Rethinking the Diffusion Models for Numerical Tabular Data Imputation from the Perspective of Wasserstein Gradient Flow
2406.15762
0
0
Abstract
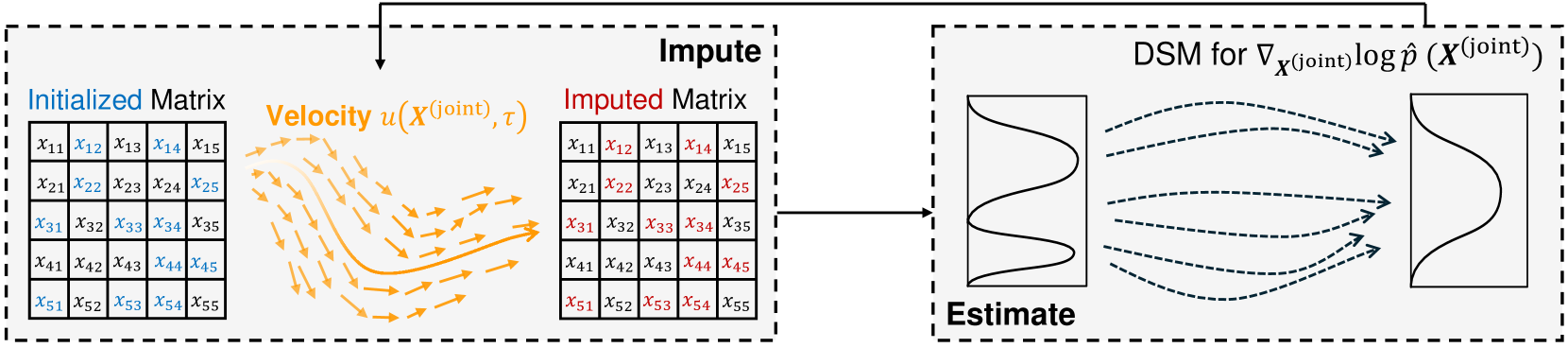
Diffusion models (DMs) have gained attention in Missing Data Imputation (MDI), but there remain two long-neglected issues to be addressed: (1). Inaccurate Imputation, which arises from inherently sample-diversification-pursuing generative process of DMs. (2). Difficult Training, which stems from intricate design required for the mask matrix in model training stage. To address these concerns within the realm of numerical tabular datasets, we introduce a novel principled approach termed Kernelized Negative Entropy-regularized Wasserstein gradient flow Imputation (KnewImp). Specifically, based on Wasserstein gradient flow (WGF) framework, we first prove that issue (1) stems from the cost functionals implicitly maximized in DM-based MDI are equivalent to the MDI's objective plus diversification-promoting non-negative terms. Based on this, we then design a novel cost functional with diversification-discouraging negative entropy and derive our KnewImp approach within WGF framework and reproducing kernel Hilbert space. After that, we prove that the imputation procedure of KnewImp can be derived from another cost functional related to the joint distribution, eliminating the need for the mask matrix and hence naturally addressing issue (2). Extensive experiments demonstrate that our proposed KnewImp approach significantly outperforms existing state-of-the-art methods.
Create account to get full access
Overview
- The paper "Rethinking the Diffusion Models for Numerical Tabular Data Imputation from the Perspective of Wasserstein Gradient Flow" proposes a new approach for numerical tabular data imputation using diffusion models.
- The key idea is to frame the imputation task as a Wasserstein gradient flow problem, which provides theoretical guarantees and can handle complex data distributions.
- The authors develop a specific diffusion model architecture and training procedure tailored for tabular data imputation, and demonstrate its effectiveness on several benchmark datasets.
Plain English Explanation
In machine learning, there is often the challenge of dealing with incomplete or missing data - for example, a table of information might be missing some of the values. This paper introduces a new way to address this "data imputation" problem, particularly for numerical tabular data (like spreadsheets or databases).
The core insight is to think of the imputation task as a specific type of optimization problem, known as a "Wasserstein gradient flow." This provides a principled mathematical framework for training a machine learning model to fill in the missing values, with guarantees about the quality of the imputations.
The authors then design a specialized neural network architecture and training procedure that leverages this Wasserstein gradient flow perspective. The key advantage is that it can effectively model complex underlying data distributions, unlike some simpler imputation methods.
Through experiments on benchmark datasets, the authors show that their Wasserstein gradient flow-based diffusion model outperforms other state-of-the-art imputation techniques. This suggests it could be a valuable tool for working with messy, incomplete tabular datasets that are common in many real-world applications.
Technical Explanation
The paper formulates the task of numerical tabular data imputation as a Wasserstein gradient flow problem. This provides a principled mathematical framework for training a generative model to fill in missing values, with theoretical guarantees on the quality of the imputations.
Specifically, the authors develop a diffusion model architecture and training procedure tailored for tabular data. Diffusion models are a type of generative model that learn to progressively "denoise" random noise into samples resembling the training data. The Wasserstein gradient flow perspective allows the diffusion process to effectively model complex data distributions.
The authors demonstrate the effectiveness of their Wasserstein gradient flow-based diffusion model on several benchmark datasets for numerical tabular data imputation. They show that it outperforms other state-of-the-art imputation techniques, including deep MMD-based methods and knowledge distillation approaches.
Critical Analysis
The paper provides a principled and well-motivated approach for numerical tabular data imputation, with a strong theoretical foundation in Wasserstein gradient flow. The authors' experiments demonstrate the practical effectiveness of their method on benchmark datasets.
However, the paper does not discuss potential limitations or caveats of their approach. For example, it is unclear how the method would scale to extremely high-dimensional tabular data, or how it would handle non-numerical data types (e.g., categorical or text features). Additionally, the paper does not explore the interpretability or uncertainty quantification of the imputed values.
Further research could investigate these aspects, as well as potential applications of the Wasserstein gradient flow perspective to other tabular data tasks beyond imputation, such as anomaly detection or causal inference.
Conclusion
This paper proposes a novel approach for numerical tabular data imputation, framing the problem as a Wasserstein gradient flow optimization. The authors develop a specialized diffusion model architecture and training procedure that can effectively model complex data distributions and outperform existing imputation techniques.
The Wasserstein gradient flow perspective provides a principled mathematical framework for this task, with theoretical guarantees on the quality of the imputations. While the paper does not explore all potential limitations, it suggests that this approach could be a valuable tool for working with messy, incomplete tabular datasets that are common in many real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
Convergence of flow-based generative models via proximal gradient descent in Wasserstein space
Xiuyuan Cheng, Jianfeng Lu, Yixin Tan, Yao Xie
0
0
Flow-based generative models enjoy certain advantages in computing the data generation and the likelihood, and have recently shown competitive empirical performance. Compared to the accumulating theoretical studies on related score-based diffusion models, analysis of flow-based models, which are deterministic in both forward (data-to-noise) and reverse (noise-to-data) directions, remain sparse. In this paper, we provide a theoretical guarantee of generating data distribution by a progressive flow model, the so-called JKO flow model, which implements the Jordan-Kinderleherer-Otto (JKO) scheme in a normalizing flow network. Leveraging the exponential convergence of the proximal gradient descent (GD) in Wasserstein space, we prove the Kullback-Leibler (KL) guarantee of data generation by a JKO flow model to be $O(varepsilon^2)$ when using $N lesssim log (1/varepsilon)$ many JKO steps ($N$ Residual Blocks in the flow) where $varepsilon $ is the error in the per-step first-order condition. The assumption on data density is merely a finite second moment, and the theory extends to data distributions without density and when there are inversion errors in the reverse process where we obtain KL-$W_2$ mixed error guarantees. The non-asymptotic convergence rate of the JKO-type $W_2$-proximal GD is proved for a general class of convex objective functionals that includes the KL divergence as a special case, which can be of independent interest. The analysis framework can extend to other first-order Wasserstein optimization schemes applied to flow-based generative models.
5/20/2024
🤷
Statistically Optimal Generative Modeling with Maximum Deviation from the Empirical Distribution
Elen Vardanyan, Sona Hunanyan, Tigran Galstyan, Arshak Minasyan, Arnak Dalalyan
0
0
This paper explores the problem of generative modeling, aiming to simulate diverse examples from an unknown distribution based on observed examples. While recent studies have focused on quantifying the statistical precision of popular algorithms, there is a lack of mathematical evaluation regarding the non-replication of observed examples and the creativity of the generative model. We present theoretical insights into this aspect, demonstrating that the Wasserstein GAN, constrained to left-invertible push-forward maps, generates distributions that avoid replication and significantly deviate from the empirical distribution. Importantly, we show that left-invertibility achieves this without compromising the statistical optimality of the resulting generator. Our most important contribution provides a finite-sample lower bound on the Wasserstein-1 distance between the generative distribution and the empirical one. We also establish a finite-sample upper bound on the distance between the generative distribution and the true data-generating one. Both bounds are explicit and show the impact of key parameters such as sample size, dimensions of the ambient and latent spaces, noise level, and smoothness measured by the Lipschitz constant.
6/7/2024
Unleashing the Potential of Diffusion Models for Incomplete Data Imputation
Hengrui Zhang, Liancheng Fang, Philip S. Yu
0
0
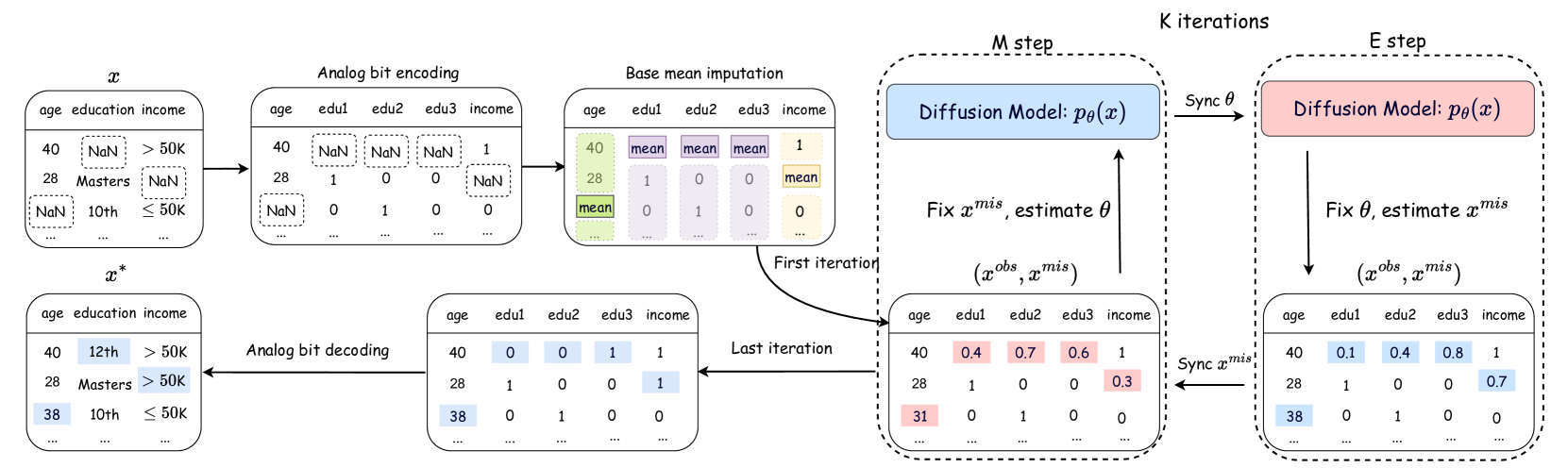
This paper introduces DiffPuter, an iterative method for missing data imputation that leverages the Expectation-Maximization (EM) algorithm and Diffusion Models. By treating missing data as hidden variables that can be updated during model training, we frame the missing data imputation task as an EM problem. During the M-step, DiffPuter employs a diffusion model to learn the joint distribution of both the observed and currently estimated missing data. In the E-step, DiffPuter re-estimates the missing data based on the conditional probability given the observed data, utilizing the diffusion model learned in the M-step. Starting with an initial imputation, DiffPuter alternates between the M-step and E-step until convergence. Through this iterative process, DiffPuter progressively refines the complete data distribution, yielding increasingly accurate estimations of the missing data. Our theoretical analysis demonstrates that the unconditional training and conditional sampling processes of the diffusion model align precisely with the objectives of the M-step and E-step, respectively. Empirical evaluations across 10 diverse datasets and comparisons with 16 different imputation methods highlight DiffPuter's superior performance. Notably, DiffPuter achieves an average improvement of 8.10% in MAE and 5.64% in RMSE compared to the most competitive existing method.
6/3/2024

Deep MMD Gradient Flow without adversarial training
Alexandre Galashov, Valentin de Bortoli, Arthur Gretton
0
0
We propose a gradient flow procedure for generative modeling by transporting particles from an initial source distribution to a target distribution, where the gradient field on the particles is given by a noise-adaptive Wasserstein Gradient of the Maximum Mean Discrepancy (MMD). The noise-adaptive MMD is trained on data distributions corrupted by increasing levels of noise, obtained via a forward diffusion process, as commonly used in denoising diffusion probabilistic models. The result is a generalization of MMD Gradient Flow, which we call Diffusion-MMD-Gradient Flow or DMMD. The divergence training procedure is related to discriminator training in Generative Adversarial Networks (GAN), but does not require adversarial training. We obtain competitive empirical performance in unconditional image generation on CIFAR10, MNIST, CELEB-A (64 x64) and LSUN Church (64 x 64). Furthermore, we demonstrate the validity of the approach when MMD is replaced by a lower bound on the KL divergence.
5/14/2024