Bridging Design Gaps: A Parametric Data Completion Approach With Graph Guided Diffusion Models
2406.11934
0
0
Abstract
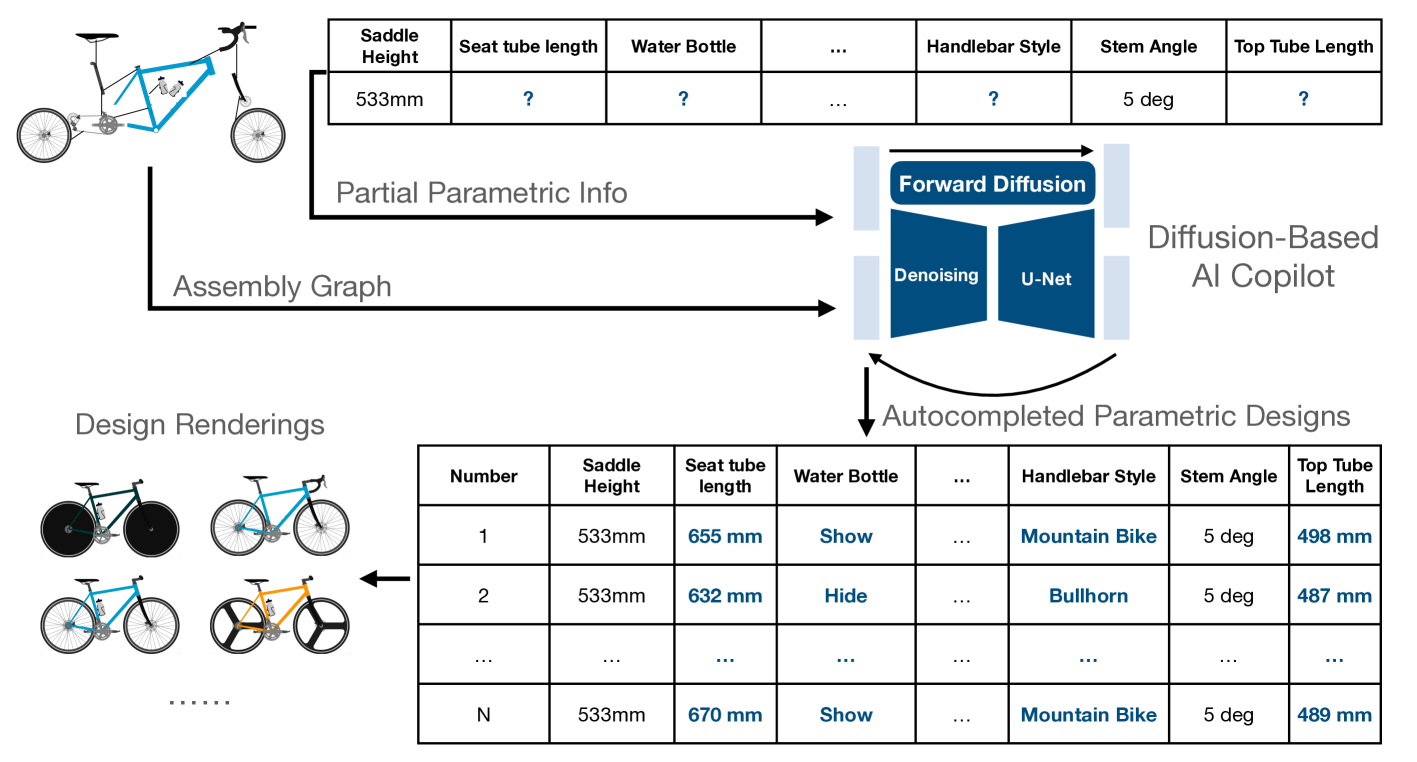
This study introduces a generative imputation model leveraging graph attention networks and tabular diffusion models for completing missing parametric data in engineering designs. This model functions as an AI design co-pilot, providing multiple design options for incomplete designs, which we demonstrate using the bicycle design CAD dataset. Through comparative evaluations, we demonstrate that our model significantly outperforms existing classical methods, such as MissForest, hotDeck, PPCA, and tabular generative method TabCSDI in both the accuracy and diversity of imputation options. Generative modeling also enables a broader exploration of design possibilities, thereby enhancing design decision-making by allowing engineers to explore a variety of design completions. The graph model combines GNNs with the structural information contained in assembly graphs, enabling the model to understand and predict the complex interdependencies between different design parameters. The graph model helps accurately capture and impute complex parametric interdependencies from an assembly graph, which is key for design problems. By learning from an existing dataset of designs, the imputation capability allows the model to act as an intelligent assistant that autocompletes CAD designs based on user-defined partial parametric design, effectively bridging the gap between ideation and realization. The proposed work provides a pathway to not only facilitate informed design decisions but also promote creative exploration in design.
Create account to get full access
Overview
- This paper proposes a novel approach to bridging design gaps using parametric data completion with graph-guided diffusion models.
- The method aims to fill in missing information in design data, leveraging the power of diffusion models and graph-based representations.
- The authors explore how this technique can enhance design workflows and improve the quality of design outputs.
Plain English Explanation
The paper presents a new way to help designers fill in the blanks when they're working on a project. Designers often have to work with incomplete or fragmented data, which can make it hard to come up with the best designs. The researchers developed a system that uses a special type of artificial intelligence called a diffusion model, combined with a graph-based representation of the design data, to automatically fill in the missing information.
The diffusion model acts like an intelligent guessing machine, learning patterns in the existing data and then using that knowledge to predict what the missing parts should look like. The graph-based representation helps the system understand the relationships and dependencies between different design elements, so it can make more informed guesses.
By using this approach, the researchers hope to bridge the gaps in design data and generate higher-quality, more complete design outputs. This could be particularly useful in fields like product design, architecture, or even graph generation, where designers often have to work with incomplete information.
Technical Explanation
The authors propose a parametric data completion approach that leverages graph-guided diffusion models to bridge design gaps. The key components of their method include:
-
Graph-based Design Representation: The design data is represented as a graph, where nodes correspond to design elements and edges capture the relationships between them. This graph-based representation allows the system to capture the inherent structure and dependencies in the design data.
-
Graph-Guided Diffusion Model: The researchers employ a diffusion model, a type of generative AI, to learn the underlying patterns in the design data. The diffusion model is guided by the graph structure, enabling it to generate plausible completions that respect the design constraints and dependencies.
-
Parametric Design Completion: The method supports parametric design, allowing users to specify certain design constraints or preferences. The graph-guided diffusion model then generates design completions that align with these parameters, bridging the gaps in the input data.
The authors evaluate their approach on various design datasets, demonstrating its ability to generate high-quality, semantically consistent design completions. The results show that the graph-guided diffusion model outperforms alternative imputation techniques, particularly in cases where the design data is highly incomplete or fragmented.
Critical Analysis
The paper presents a compelling approach to addressing the challenge of incomplete design data, which is a common problem in many design-oriented fields. The use of diffusion models, combined with the graph-based representation, is a novel and promising direction that could significantly improve design workflows and the quality of design outputs.
However, the authors acknowledge some potential limitations and areas for further research. For instance, the performance of the graph-guided diffusion model may be sensitive to the quality and completeness of the initial graph representation. Developing more robust and adaptive graph construction methods could be an important area of exploration.
Additionally, the paper focuses primarily on quantitative evaluations of the design completions, but does not delve deeply into subjective assessments of the design quality or the user experience of the proposed system. Incorporating feedback from designers and end-users could provide valuable insights and guide future iterations of the approach.
It would also be interesting to see how the method could be extended to handle more complex, multi-modal design data, such as incorporating not just geometric information but also textual descriptions, material properties, or other relevant design attributes.
Conclusion
The paper presents a novel approach to bridging design gaps using parametric data completion with graph-guided diffusion models. By leveraging the power of diffusion models and graph-based representations, the proposed method can generate high-quality, semantically consistent design completions, even in the face of highly incomplete or fragmented design data.
This work has the potential to significantly enhance design workflows, enabling designers to work more efficiently and effectively, and ultimately producing better design outcomes. The authors have made an important contribution to the field of design-oriented generative AI, and their approach could have far-reaching implications across various design-centric industries and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
Data Imputation with Iterative Graph Reconstruction
Jiajun Zhong, Weiwei Ye, Ning Gui
0
0
Effective data imputation demands rich latent ``structure discovery capabilities from ``plain tabular data. Recent advances in graph neural networks-based data imputation solutions show their strong structure learning potential by directly translating tabular data as bipartite graphs. However, due to a lack of relations between samples, those solutions treat all samples equally which is against one important observation: ``similar sample should give more information about missing values. This paper presents a novel Iterative graph Generation and Reconstruction framework for Missing data imputation(IGRM). Instead of treating all samples equally, we introduce the concept: ``friend networks to represent different relations among samples. To generate an accurate friend network with missing data, an end-to-end friend network reconstruction solution is designed to allow for continuous friend network optimization during imputation learning. The representation of the optimized friend network, in turn, is used to further optimize the data imputation process with differentiated message passing. Experiment results on eight benchmark datasets show that IGRM yields 39.13% lower mean absolute error compared with nine baselines and 9.04% lower than the second-best. Our code is available at https://github.com/G-AILab/IGRM.
4/16/2024
Unleashing the Potential of Diffusion Models for Incomplete Data Imputation
Hengrui Zhang, Liancheng Fang, Philip S. Yu
0
0
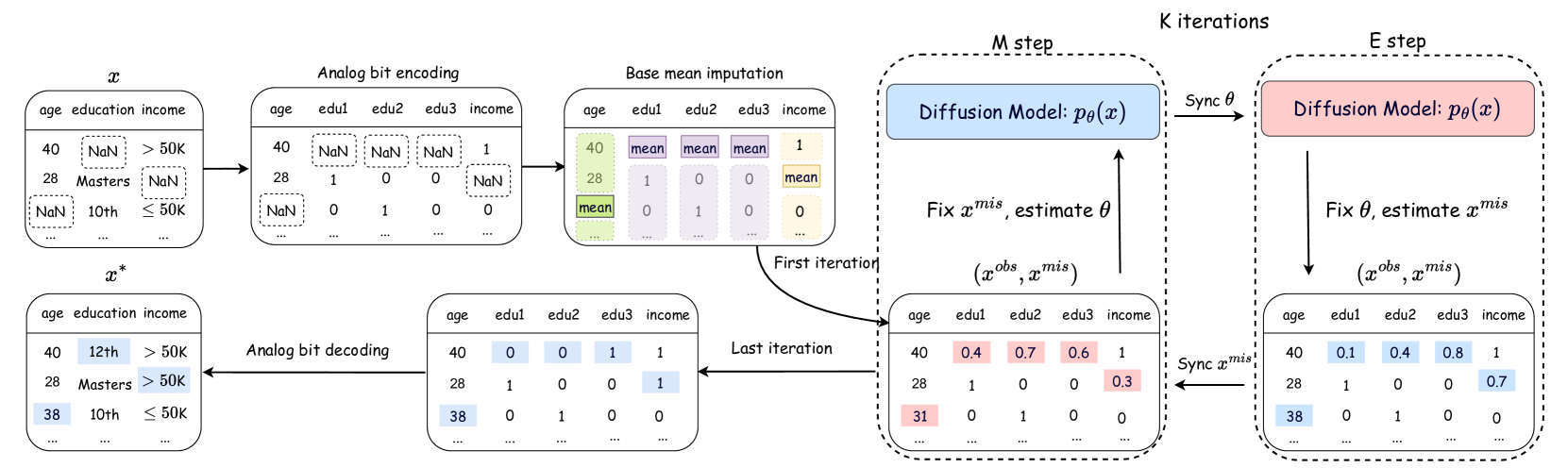
This paper introduces DiffPuter, an iterative method for missing data imputation that leverages the Expectation-Maximization (EM) algorithm and Diffusion Models. By treating missing data as hidden variables that can be updated during model training, we frame the missing data imputation task as an EM problem. During the M-step, DiffPuter employs a diffusion model to learn the joint distribution of both the observed and currently estimated missing data. In the E-step, DiffPuter re-estimates the missing data based on the conditional probability given the observed data, utilizing the diffusion model learned in the M-step. Starting with an initial imputation, DiffPuter alternates between the M-step and E-step until convergence. Through this iterative process, DiffPuter progressively refines the complete data distribution, yielding increasingly accurate estimations of the missing data. Our theoretical analysis demonstrates that the unconditional training and conditional sampling processes of the diffusion model align precisely with the objectives of the M-step and E-step, respectively. Empirical evaluations across 10 diverse datasets and comparisons with 16 different imputation methods highlight DiffPuter's superior performance. Notably, DiffPuter achieves an average improvement of 8.10% in MAE and 5.64% in RMSE compared to the most competitive existing method.
6/3/2024
Bridging Model-Based Optimization and Generative Modeling via Conservative Fine-Tuning of Diffusion Models
Masatoshi Uehara, Yulai Zhao, Ehsan Hajiramezanali, Gabriele Scalia, Gokcen Eraslan, Avantika Lal, Sergey Levine, Tommaso Biancalani
0
0
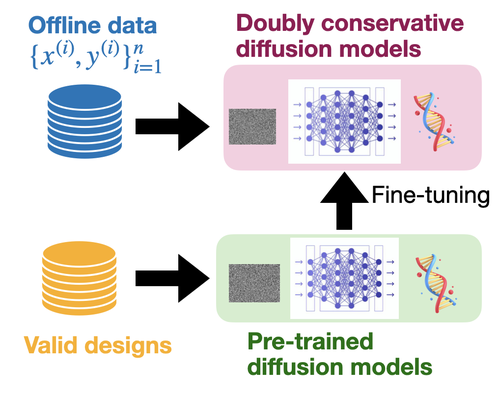
AI-driven design problems, such as DNA/protein sequence design, are commonly tackled from two angles: generative modeling, which efficiently captures the feasible design space (e.g., natural images or biological sequences), and model-based optimization, which utilizes reward models for extrapolation. To combine the strengths of both approaches, we adopt a hybrid method that fine-tunes cutting-edge diffusion models by optimizing reward models through RL. Although prior work has explored similar avenues, they primarily focus on scenarios where accurate reward models are accessible. In contrast, we concentrate on an offline setting where a reward model is unknown, and we must learn from static offline datasets, a common scenario in scientific domains. In offline scenarios, existing approaches tend to suffer from overoptimization, as they may be misled by the reward model in out-of-distribution regions. To address this, we introduce a conservative fine-tuning approach, BRAID, by optimizing a conservative reward model, which includes additional penalization outside of offline data distributions. Through empirical and theoretical analysis, we demonstrate the capability of our approach to outperform the best designs in offline data, leveraging the extrapolation capabilities of reward models while avoiding the generation of invalid designs through pre-trained diffusion models.
6/4/2024

Generative Design through Quality-Diversity Data Synthesis and Language Models
Adam Gaier, James Stoddart, Lorenzo Villaggi, Shyam Sudhakaran
0
0
Two fundamental challenges face generative models in engineering applications: the acquisition of high-performing, diverse datasets, and the adherence to precise constraints in generated designs. We propose a novel approach combining optimization, constraint satisfaction, and language models to tackle these challenges in architectural design. Our method uses Quality-Diversity (QD) to generate a diverse, high-performing dataset. We then fine-tune a language model with this dataset to generate high-level designs. These designs are then refined into detailed, constraint-compliant layouts using the Wave Function Collapse algorithm. Our system demonstrates reliable adherence to textual guidance, enabling the generation of layouts with targeted architectural and performance features. Crucially, our results indicate that data synthesized through the evolutionary search of QD not only improves overall model performance but is essential for the model's ability to closely adhere to textual guidance. This improvement underscores the pivotal role evolutionary computation can play in creating the datasets key to training generative models for design. Web article at https://tilegpt.github.io
5/17/2024