreted as potential anomalies in the target image. This dual-image formulation allows the model to learn what "normal" looks like, and then recognize deviations from that baseline.
The authors evaluate DICE-CLIP on several standard anomaly detection benchmarks, including MVTec AD, CIFAR-10-C, and ImageNet-C. Across these datasets, they demonstrate state-of-the-art performance compared to prior zero-shot and few-shot anomaly detection methods. This suggests the dual-image approach is an effective way to leverage the powerful visual understanding capabilities of CLIP for the anomaly detection task.
Critical Analysis
One key limitation of the DICE-CLIP approach is that it requires access to a "normal" reference image during inference, which may not always be available in real-world scenarios. The authors acknowledge this and suggest using test-time augmentation (TTA) techniques to generate synthetic normal reference images when needed.
Additionally, while DICE-CLIP outperforms prior methods on the evaluated benchmarks, the overall anomaly detection performance is still far from perfect. There is likely room for further improvements, such as incorporating more advanced techniques for comparing the two CLIP embeddings or leveraging additional unsupervised anomaly cues beyond just the image-text alignment.
It would also be valuable to see the DICE-CLIP model evaluated on a wider range of real-world anomaly detection tasks, beyond just the standard academic benchmarks. Demonstrating its effectiveness in practical settings like vision-language foundation models for remote sensing or enhancing gaze estimation would further validate the approach.
Conclusion
The "Dual-Image Enhanced CLIP" (DICE-CLIP) model proposed in this paper represents an interesting advancement in zero-shot anomaly detection. By leveraging the strengths of the CLIP architecture and incorporating a dual-image input format, the authors have developed a method that can identify anomalies in images without any labeled training data.
The strong empirical results on standard benchmarks suggest DICE-CLIP is a promising approach, with potential applications in areas like medical imaging, industrial inspection, and security monitoring. While the technique has some limitations, this work demonstrates the power of combining pre-trained vision-language models like CLIP with specialized architectural innovations to tackle challenging computer vision problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

MediCLIP: Adapting CLIP for Few-shot Medical Image Anomaly Detection
Ximiao Zhang, Min Xu, Dehui Qiu, Ruixin Yan, Ning Lang, Xiuzhuang Zhou
0
0
In the field of medical decision-making, precise anomaly detection in medical imaging plays a pivotal role in aiding clinicians. However, previous work is reliant on large-scale datasets for training anomaly detection models, which increases the development cost. This paper first focuses on the task of medical image anomaly detection in the few-shot setting, which is critically significant for the medical field where data collection and annotation are both very expensive. We propose an innovative approach, MediCLIP, which adapts the CLIP model to few-shot medical image anomaly detection through self-supervised fine-tuning. Although CLIP, as a vision-language model, demonstrates outstanding zero-/fewshot performance on various downstream tasks, it still falls short in the anomaly detection of medical images. To address this, we design a series of medical image anomaly synthesis tasks to simulate common disease patterns in medical imaging, transferring the powerful generalization capabilities of CLIP to the task of medical image anomaly detection. When only few-shot normal medical images are provided, MediCLIP achieves state-of-the-art performance in anomaly detection and location compared to other methods. Extensive experiments on three distinct medical anomaly detection tasks have demonstrated the superiority of our approach. The code is available at https://github.com/cnulab/MediCLIP.
5/21/2024
🛸
Cascade-CLIP: Cascaded Vision-Language Embeddings Alignment for Zero-Shot Semantic Segmentation
Yunheng Li, ZhongYu Li, Quansheng Zeng, Qibin Hou, Ming-Ming Cheng
0
0
Pre-trained vision-language models, e.g., CLIP, have been successfully applied to zero-shot semantic segmentation. Existing CLIP-based approaches primarily utilize visual features from the last layer to align with text embeddings, while they neglect the crucial information in intermediate layers that contain rich object details. However, we find that directly aggregating the multi-level visual features weakens the zero-shot ability for novel classes. The large differences between the visual features from different layers make these features hard to align well with the text embeddings. We resolve this problem by introducing a series of independent decoders to align the multi-level visual features with the text embeddings in a cascaded way, forming a novel but simple framework named Cascade-CLIP. Our Cascade-CLIP is flexible and can be easily applied to existing zero-shot semantic segmentation methods. Experimental results show that our simple Cascade-CLIP achieves superior zero-shot performance on segmentation benchmarks, like COCO-Stuff, Pascal-VOC, and Pascal-Context. Our code is available at: https://github.com/HVision-NKU/Cascade-CLIP
6/7/2024

RankCLIP: Ranking-Consistent Language-Image Pretraining
Yiming Zhang, Zhuokai Zhao, Zhaorun Chen, Zhili Feng, Zenghui Ding, Yining Sun
0
0
Self-supervised contrastive learning models, such as CLIP, have set new benchmarks for vision-language models in many downstream tasks. However, their dependency on rigid one-to-one mappings overlooks the complex and often multifaceted relationships between and within texts and images. To this end, we introduce RANKCLIP, a novel pretraining method that extends beyond the rigid one-to-one matching framework of CLIP and its variants. By extending the traditional pair-wise loss to list-wise, and leveraging both in-modal and cross-modal ranking consistency, RANKCLIP improves the alignment process, enabling it to capture the nuanced many-to-many relationships between and within each modality. Through comprehensive experiments, we demonstrate the effectiveness of RANKCLIP in various downstream tasks, notably achieving significant gains in zero-shot classifications over state-of-the-art methods, underscoring the importance of this enhanced learning process.
6/21/2024
Raising the Bar of AI-generated Image Detection with CLIP
Davide Cozzolino, Giovanni Poggi, Riccardo Corvi, Matthias Nie{ss}ner, Luisa Verdoliva
0
0
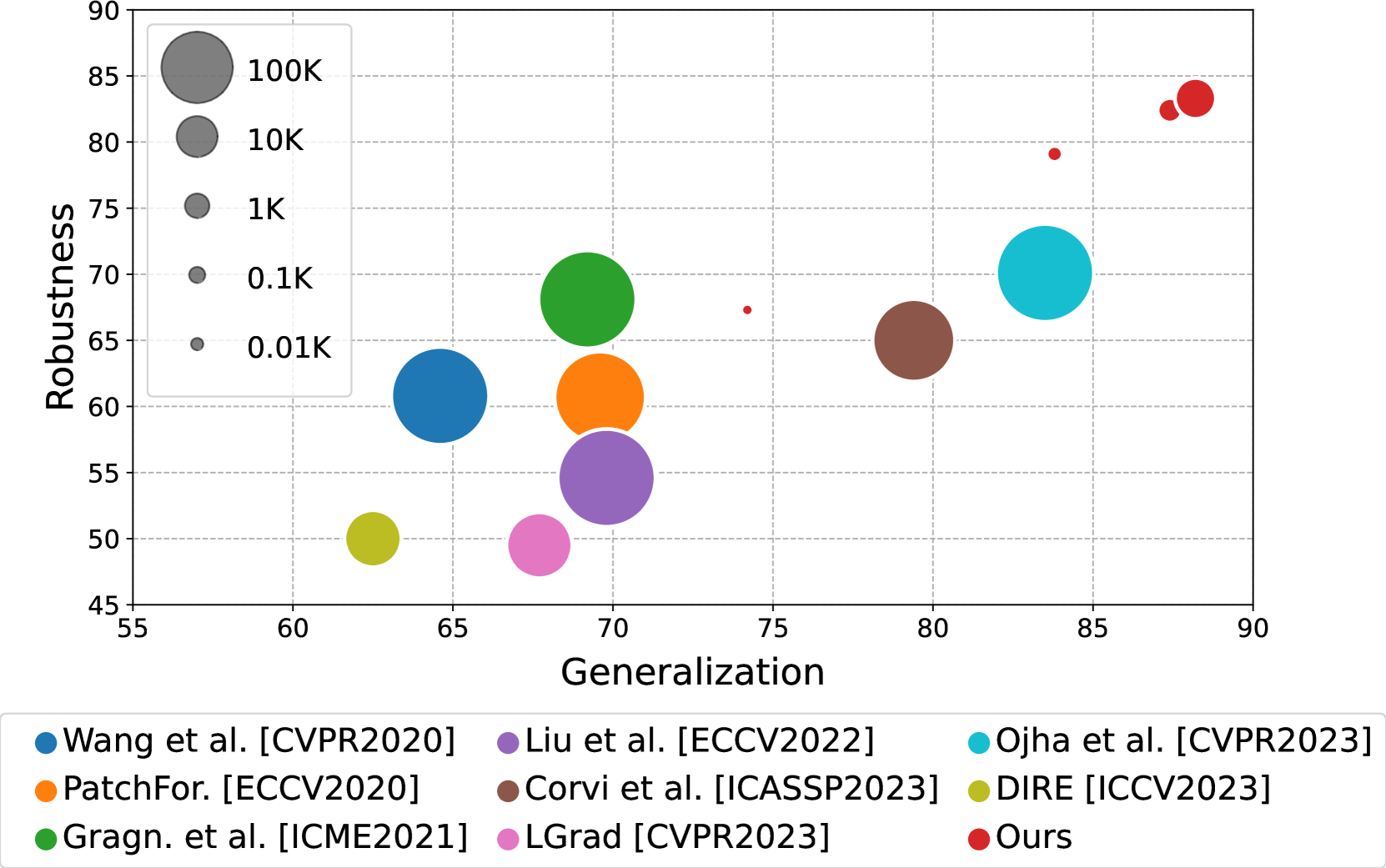
The aim of this work is to explore the potential of pre-trained vision-language models (VLMs) for universal detection of AI-generated images. We develop a lightweight detection strategy based on CLIP features and study its performance in a wide variety of challenging scenarios. We find that, contrary to previous beliefs, it is neither necessary nor convenient to use a large domain-specific dataset for training. On the contrary, by using only a handful of example images from a single generative model, a CLIP-based detector exhibits surprising generalization ability and high robustness across different architectures, including recent commercial tools such as Dalle-3, Midjourney v5, and Firefly. We match the state-of-the-art (SoTA) on in-distribution data and significantly improve upon it in terms of generalization to out-of-distribution data (+6% AUC) and robustness to impaired/laundered data (+13%). Our project is available at https://grip-unina.github.io/ClipBased-SyntheticImageDetection/
4/30/2024