Language-Specific Neurons: The Key to Multilingual Capabilities in Large Language Models
2402.16438
0
0

Abstract
Large language models (LLMs) demonstrate remarkable multilingual capabilities without being pre-trained on specially curated multilingual parallel corpora. It remains a challenging problem to explain the underlying mechanisms by which LLMs process multilingual texts. In this paper, we delve into the composition of Transformer architectures in LLMs to pinpoint language-specific regions. Specially, we propose a novel detection method, language activation probability entropy (LAPE), to identify language-specific neurons within LLMs. Based on LAPE, we conduct comprehensive experiments on several representative LLMs, such as LLaMA-2, BLOOM, and Mistral. Our findings indicate that LLMs' proficiency in processing a particular language is predominantly due to a small subset of neurons, primarily situated in the models' top and bottom layers. Furthermore, we showcase the feasibility to steer the output language of LLMs by selectively activating or deactivating language-specific neurons. Our research provides important evidence to the understanding and exploration of the multilingual capabilities of LLMs.
Create account to get full access
Overview
- The research paper explores the concept of "language-specific neurons" in large language models (LLMs) and their role in enabling multilingual capabilities.
- It investigates how LLMs can effectively process and generate text in multiple languages by identifying language-specific regions within the model's neural architecture.
- The findings have implications for improving the multilingual abilities of LLMs and advancing the field of natural language processing.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. One key challenge in developing LLMs is enabling them to work effectively in multiple languages, a capability known as multilingualism.
This research paper suggests that the key to multilingual LLMs may lie in the concept of "language-specific neurons." The researchers hypothesize that certain neurons or groups of neurons within the LLM's neural network are specialized for processing particular languages. By identifying and understanding these language-specific regions, the researchers believe they can unlock the multilingual potential of LLMs.
The paper explores methods for identifying these language-specific regions and investigates how they contribute to a model's ability to handle multiple languages. For example, the researchers may look at how the model's performance changes when certain neurons are selectively activated or deactivated for different languages.
By shedding light on the inner workings of LLMs and the role of language-specific neurons, this research could lead to significant advancements in the development of multilingual AI systems. This would have far-reaching implications, enabling LLMs to communicate more effectively across language barriers and potentially improving applications in fields like machine translation, multilingual customer service, and global business communications.
Technical Explanation
The paper begins by establishing the importance of multilingual capabilities in large language models (LLMs). The researchers hypothesize that the key to enabling this multilingualism lies in the identification and understanding of "language-specific neurons" within the LLM's neural architecture.
To investigate this hypothesis, the researchers design experiments to isolate and analyze the language-specific regions of the model. This involves techniques such as selectively masking or activating certain neurons to observe their impact on the model's performance in different languages.
The findings suggest that LLMs do indeed contain language-specific neurons or neural clusters that are particularly responsive to specific languages. By understanding the role of these language-specific regions, the researchers believe they can unlock new strategies for improving the multilingual capabilities of LLMs.
For example, the researchers explore how the model's architecture, particularly the feed-forward neural networks (FFNs), contributes to its multilingual behavior. They also investigate the alignment of the model's internal representations with different languages, which may provide insights into the mechanisms underlying multilingual processing.
Critical Analysis
The research presented in this paper offers a promising approach to understanding and enhancing the multilingual capabilities of large language models. By focusing on the identification and analysis of language-specific neurons, the researchers provide a novel perspective on the inner workings of these complex AI systems.
However, it is important to note that the research is still in its early stages, and there may be limitations or caveats to the findings. For example, the experiments may have been conducted on a specific LLM or dataset, and the generalizability of the results to other models or languages may require further investigation.
Additionally, while the identification of language-specific neurons is a valuable contribution, the practical implications of this knowledge for improving multilingual LLMs are not yet fully clear. The researchers acknowledge the need for further research to translate these insights into tangible advancements in model architecture and training approaches.
It would also be interesting to see the researchers explore the potential trade-offs or synergies between language-specific and language-agnostic representations within the LLM. Understanding the balance and interplay between these different modes of processing could yield additional insights into the nature of multilingual intelligence in artificial systems.
Conclusion
The research presented in this paper represents an important step forward in our understanding of the multilingual capabilities of large language models. By identifying and analyzing the role of language-specific neurons, the researchers have uncovered a novel perspective on the inner workings of these powerful AI systems.
The findings have significant implications for the future development of multilingual LLMs, which are crucial for bridging language barriers and enabling more effective global communication and collaboration. As the field of natural language processing continues to evolve, this research paves the way for new strategies and architectural innovations that could unlock the full potential of LLMs in multilingual contexts.
While the work is still in its early stages, the insights gained from this paper lay the groundwork for further exploration and refinement. By continuing to push the boundaries of our understanding of multilingual AI, researchers can contribute to the creation of more versatile, inclusive, and impactful language technologies that benefit people and societies around the world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
How do Large Language Models Handle Multilingualism?
Yiran Zhao, Wenxuan Zhang, Guizhen Chen, Kenji Kawaguchi, Lidong Bing
0
0
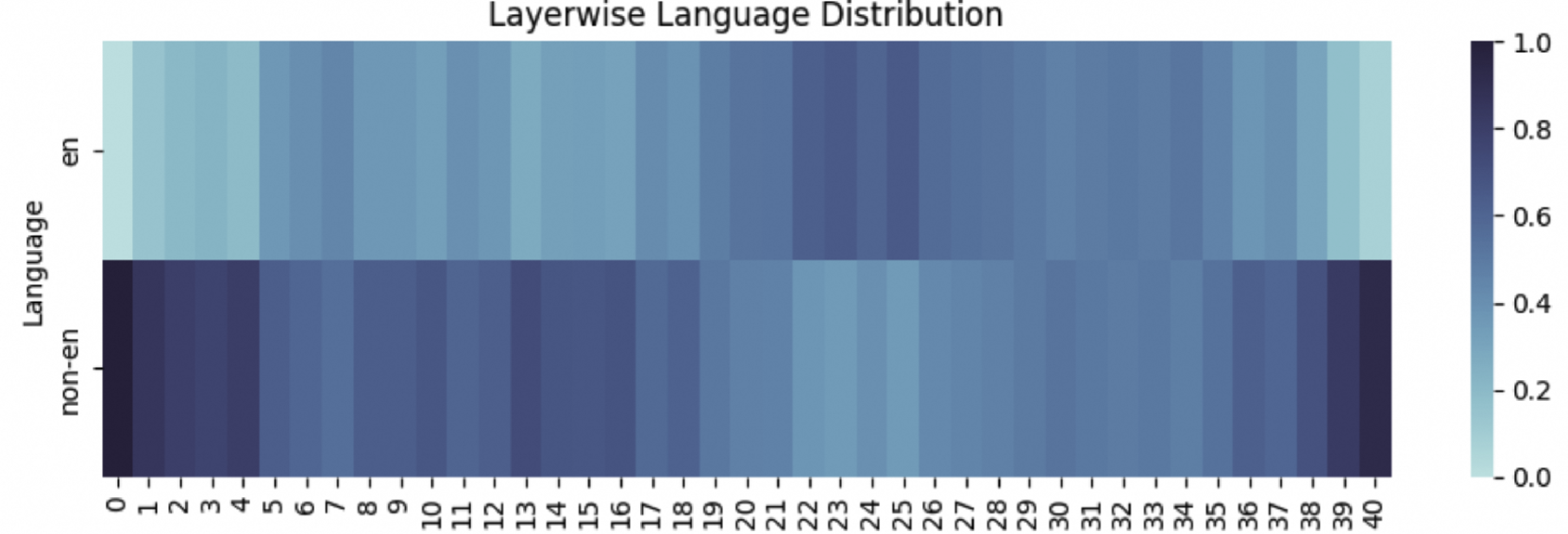
Large language models (LLMs) have demonstrated impressive capabilities across diverse languages. This study explores how LLMs handle multilingualism. Based on observed language ratio shifts among layers and the relationships between network structures and certain capabilities, we hypothesize the LLM's multilingual workflow ($texttt{MWork}$): LLMs initially understand the query, converting multilingual inputs into English for task-solving. In the intermediate layers, they employ English for thinking and incorporate multilingual knowledge with self-attention and feed-forward structures, respectively. In the final layers, LLMs generate responses aligned with the original language of the query. To verify $texttt{MWork}$, we introduce Parallel Language-specific Neuron Detection ($texttt{PLND}$) to identify activated neurons for inputs in different languages without any labeled data. Using $texttt{PLND}$, we validate $texttt{MWork}$ through extensive experiments involving the deactivation of language-specific neurons across various layers and structures. Moreover, $texttt{MWork}$ allows fine-tuning of language-specific neurons with a small dataset, enhancing multilingual abilities in a specific language without compromising others. This approach results in an average improvement of $3.6%$ for high-resource languages and $2.3%$ for low-resource languages across all tasks with just $400$ documents.
5/27/2024
On the Multilingual Ability of Decoder-based Pre-trained Language Models: Finding and Controlling Language-Specific Neurons
Takeshi Kojima, Itsuki Okimura, Yusuke Iwasawa, Hitomi Yanaka, Yutaka Matsuo
0
0
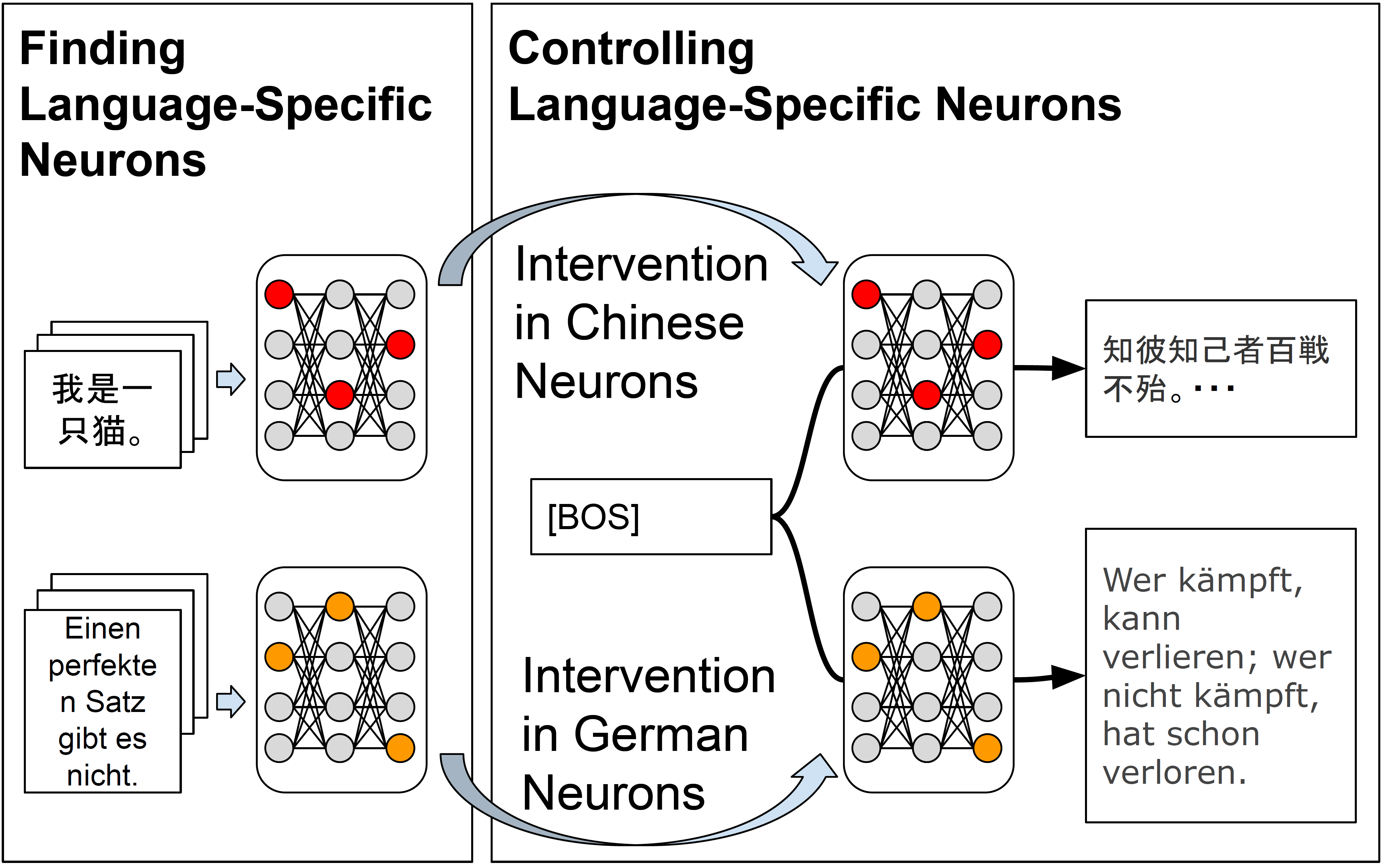
Current decoder-based pre-trained language models (PLMs) successfully demonstrate multilingual capabilities. However, it is unclear how these models handle multilingualism. We analyze the neuron-level internal behavior of multilingual decoder-based PLMs, Specifically examining the existence of neurons that fire ``uniquely for each language'' within decoder-only multilingual PLMs. We analyze six languages: English, German, French, Spanish, Chinese, and Japanese, and show that language-specific neurons are unique, with a slight overlap (< 5%) between languages. These neurons are mainly distributed in the models' first and last few layers. This trend remains consistent across languages and models. Additionally, we tamper with less than 1% of the total neurons in each model during inference and demonstrate that tampering with a few language-specific neurons drastically changes the probability of target language occurrence in text generation.
4/4/2024
Sharing Matters: Analysing Neurons Across Languages and Tasks in LLMs
Weixuan Wang, Barry Haddow, Wei Peng, Alexandra Birch
0
0
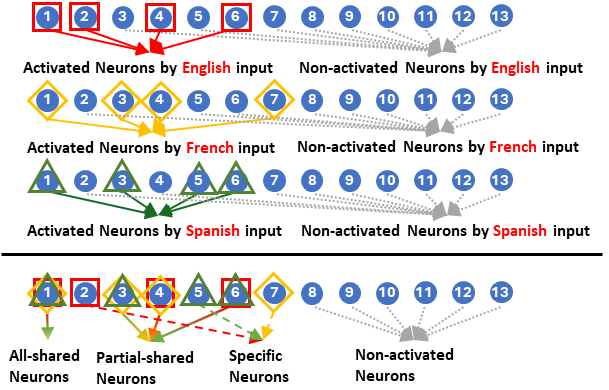
Multilingual large language models (LLMs) have greatly increased the ceiling of performance on non-English tasks. However the mechanisms behind multilingualism in these LLMs are poorly understood. Of particular interest is the degree to which internal representations are shared between languages. Recent work on neuron analysis of LLMs has focused on the monolingual case, and the limited work on the multilingual case has not considered the interaction between tasks and linguistic representations. In our work, we investigate how neuron activation is shared across languages by categorizing neurons into four distinct groups according to their responses across different languages for a particular input: all-shared, partial-shared, specific, and non-activated. This categorization is combined with a study of neuron attribution, i.e. the importance of a neuron w.r.t an output. Our analysis reveals the following insights: (i) the linguistic sharing patterns are strongly affected by the type of task, but neuron behaviour changes across different inputs even for the same task; (ii) all-shared neurons play a key role in generating correct responses; (iii) boosting multilingual alignment by increasing all-shared neurons can enhance accuracy on multilingual tasks. The code is available at https://github.com/weixuan-wang123/multilingual-neurons.
6/14/2024

Unraveling Babel: Exploring Multilingual Activation Patterns of LLMs and Their Applications
Weize Liu, Yinlong Xu, Hongxia Xu, Jintai Chen, Xuming Hu, Jian Wu
0
0
Recently, large language models (LLMs) have achieved tremendous breakthroughs in the field of NLP, but still lack understanding of their internal activities when processing different languages. We designed a method to convert dense LLMs into fine-grained MoE architectures, and then visually studied the multilingual activation patterns of LLMs through expert activation frequency heatmaps. Through comprehensive experiments on different model families, different model sizes, and different variants, we analyzed the distribution of high-frequency activated experts, multilingual shared experts, whether the activation patterns of different languages are related to language families, and the impact of instruction tuning on activation patterns. We further explored leveraging the discovered differences in expert activation frequencies to guide unstructured pruning in two different ways. Experimental results demonstrated that our method significantly outperformed random expert pruning and even exceeded the performance of the original unpruned models in some languages. Additionally, we found that configuring different pruning rates for different layers based on activation level differences could achieve better results. Our findings reveal the multilingual processing mechanisms within LLMs and utilize these insights to offer new perspectives for applications such as model pruning.
6/19/2024