Unleashing the Power of Task-Specific Directions in Parameter Efficient Fine-tuning

0

Sign in to get full access
Overview
- The paper explores the use of task-specific directions in parameter-efficient fine-tuning, a technique that allows for significant model performance improvements with minimal changes to the model parameters.
- It identifies a contradiction in the task-specific directions within the Low-Rank Adaptation (LoRA) method, a popular parameter-efficient fine-tuning approach.
- The paper proposes a solution to address this contradiction, leading to improved model performance.
Plain English Explanation
The research paper discusses a technique called parameter-efficient fine-tuning, which allows machine learning models to be adapted to new tasks with minimal changes to the underlying model parameters. This is an important capability, as it can make it easier and more efficient to apply powerful language models to a variety of applications.
One specific approach to parameter-efficient fine-tuning is called LoRA, which works by adding small updates to the model's weights rather than retraining the entire model. The researchers found a contradiction in how LoRA uses task-specific directions, which are vectors that help the model focus on the most relevant information for a particular task.
To address this, the paper proposes a solution that resolves the contradiction in the task-specific directions within LoRA. This leads to improved model performance compared to the original LoRA approach. The key insight is that by properly aligning the task-specific directions, the model can more effectively leverage the most relevant information for the task at hand.
Technical Explanation
The paper identifies a contradiction in how LoRA uses task-specific directions. LoRA is a parameter-efficient fine-tuning method that works by adding small, rank-one updates to the model's weights, rather than retraining the entire model.
The task-specific directions in LoRA are used to guide the model towards the most relevant information for a particular task. However, the researchers found that the way these task-specific directions are used within LoRA can lead to a contradiction, where the directions are not properly aligned with the task at hand.
To address this issue, the paper proposes a solution that resolves the contradiction in the task-specific directions. This involves modifying the LoRA training process to better align the task-specific directions with the target task. The researchers demonstrate that this improved alignment leads to significant performance gains compared to the original LoRA approach, as the model can more effectively leverage the most relevant information for the task.
Critical Analysis
The paper provides a thoughtful analysis of an important issue within the LoRA method for parameter-efficient fine-tuning. By identifying and addressing the contradiction in the task-specific directions, the researchers have made a valuable contribution to improving the effectiveness of this approach.
One potential limitation of the research is that it is focused solely on the LoRA method, and it's unclear how the proposed solution would generalize to other parameter-efficient fine-tuning techniques. Further research could explore the applicability of the insights to a broader range of fine-tuning methods.
Additionally, the paper does not delve deeply into the potential real-world implications or limitations of the improved LoRA approach. Additional analysis on the practical considerations, such as the computational and memory overhead, could provide valuable context for potential users of the technique.
Overall, the paper presents a thoughtful and technically sound contribution to the field of parameter-efficient fine-tuning, with the potential for significant impact on the development of more efficient and effective machine learning models.
Conclusion
This research paper explores a key issue within the LoRA method for parameter-efficient fine-tuning, identifying a contradiction in how the technique uses task-specific directions. By proposing a solution to resolve this contradiction, the researchers have demonstrated a way to significantly improve the performance of LoRA-based fine-tuning approaches.
The insights from this work have the potential to contribute to the development of more efficient and effective machine learning models, which can be adapted to a wide range of tasks with minimal changes to the underlying model parameters. As the field of parameter-efficient fine-tuning continues to evolve, this research represents an important step forward in unlocking the full power of task-specific directions in model optimization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Unleashing the Power of Task-Specific Directions in Parameter Efficient Fine-tuning
Chongjie Si, Zhiyi Shi, Shifan Zhang, Xiaokang Yang, Hanspeter Pfister, Wei Shen
Large language models demonstrate impressive performance on downstream tasks, yet requiring extensive resource consumption when fully fine-tuning all parameters. To mitigate this, Parameter Efficient Fine-Tuning (PEFT) strategies, such as LoRA, have been developed. In this paper, we delve into the concept of task-specific directions--critical for transitioning large models from pre-trained states to task-specific enhancements in PEFT. We propose a framework to clearly define these directions and explore their properties, and practical utilization challenges. We then introduce a novel approach, LoRA-Dash, which aims to maximize the impact of task-specific directions during the fine-tuning process, thereby enhancing model performance on targeted tasks. Extensive experiments have conclusively demonstrated the effectiveness of LoRA-Dash, and in-depth analyses further reveal the underlying mechanisms of LoRA-Dash. The code is available at https://github.com/Chongjie-Si/Subspace-Tuning.
Read more9/4/2024
0
DLoRA: Distributed Parameter-Efficient Fine-Tuning Solution for Large Language Model
Chao Gao, Sai Qian Zhang
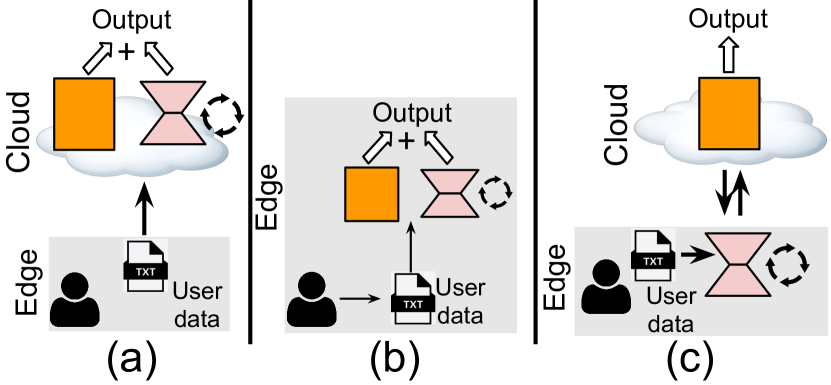
To enhance the performance of large language models (LLM) on downstream tasks, one solution is to fine-tune certain LLM parameters and make it better align with the characteristics of the training dataset. This process is commonly known as parameter-efficient fine-tuning (PEFT). Due to the scale of LLM, PEFT operations are usually executed in the public environment (e.g., cloud server). This necessitates the sharing of sensitive user data across public environments, thereby raising potential privacy concerns. To tackle these challenges, we propose a distributed PEFT framework called DLoRA. DLoRA enables scalable PEFT operations to be performed collaboratively between the cloud and user devices. Coupled with the proposed Kill and Revive algorithm, the evaluation results demonstrate that DLoRA can significantly reduce the computation and communication workload over the user devices while achieving superior accuracy and privacy protection.
Read more4/9/2024
0
HydraLoRA: An Asymmetric LoRA Architecture for Efficient Fine-Tuning
Chunlin Tian, Zhan Shi, Zhijiang Guo, Li Li, Chengzhong Xu
Adapting Large Language Models (LLMs) to new tasks through fine-tuning has been made more efficient by the introduction of Parameter-Efficient Fine-Tuning (PEFT) techniques, such as LoRA. However, these methods often underperform compared to full fine-tuning, particularly in scenarios involving complex datasets. This issue becomes even more pronounced in complex domains, highlighting the need for improved PEFT approaches that can achieve better performance. Through a series of experiments, we have uncovered two critical insights that shed light on the training and parameter inefficiency of LoRA. Building on these insights, we have developed HydraLoRA, a LoRA framework with an asymmetric structure that eliminates the need for domain expertise. Our experiments demonstrate that HydraLoRA outperforms other PEFT approaches, even those that rely on domain knowledge during the training and inference phases.
Read more5/24/2024
🌿
2
LoRA Land: 310 Fine-tuned LLMs that Rival GPT-4, A Technical Report
Justin Zhao, Timothy Wang, Wael Abid, Geoffrey Angus, Arnav Garg, Jeffery Kinnison, Alex Sherstinsky, Piero Molino, Travis Addair, Devvret Rishi
Low Rank Adaptation (LoRA) has emerged as one of the most widely adopted methods for Parameter Efficient Fine-Tuning (PEFT) of Large Language Models (LLMs). LoRA reduces the number of trainable parameters and memory usage while achieving comparable performance to full fine-tuning. We aim to assess the viability of training and serving LLMs fine-tuned with LoRA in real-world applications. First, we measure the quality of LLMs fine-tuned with quantized low rank adapters across 10 base models and 31 tasks for a total of 310 models. We find that 4-bit LoRA fine-tuned models outperform base models by 34 points and GPT-4 by 10 points on average. Second, we investigate the most effective base models for fine-tuning and assess the correlative and predictive capacities of task complexity heuristics in forecasting the outcomes of fine-tuning. Finally, we evaluate the latency and concurrency capabilities of LoRAX, an open-source Multi-LoRA inference server that facilitates the deployment of multiple LoRA fine-tuned models on a single GPU using shared base model weights and dynamic adapter loading. LoRAX powers LoRA Land, a web application that hosts 25 LoRA fine-tuned Mistral-7B LLMs on a single NVIDIA A100 GPU with 80GB memory. LoRA Land highlights the quality and cost-effectiveness of employing multiple specialized LLMs over a single, general-purpose LLM.
Read more5/3/2024