Unraveling Babel: Exploring Multilingual Activation Patterns of LLMs and Their Applications
2402.16367
0
0

Abstract
Recently, large language models (LLMs) have achieved tremendous breakthroughs in the field of NLP, but still lack understanding of their internal activities when processing different languages. We designed a method to convert dense LLMs into fine-grained MoE architectures, and then visually studied the multilingual activation patterns of LLMs through expert activation frequency heatmaps. Through comprehensive experiments on different model families, different model sizes, and different variants, we analyzed the distribution of high-frequency activated experts, multilingual shared experts, whether the activation patterns of different languages are related to language families, and the impact of instruction tuning on activation patterns. We further explored leveraging the discovered differences in expert activation frequencies to guide unstructured pruning in two different ways. Experimental results demonstrated that our method significantly outperformed random expert pruning and even exceeded the performance of the original unpruned models in some languages. Additionally, we found that configuring different pruning rates for different layers based on activation level differences could achieve better results. Our findings reveal the multilingual processing mechanisms within LLMs and utilize these insights to offer new perspectives for applications such as model pruning.
Create account to get full access
Overview
- This paper explores the multilingual capabilities of large language models (LLMs) and how they handle activation patterns across different languages.
- The researchers investigate the presence of language-specific neurons and the role of feed-forward networks in driving multilingual behavior in LLMs.
- The study provides insights into the inner workings of LLMs and how they process and represent multiple languages simultaneously.
Plain English Explanation
The researchers set out to better understand how large language models (LLMs) like GPT-3 are able to handle multiple languages at the same time. Exploring Activation Patterns of Parameters in Language Models and How Do Large Language Models Handle Multilingualism? are two related papers that also explore this topic.
The key idea is that LLMs don't just have a single, monolithic understanding of language. Instead, they seem to develop specialized "neurons" or processing units that are particularly attuned to the unique features of different languages. For example, some neurons might be highly responsive to the grammar and sentence structure of English, while others are more tuned to handle the complex writing system of Chinese.
The researchers also found that the feed-forward neural networks within LLMs play a critical role in enabling this multilingual capability. These feed-forward networks, which sit alongside the more well-known transformer blocks, seem to be a key driver of the models' ability to fluidly switch between and understand multiple languages. Understanding the Role of FFNs in Driving Multilingual Behaviour in LLMs dives deeper into this finding.
Overall, this study provides fascinating insights into the inner workings of LLMs and how they are able to achieve such impressive multilingual performance. By unraveling the complex activation patterns and specialized language processing capabilities, the researchers are shedding light on the remarkable linguistic versatility of these advanced AI models.
Technical Explanation
The researchers conducted a series of experiments to investigate the multilingual activation patterns within large language models (LLMs). They focused on understanding the presence of language-specific neurons and the role of feed-forward networks in driving multilingual behavior.
Language-Specific Neurons: Key to Multilingual Capabilities was a key finding from the study. The researchers discovered that LLMs develop specialized processing units, or "neurons," that are particularly attuned to the unique features and characteristics of different languages. This suggests that LLMs don't have a single, monolithic understanding of language, but rather a nuanced, multilayered representation that allows them to handle multiple languages effectively.
Additionally, the study revealed the critical role of feed-forward neural networks (FFNs) in enabling multilingual capabilities within LLMs. Understanding the Role of FFNs in Driving Multilingual Behaviour in LLMs showed that these FFN layers, which sit alongside the more well-known transformer blocks, are a key component in allowing LLMs to fluidly switch between and understand multiple languages.
The researchers used a combination of techniques, including activation pattern analysis, language-specific probing, and targeted interventions, to uncover these insights. By delving into the inner workings of LLMs, the study provides a deeper understanding of how these powerful AI models are able to achieve such impressive multilingual performance.
Critical Analysis
The researchers acknowledge several limitations and areas for further research in their study. For example, they note that their analysis focused on a specific set of LLMs and languages, and it would be valuable to extend the investigation to a broader range of models and linguistic contexts.
Additionally, while the study provides compelling evidence for the presence of language-specific neurons and the critical role of feed-forward networks, the researchers suggest that more work is needed to fully elucidate the underlying mechanisms and the interplay between different model components. Multilingual Large Language Models: The Curse of Multilinguality highlights some of the challenges and trade-offs inherent in developing truly multilingual LLMs.
It's also important to consider the potential biases and limitations that may be present in the training data and model architectures used in this research. As with any AI system, there is a risk of amplifying societal biases or overlooking the nuances and complexities of language and culture.
Overall, this study offers valuable insights into the multilingual capabilities of LLMs, but further research and critical examination will be necessary to fully understand the implications and potential limitations of these findings.
Conclusion
This paper provides a fascinating exploration of the multilingual activation patterns within large language models (LLMs). The researchers have uncovered evidence of language-specific neurons and the critical role of feed-forward networks in enabling LLMs to effectively handle multiple languages simultaneously.
By delving into the inner workings of these advanced AI models, the study sheds light on the remarkable linguistic versatility and multilayered representations that underpin LLMs' impressive multilingual performance. The findings have important implications for our understanding of how language is processed and represented in AI systems, as well as the potential applications and limitations of these technologies.
As the field of natural language processing continues to evolve, research like this will be essential for unlocking the full potential of large language models while also addressing the challenges and ethical considerations that come with such powerful AI capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Language-Specific Neurons: The Key to Multilingual Capabilities in Large Language Models
Tianyi Tang, Wenyang Luo, Haoyang Huang, Dongdong Zhang, Xiaolei Wang, Xin Zhao, Furu Wei, Ji-Rong Wen
0
0
Large language models (LLMs) demonstrate remarkable multilingual capabilities without being pre-trained on specially curated multilingual parallel corpora. It remains a challenging problem to explain the underlying mechanisms by which LLMs process multilingual texts. In this paper, we delve into the composition of Transformer architectures in LLMs to pinpoint language-specific regions. Specially, we propose a novel detection method, language activation probability entropy (LAPE), to identify language-specific neurons within LLMs. Based on LAPE, we conduct comprehensive experiments on several representative LLMs, such as LLaMA-2, BLOOM, and Mistral. Our findings indicate that LLMs' proficiency in processing a particular language is predominantly due to a small subset of neurons, primarily situated in the models' top and bottom layers. Furthermore, we showcase the feasibility to steer the output language of LLMs by selectively activating or deactivating language-specific neurons. Our research provides important evidence to the understanding and exploration of the multilingual capabilities of LLMs.
6/7/2024
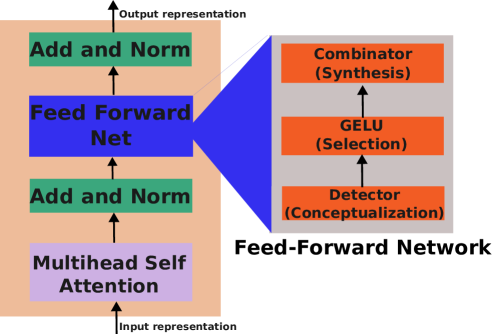
Understanding the role of FFNs in driving multilingual behaviour in LLMs
Sunit Bhattacharya, Ondv{r}ej Bojar
0
0
Multilingualism in Large Language Models (LLMs) is an yet under-explored area. In this paper, we conduct an in-depth analysis of the multilingual capabilities of a family of a Large Language Model, examining its architecture, activation patterns, and processing mechanisms across languages. We introduce novel metrics to probe the model's multilingual behaviour at different layers and shed light on the impact of architectural choices on multilingual processing. Our findings reveal different patterns of multilinugal processing in the sublayers of Feed-Forward Networks of the models. Furthermore, we uncover the phenomenon of over-layerization in certain model configurations, where increasing layer depth without corresponding adjustments to other parameters may degrade model performance. Through comparisons within and across languages, we demonstrate the interplay between model architecture, layer depth, and multilingual processing capabilities of LLMs trained on multiple languages.
4/23/2024

Exploring Activation Patterns of Parameters in Language Models
Yudong Wang, Damai Dai, Zhifang Sui
0
0
Most work treats large language models as black boxes without in-depth understanding of their internal working mechanism. In order to explain the internal representations of LLMs, we propose a gradient-based metric to assess the activation level of model parameters. Based on this metric, we obtain three preliminary findings. (1) When the inputs are in the same domain, parameters in the shallow layers will be activated densely, which means a larger portion of parameters will have great impacts on the outputs. In contrast, parameters in the deep layers are activated sparsely. (2) When the inputs are across different domains, parameters in shallow layers exhibit higher similarity in the activation behavior than deep layers. (3) In deep layers, the similarity of the distributions of activated parameters is positively correlated to the empirical data relevance. Further, we develop three validation experiments to solidify these findings. (1) Firstly, starting from the first finding, we attempt to configure different prune ratios for different layers, and find this method can benefit model pruning. (2) Secondly, we find that a pruned model based on one calibration set can better handle tasks related to the calibration task than those not related, which validate the second finding. (3) Thirdly, Based on the STS-B and SICK benchmark, we find that two sentences with consistent semantics tend to share similar parameter activation patterns in deep layers, which aligns with our third finding. Our work sheds light on the behavior of parameter activation in LLMs, and we hope these findings will have the potential to inspire more practical applications.
5/29/2024
How do Large Language Models Handle Multilingualism?
Yiran Zhao, Wenxuan Zhang, Guizhen Chen, Kenji Kawaguchi, Lidong Bing
0
0
Large language models (LLMs) have demonstrated impressive capabilities across diverse languages. This study explores how LLMs handle multilingualism. Based on observed language ratio shifts among layers and the relationships between network structures and certain capabilities, we hypothesize the LLM's multilingual workflow ($texttt{MWork}$): LLMs initially understand the query, converting multilingual inputs into English for task-solving. In the intermediate layers, they employ English for thinking and incorporate multilingual knowledge with self-attention and feed-forward structures, respectively. In the final layers, LLMs generate responses aligned with the original language of the query. To verify $texttt{MWork}$, we introduce Parallel Language-specific Neuron Detection ($texttt{PLND}$) to identify activated neurons for inputs in different languages without any labeled data. Using $texttt{PLND}$, we validate $texttt{MWork}$ through extensive experiments involving the deactivation of language-specific neurons across various layers and structures. Moreover, $texttt{MWork}$ allows fine-tuning of language-specific neurons with a small dataset, enhancing multilingual abilities in a specific language without compromising others. This approach results in an average improvement of $3.6%$ for high-resource languages and $2.3%$ for low-resource languages across all tasks with just $400$ documents.
5/27/2024