How do Large Language Models Handle Multilingualism?
2402.18815
0
0
Abstract
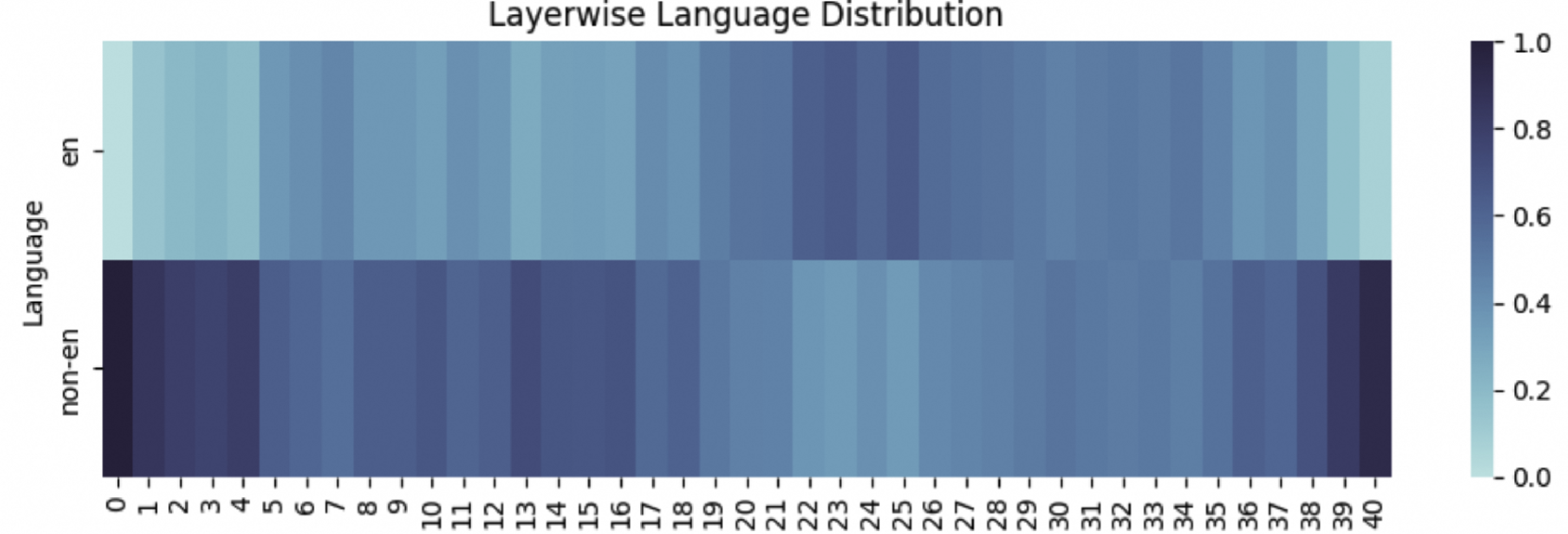
Large language models (LLMs) have demonstrated impressive capabilities across diverse languages. This study explores how LLMs handle multilingualism. Based on observed language ratio shifts among layers and the relationships between network structures and certain capabilities, we hypothesize the LLM's multilingual workflow ($texttt{MWork}$): LLMs initially understand the query, converting multilingual inputs into English for task-solving. In the intermediate layers, they employ English for thinking and incorporate multilingual knowledge with self-attention and feed-forward structures, respectively. In the final layers, LLMs generate responses aligned with the original language of the query. To verify $texttt{MWork}$, we introduce Parallel Language-specific Neuron Detection ($texttt{PLND}$) to identify activated neurons for inputs in different languages without any labeled data. Using $texttt{PLND}$, we validate $texttt{MWork}$ through extensive experiments involving the deactivation of language-specific neurons across various layers and structures. Moreover, $texttt{MWork}$ allows fine-tuning of language-specific neurons with a small dataset, enhancing multilingual abilities in a specific language without compromising others. This approach results in an average improvement of $3.6%$ for high-resource languages and $2.3%$ for low-resource languages across all tasks with just $400$ documents.
Create account to get full access
Overview
- This paper investigates how large language models (LLMs) handle multilingualism, a key capability as these models are deployed globally.
- The authors propose a new technique called Parallel Language-specific Neuron Detection (PLND) to identify language-specific neurons in LLMs.
- The paper explores the role of feed-forward neural networks (FFNs) in driving multilingual behavior in LLMs and provides a survey of multilingual LLM resources and research.
Plain English Explanation
The paper examines how large language models (LLMs) - powerful AI systems that can understand and generate human-like text - handle the ability to work with multiple languages. This is an important capability as these models are being used more and more around the world.
The researchers developed a new method called Parallel Language-specific Neuron Detection (PLND) to identify the specific neurons, or processing units, in LLMs that are responsible for each language. This helps us better understand how LLMs are able to switch between languages.
The paper also looks at the role of feed-forward neural networks (FFNs) - a key component of LLMs - in enabling their multilingual abilities. Additionally, the researchers provide an overview of the resources and research available on multilingual LLMs.
By understanding how LLMs handle multiple languages, we can improve these powerful AI systems to work more effectively across global audiences and applications.
Technical Explanation
The paper introduces a new technique called Parallel Language-specific Neuron Detection (PLND) to identify language-specific neurons in large language models (LLMs). This builds on prior work that used a sequential neuron detection approach.
The PLND method involves training multiple classifiers in parallel, each tasked with detecting neurons that are specific to a particular language. This allows the researchers to efficiently identify the neurons that are most important for each language, rather than relying on a single sequential process.
The paper also examines the role of feed-forward neural networks (FFNs) in enabling the multilingual capabilities of LLMs. FFNs are a key component of these models, and the authors provide insights into how they contribute to the models' ability to switch between languages.
Finally, the researchers present a survey of multilingual LLM resources and research, including datasets, benchmarks, and other related work in this area. This provides a useful overview of the current state of the field.
Critical Analysis
The paper makes a valuable contribution to the understanding of how large language models (LLMs) handle multilingualism. The proposed Parallel Language-specific Neuron Detection (PLND) technique is a novel approach that could lead to more efficient and accurate identification of language-specific neurons in these models.
However, the paper does not address some potential limitations of the PLND method. For example, it is unclear how well the technique would scale to models with a larger number of languages, or how sensitive it might be to differences in language complexity or data availability.
Additionally, while the paper provides a useful survey of multilingual LLM resources and research, it does not delve deeply into the specific challenges and trade-offs involved in developing truly multilingual LLMs. Further exploration of these issues could help inform the ongoing development of these powerful AI systems.
Overall, this paper makes an important contribution to the field, but there are opportunities for additional research to build upon its findings and address remaining questions.
Conclusion
This paper presents a novel technique called Parallel Language-specific Neuron Detection (PLND) for identifying language-specific neurons in large language models (LLMs). The authors also explore the role of feed-forward neural networks (FFNs) in enabling the multilingual capabilities of these models and provide a comprehensive survey of multilingual LLM resources and research.
By better understanding how LLMs handle multiple languages, we can improve their performance and make them more accessible to diverse global audiences. This research represents an important step forward in the development of truly multilingual AI systems, with the potential to have a significant impact on a wide range of applications and industries.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Language-Specific Neurons: The Key to Multilingual Capabilities in Large Language Models
Tianyi Tang, Wenyang Luo, Haoyang Huang, Dongdong Zhang, Xiaolei Wang, Xin Zhao, Furu Wei, Ji-Rong Wen
0
0
Large language models (LLMs) demonstrate remarkable multilingual capabilities without being pre-trained on specially curated multilingual parallel corpora. It remains a challenging problem to explain the underlying mechanisms by which LLMs process multilingual texts. In this paper, we delve into the composition of Transformer architectures in LLMs to pinpoint language-specific regions. Specially, we propose a novel detection method, language activation probability entropy (LAPE), to identify language-specific neurons within LLMs. Based on LAPE, we conduct comprehensive experiments on several representative LLMs, such as LLaMA-2, BLOOM, and Mistral. Our findings indicate that LLMs' proficiency in processing a particular language is predominantly due to a small subset of neurons, primarily situated in the models' top and bottom layers. Furthermore, we showcase the feasibility to steer the output language of LLMs by selectively activating or deactivating language-specific neurons. Our research provides important evidence to the understanding and exploration of the multilingual capabilities of LLMs.
6/7/2024
A Survey on Multilingual Large Language Models: Corpora, Alignment, and Bias
Yuemei Xu, Ling Hu, Jiayi Zhao, Zihan Qiu, Yuqi Ye, Hanwen Gu
0
0
Based on the foundation of Large Language Models (LLMs), Multilingual Large Language Models (MLLMs) have been developed to address the challenges of multilingual natural language processing tasks, hoping to achieve knowledge transfer from high-resource to low-resource languages. However, significant limitations and challenges still exist, such as language imbalance, multilingual alignment, and inherent bias. In this paper, we aim to provide a comprehensive analysis of MLLMs, delving deeply into discussions surrounding these critical issues. First of all, we start by presenting an overview of MLLMs, covering their evolution, key techniques, and multilingual capacities. Secondly, we explore widely utilized multilingual corpora for MLLMs' training and multilingual datasets oriented for downstream tasks that are crucial for enhancing the cross-lingual capability of MLLMs. Thirdly, we survey the existing studies on multilingual representations and investigate whether the current MLLMs can learn a universal language representation. Fourthly, we discuss bias on MLLMs including its category and evaluation metrics, and summarize the existing debiasing techniques. Finally, we discuss existing challenges and point out promising research directions. By demonstrating these aspects, this paper aims to facilitate a deeper understanding of MLLMs and their potentiality in various domains.
6/7/2024
A Survey on Large Language Models with Multilingualism: Recent Advances and New Frontiers
Kaiyu Huang, Fengran Mo, Hongliang Li, You Li, Yuanchi Zhang, Weijian Yi, Yulong Mao, Jinchen Liu, Yuzhuang Xu, Jinan Xu, Jian-Yun Nie, Yang Liu
0
0
The rapid development of Large Language Models (LLMs) demonstrates remarkable multilingual capabilities in natural language processing, attracting global attention in both academia and industry. To mitigate potential discrimination and enhance the overall usability and accessibility for diverse language user groups, it is important for the development of language-fair technology. Despite the breakthroughs of LLMs, the investigation into the multilingual scenario remains insufficient, where a comprehensive survey to summarize recent approaches, developments, limitations, and potential solutions is desirable. To this end, we provide a survey with multiple perspectives on the utilization of LLMs in the multilingual scenario. We first rethink the transitions between previous and current research on pre-trained language models. Then we introduce several perspectives on the multilingualism of LLMs, including training and inference methods, model security, multi-domain with language culture, and usage of datasets. We also discuss the major challenges that arise in these aspects, along with possible solutions. Besides, we highlight future research directions that aim at further enhancing LLMs with multilingualism. The survey aims to help the research community address multilingual problems and provide a comprehensive understanding of the core concepts, key techniques, and latest developments in multilingual natural language processing based on LLMs.
5/20/2024
💬
Investigating the translation capabilities of Large Language Models trained on parallel data only
Javier Garc'ia Gilabert, Carlos Escolano, Aleix Sant Savall, Francesca De Luca Fornaciari, Audrey Mash, Xixian Liao, Maite Melero
0
0
In recent years, Large Language Models (LLMs) have demonstrated exceptional proficiency across a broad spectrum of Natural Language Processing (NLP) tasks, including Machine Translation. However, previous methods predominantly relied on iterative processes such as instruction fine-tuning or continual pre-training, leaving unexplored the challenges of training LLMs solely on parallel data. In this work, we introduce PLUME (Parallel Language Model), a collection of three 2B LLMs featuring varying vocabulary sizes (32k, 128k, and 256k) trained exclusively on Catalan-centric parallel examples. These models perform comparably to previous encoder-decoder architectures on 16 supervised translation directions and 56 zero-shot ones. Utilizing this set of models, we conduct a thorough investigation into the translation capabilities of LLMs, probing their performance, the impact of the different elements of the prompt, and their cross-lingual representation space.
6/14/2024