Large-scale Multi-Modal Pre-trained Models: A Comprehensive Survey
2302.10035
0
0
➖
Abstract
With the urgent demand for generalized deep models, many pre-trained big models are proposed, such as BERT, ViT, GPT, etc. Inspired by the success of these models in single domains (like computer vision and natural language processing), the multi-modal pre-trained big models have also drawn more and more attention in recent years. In this work, we give a comprehensive survey of these models and hope this paper could provide new insights and helps fresh researchers to track the most cutting-edge works. Specifically, we firstly introduce the background of multi-modal pre-training by reviewing the conventional deep learning, pre-training works in natural language process, computer vision, and speech. Then, we introduce the task definition, key challenges, and advantages of multi-modal pre-training models (MM-PTMs), and discuss the MM-PTMs with a focus on data, objectives, network architectures, and knowledge enhanced pre-training. After that, we introduce the downstream tasks used for the validation of large-scale MM-PTMs, including generative, classification, and regression tasks. We also give visualization and analysis of the model parameters and results on representative downstream tasks. Finally, we point out possible research directions for this topic that may benefit future works. In addition, we maintain a continuously updated paper list for large-scale pre-trained multi-modal big models: https://github.com/wangxiao5791509/MultiModal_BigModels_Survey. This paper has been published by the journal Machine Intelligence Research (MIR), https://link.springer.com/article/10.1007/s11633-022-1410-8, DOI: 10.1007/s11633-022-1410-8, vol. 20, no. 4, pp. 447-482, 2023.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper provides a comprehensive survey of pre-trained multi-modal big models, such as BERT, ViT, and GPT.
- It reviews the background of multi-modal pre-training, including conventional deep learning and pre-training in natural language processing, computer vision, and speech.
- The paper introduces the task definition, key challenges, and advantages of multi-modal pre-training models (MM-PTMs).
- It discusses MM-PTMs in detail, focusing on data, objectives, network architectures, and knowledge-enhanced pre-training.
- The paper also introduces downstream tasks used to validate large-scale MM-PTMs, including generative, classification, and regression tasks.
- Visualizations and analyses of model parameters and results on representative downstream tasks are provided.
- Possible research directions for this topic are discussed to benefit future work.
Plain English Explanation
The paper explores the growing interest in large, pre-trained models that can handle multiple types of data, such as text, images, and speech. These "multi-modal" models have shown great potential in a variety of applications, building on the successes of single-domain models like BERT for natural language processing and ViT for computer vision.
The paper first provides some background on the development of deep learning and pre-training in different domains. It then explains the key features of multi-modal pre-training models, including the types of data they can handle, the objectives they are trained on, and the architectural choices that allow them to work with multiple modalities.
One of the main advantages of these models is their ability to be "pre-trained" on large, diverse datasets and then "fine-tuned" for specific tasks, like generating software code or medical image diagnosis. The paper discusses how these models are evaluated on a range of downstream tasks, with visualizations and analyses to understand their inner workings.
Finally, the paper suggests some promising directions for future research in this area, such as incorporating user preferences into the model design or finding more efficient ways to pre-train and fine-tune these large, complex models.
Technical Explanation
The paper begins by highlighting the growing demand for generalized deep models that can handle multiple data modalities, such as text, images, and speech. Inspired by the success of single-domain models like BERT, ViT, and GPT, the authors focus on the emergence of multi-modal pre-trained big models (MM-PTMs) in recent years.
The authors first review the background of multi-modal pre-training, covering the development of conventional deep learning and pre-training techniques in natural language processing, computer vision, and speech. This provides context for understanding the key challenges and advantages of MM-PTMs.
The paper then delves into the details of MM-PTMs, discussing the task definition, data, objectives, network architectures, and knowledge-enhanced pre-training approaches. For example, the authors explain how MM-PTMs are trained on diverse datasets that include various modalities, and how the models are designed to effectively capture cross-modal relationships.
To validate the performance of these large-scale MM-PTMs, the paper introduces a range of downstream tasks, including generative, classification, and regression tasks. The authors provide visualizations and analyses of the model parameters and results on representative tasks, offering insights into the inner workings of these complex models.
Finally, the paper suggests potential research directions for the field, such as exploring ways to incorporate user preferences into the model design or developing more efficient pre-training and fine-tuning techniques for MM-PTMs.
Critical Analysis
The paper provides a thorough and well-structured overview of the current state of multi-modal pre-trained big models. It effectively highlights the key challenges and advantages of these models, while also acknowledging the limitations and areas for further research.
One potential concern raised in the paper is the computational and resource-intensive nature of training and fine-tuning these large-scale models. The authors suggest that finding more efficient approaches to pre-training and fine-tuning could be a fruitful area for future research. This is an important consideration, as the widespread adoption of MM-PTMs may depend on developing more scalable and accessible training methods.
Additionally, the paper notes the importance of incorporating knowledge-enhanced pre-training, which can help these models better understand and reason about the world. However, the authors do not delve deeply into the specific techniques and trade-offs involved in this approach. Further exploration of knowledge-enhanced pre-training, and its implications for model performance and interpretability, could be a valuable addition to the research landscape.
Overall, the paper provides a comprehensive and insightful review of the current state of multi-modal pre-trained big models, highlighting both their promise and the challenges that remain to be addressed. Readers are encouraged to think critically about the research and consider how these models might evolve and impact various domains in the future.
Conclusion
This paper offers a comprehensive survey of the rapidly evolving field of multi-modal pre-trained big models (MM-PTMs). By reviewing the background, key challenges, and advantages of these models, as well as discussing their architectures, training approaches, and evaluation on downstream tasks, the authors provide a valuable resource for researchers and practitioners interested in this area.
The detailed technical explanations, coupled with the plain-language summary and critical analysis, make this paper accessible to a wide audience. The authors' emphasis on potential research directions, such as improving pre-training and fine-tuning efficiency and incorporating knowledge-enhanced techniques, suggests exciting avenues for future work.
As the demand for generalized deep models continues to grow, this paper serves as an important reference point for understanding the current state of multi-modal pre-training and the challenges that still need to be addressed. By sharing this comprehensive survey, the authors contribute to the ongoing progress and advancement of this transformative field of artificial intelligence.
Related Papers

A Review of Multi-Modal Large Language and Vision Models
Kilian Carolan, Laura Fennelly, Alan F. Smeaton
0
0
Large Language Models (LLMs) have recently emerged as a focal point of research and application, driven by their unprecedented ability to understand and generate text with human-like quality. Even more recently, LLMs have been extended into multi-modal large language models (MM-LLMs) which extends their capabilities to deal with image, video and audio information, in addition to text. This opens up applications like text-to-video generation, image captioning, text-to-speech, and more and is achieved either by retro-fitting an LLM with multi-modal capabilities, or building a MM-LLM from scratch. This paper provides an extensive review of the current state of those LLMs with multi-modal capabilities as well as the very recent MM-LLMs. It covers the historical development of LLMs especially the advances enabled by transformer-based architectures like OpenAI's GPT series and Google's BERT, as well as the role of attention mechanisms in enhancing model performance. The paper includes coverage of the major and most important of the LLMs and MM-LLMs and also covers the techniques of model tuning, including fine-tuning and prompt engineering, which tailor pre-trained models to specific tasks or domains. Ethical considerations and challenges, such as data bias and model misuse, are also analysed to underscore the importance of responsible AI development and deployment. Finally, we discuss the implications of open-source versus proprietary models in AI research. Through this review, we provide insights into the transformative potential of MM-LLMs in various applications.
4/3/2024
🤔
MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
Brandon McKinzie, Zhe Gan, Jean-Philippe Fauconnier, Sam Dodge, Bowen Zhang, Philipp Dufter, Dhruti Shah, Xianzhi Du, Futang Peng, Floris Weers, Anton Belyi, Haotian Zhang, Karanjeet Singh, Doug Kang, Ankur Jain, Hongyu H`e, Max Schwarzer, Tom Gunter, Xiang Kong, Aonan Zhang, Jianyu Wang, Chong Wang, Nan Du, Tao Lei, Sam Wiseman, Guoli Yin, Mark Lee, Zirui Wang, Ruoming Pang, Peter Grasch, Alexander Toshev, Yinfei Yang
0
0
In this work, we discuss building performant Multimodal Large Language Models (MLLMs). In particular, we study the importance of various architecture components and data choices. Through careful and comprehensive ablations of the image encoder, the vision language connector, and various pre-training data choices, we identified several crucial design lessons. For example, we demonstrate that for large-scale multimodal pre-training using a careful mix of image-caption, interleaved image-text, and text-only data is crucial for achieving state-of-the-art (SOTA) few-shot results across multiple benchmarks, compared to other published pre-training results. Further, we show that the image encoder together with image resolution and the image token count has substantial impact, while the vision-language connector design is of comparatively negligible importance. By scaling up the presented recipe, we build MM1, a family of multimodal models up to 30B parameters, including both dense models and mixture-of-experts (MoE) variants, that are SOTA in pre-training metrics and achieve competitive performance after supervised fine-tuning on a range of established multimodal benchmarks. Thanks to large-scale pre-training, MM1 enjoys appealing properties such as enhanced in-context learning, and multi-image reasoning, enabling few-shot chain-of-thought prompting.
4/22/2024
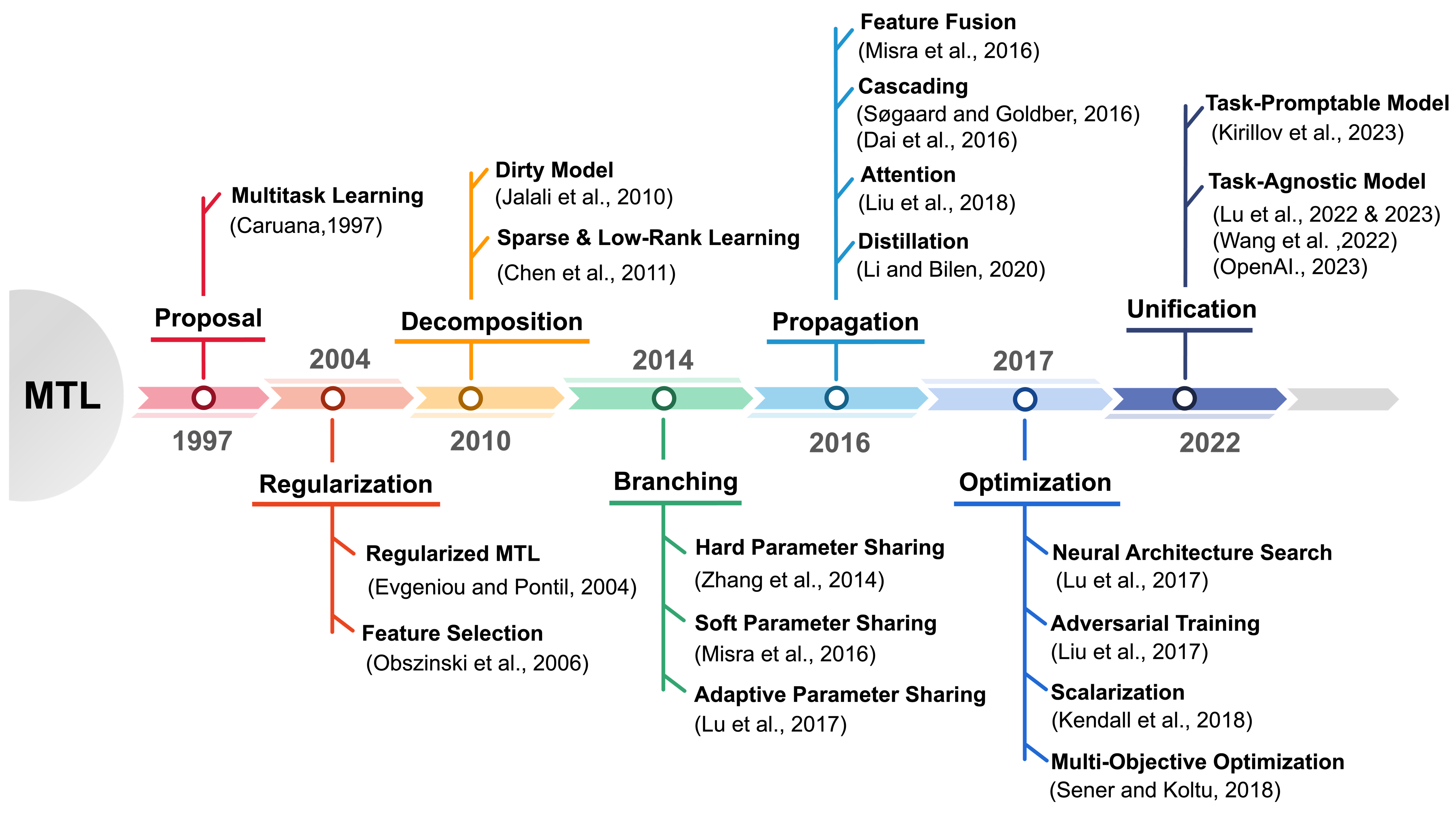
Unleashing the Power of Multi-Task Learning: A Comprehensive Survey Spanning Traditional, Deep, and Pretrained Foundation Model Eras
Jun Yu, Yutong Dai, Xiaokang Liu, Jin Huang, Yishan Shen, Ke Zhang, Rong Zhou, Eashan Adhikarla, Wenxuan Ye, Yixin Liu, Zhaoming Kong, Kai Zhang, Yilong Yin, Vinod Namboodiri, Brian D. Davison, Jason H. Moore, Yong Chen
0
0
MTL is a learning paradigm that effectively leverages both task-specific and shared information to address multiple related tasks simultaneously. In contrast to STL, MTL offers a suite of benefits that enhance both the training process and the inference efficiency. MTL's key advantages encompass streamlined model architecture, performance enhancement, and cross-domain generalizability. Over the past twenty years, MTL has become widely recognized as a flexible and effective approach in various fields, including CV, NLP, recommendation systems, disease prognosis and diagnosis, and robotics. This survey provides a comprehensive overview of the evolution of MTL, encompassing the technical aspects of cutting-edge methods from traditional approaches to deep learning and the latest trend of pretrained foundation models. Our survey methodically categorizes MTL techniques into five key areas: regularization, relationship learning, feature propagation, optimization, and pre-training. This categorization not only chronologically outlines the development of MTL but also dives into various specialized strategies within each category. Furthermore, the survey reveals how the MTL evolves from handling a fixed set of tasks to embracing a more flexible approach free from task or modality constraints. It explores the concepts of task-promptable and -agnostic training, along with the capacity for ZSL, which unleashes the untapped potential of this historically coveted learning paradigm. Overall, we hope this survey provides the research community with a comprehensive overview of the advancements in MTL from its inception in 1997 to the present in 2023. We address present challenges and look ahead to future possibilities, shedding light on the opportunities and potential avenues for MTL research in a broad manner. This project is publicly available at https://github.com/junfish/Awesome-Multitask-Learning.
5/1/2024
🧠
Continual Learning with Pre-Trained Models: A Survey
Da-Wei Zhou, Hai-Long Sun, Jingyi Ning, Han-Jia Ye, De-Chuan Zhan
0
0
Nowadays, real-world applications often face streaming data, which requires the learning system to absorb new knowledge as data evolves. Continual Learning (CL) aims to achieve this goal and meanwhile overcome the catastrophic forgetting of former knowledge when learning new ones. Typical CL methods build the model from scratch to grow with incoming data. However, the advent of the pre-trained model (PTM) era has sparked immense research interest, particularly in leveraging PTMs' robust representational capabilities. This paper presents a comprehensive survey of the latest advancements in PTM-based CL. We categorize existing methodologies into three distinct groups, providing a comparative analysis of their similarities, differences, and respective advantages and disadvantages. Additionally, we offer an empirical study contrasting various state-of-the-art methods to highlight concerns regarding fairness in comparisons. The source code to reproduce these evaluations is available at: https://github.com/sun-hailong/LAMDA-PILOT
4/24/2024