UnSeenTimeQA: Time-Sensitive Question-Answering Beyond LLMs' Memorization

0
✨
Sign in to get full access
Overview
- This paper introduces a new benchmark called UnSeenTimeQA for evaluating time-sensitive question-answering (TSQA) capabilities of large language models (LLMs).
- Unlike traditional TSQA benchmarks, UnSeenTimeQA presents time-sensitive event scenarios that are decoupled from real-world factual information.
- This requires LLMs to engage in genuine temporal reasoning, rather than relying on pre-trained knowledge.
- The paper evaluates the performance of several open-source and closed-source LLMs on the UnSeenTimeQA benchmark, revealing substantial challenges in handling complex temporal reasoning scenarios.
Plain English Explanation
The paper introduces a new evaluation benchmark called UnSeenTimeQA that tests the time-sensitive question-answering (TSQA) abilities of large language models (LLMs). Unlike previous TSQA benchmarks, UnSeenTimeQA presents questions about fictional time-sensitive events that are not directly connected to real-world facts.
This means LLMs cannot simply rely on their pre-existing knowledge to answer the questions. Instead, they must engage in deeper temporal reasoning to understand the relationships between events and timeline information. The paper evaluates the performance of several open-source and closed-source LLMs on the UnSeenTimeQA benchmark, and the results show that the models struggle with these types of complex time-sensitive questions.
The key idea is to push LLMs beyond their current capabilities by separating TSQA from factual knowledge. This reveals limitations in their ability to reason about temporal information in a more abstract and flexible way, rather than just retrieving facts.
Technical Explanation
The paper introduces a new TSQA benchmark called UnSeenTimeQA that moves beyond traditional TSQA tasks. Instead of asking questions tied to real-world facts, UnSeenTimeQA presents fictional time-sensitive event scenarios. This requires large language models (LLMs) to engage in genuine temporal reasoning, rather than relying on pre-trained knowledge.
The authors evaluate the performance of six open-source LLMs (ranging from 2 billion to 70 billion parameters) and three closed-source LLMs on the UnSeenTimeQA benchmark. The results reveal that the models struggle significantly with the time-sensitive questions, indicating limitations in their ability to handle complex temporal reasoning tasks.
The paper also presents several analyses to better understand the models' strengths and weaknesses in answering time-sensitive questions. These insights shed light on the challenges LLMs face when attempting to reason about temporal information in a more abstract and flexible way, rather than simply retrieving factual information.
Critical Analysis
The UnSeenTimeQA benchmark introduced in this paper represents an important step forward in evaluating the temporal reasoning capabilities of large language models (LLMs). By decoupling the questions from real-world facts, the authors have created a more challenging and insightful test of the models' true understanding of time-sensitive information.
However, one potential limitation of the benchmark is the reliance on fictional event scenarios. While this approach tests the models' ability to reason about temporal relationships in a more abstract way, it may not fully capture how LLMs would perform on real-world time-sensitive tasks. It would be valuable to explore additional benchmarks that incorporate a mix of factual and fictional time-sensitive information.
Furthermore, the paper does not delve deeply into the underlying reasons for the models' poor performance on the UnSeenTimeQA benchmark. A more thorough investigation of the specific temporal reasoning challenges faced by LLMs could provide valuable insights for improving their capabilities in this area.
Overall, the UnSeenTimeQA benchmark represents an important contribution to the field of TSQA and highlights the need for continued research to advance the temporal reasoning abilities of large language models.
Conclusion
This paper introduces a novel time-sensitive question-answering (TSQA) benchmark called UnSeenTimeQA that challenges large language models (LLMs) to engage in genuine temporal reasoning, rather than relying on pre-trained factual knowledge.
The evaluation of several open-source and closed-source LLMs on the UnSeenTimeQA benchmark reveals substantial difficulties in handling the complex time-sensitive questions, indicating limitations in the models' current abilities to reason about temporal information in an abstract and flexible way.
The insights from this research highlight the need for continued advancements in the field of TSQA and could inspire further developments in LLM architectures and training approaches to improve their temporal reasoning capabilities. By pushing the boundaries of what LLMs can do, benchmarks like UnSeenTimeQA can help drive progress in the field of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✨
0
UnSeenTimeQA: Time-Sensitive Question-Answering Beyond LLMs' Memorization
Md Nayem Uddin, Amir Saeidi, Divij Handa, Agastya Seth, Tran Cao Son, Eduardo Blanco, Steven R. Corman, Chitta Baral
This paper introduces UnSeenTimeQA, a novel time-sensitive question-answering (TSQA) benchmark that diverges from traditional TSQA benchmarks by avoiding factual and web-searchable queries. We present a series of time-sensitive event scenarios decoupled from real-world factual information. It requires large language models (LLMs) to engage in genuine temporal reasoning, disassociating from the knowledge acquired during the pre-training phase. Our evaluation of six open-source LLMs (ranging from 2B to 70B in size) and three closed-source LLMs reveal that the questions from the UnSeenTimeQA present substantial challenges. This indicates the models' difficulties in handling complex temporal reasoning scenarios. Additionally, we present several analyses shedding light on the models' performance in answering time-sensitive questions.
Read more7/8/2024

0
Enhancing Temporal Sensitivity and Reasoning for Time-Sensitive Question Answering
Wanqi Yang, Yanda Li, Meng Fang, Ling Chen
Time-Sensitive Question Answering (TSQA) demands the effective utilization of specific temporal contexts, encompassing multiple time-evolving facts, to address time-sensitive questions. This necessitates not only the parsing of temporal information within questions but also the identification and understanding of time-evolving facts to generate accurate answers. However, current large language models still have limited sensitivity to temporal information and their inadequate temporal reasoning capabilities.In this paper, we propose a novel framework that enhances temporal awareness and reasoning through Temporal Information-Aware Embedding and Granular Contrastive Reinforcement Learning. Experimental results on four TSQA datasets demonstrate that our framework significantly outperforms existing LLMs in TSQA tasks, marking a step forward in bridging the performance gap between machine and human temporal understanding and reasoning.
Read more9/26/2024

0
Continual Learning for Temporal-Sensitive Question Answering
Wanqi Yang, Yunqiu Xu, Yanda Li, Kunze Wang, Binbin Huang, Ling Chen
In this study, we explore an emerging research area of Continual Learning for Temporal Sensitive Question Answering (CLTSQA). Previous research has primarily focused on Temporal Sensitive Question Answering (TSQA), often overlooking the unpredictable nature of future events. In real-world applications, it's crucial for models to continually acquire knowledge over time, rather than relying on a static, complete dataset. Our paper investigates strategies that enable models to adapt to the ever-evolving information landscape, thereby addressing the challenges inherent in CLTSQA. To support our research, we first create a novel dataset, divided into five subsets, designed specifically for various stages of continual learning. We then propose a training framework for CLTSQA that integrates temporal memory replay and temporal contrastive learning. Our experimental results highlight two significant insights: First, the CLTSQA task introduces unique challenges for existing models. Second, our proposed framework effectively navigates these challenges, resulting in improved performance.
Read more7/18/2024
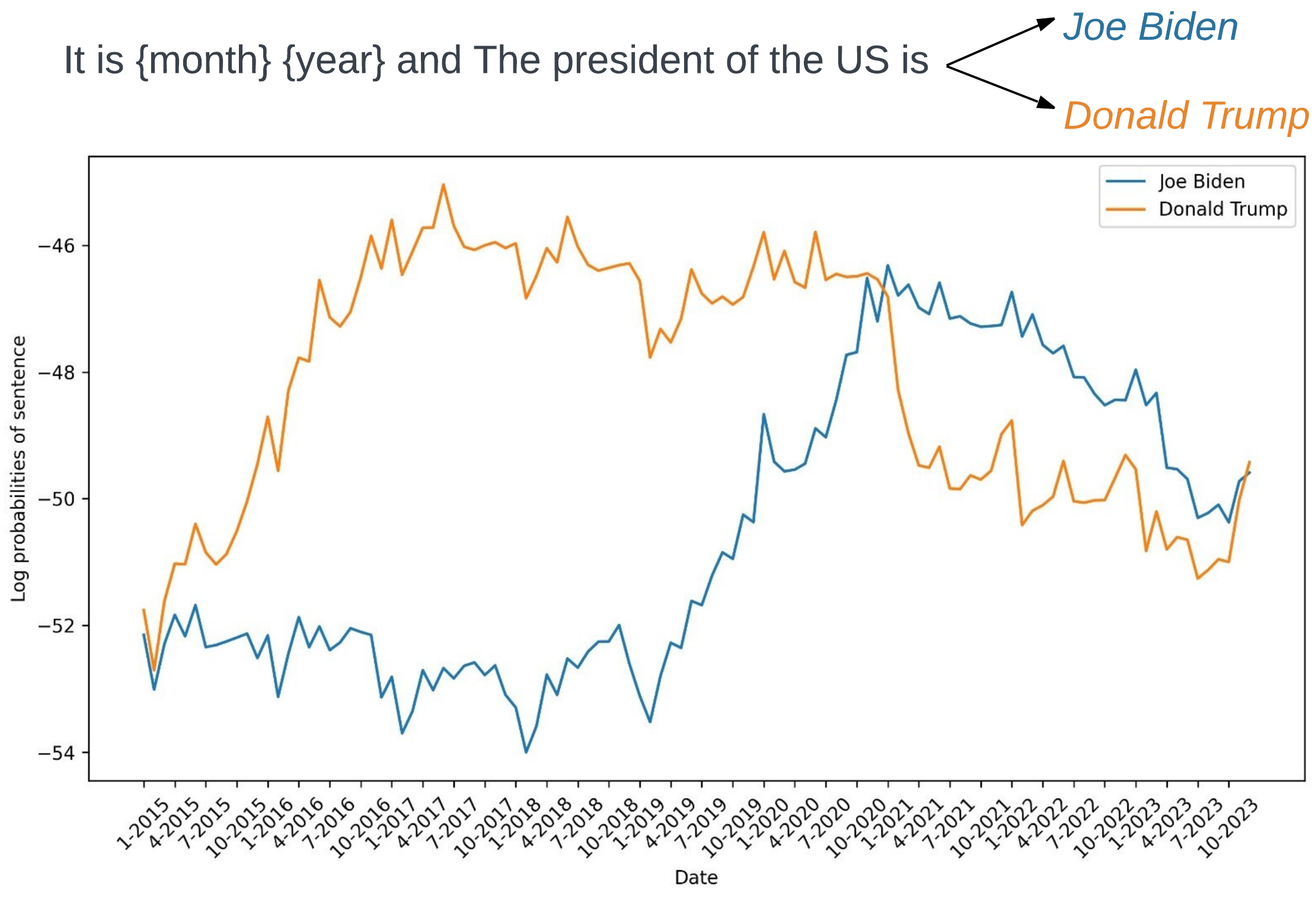
0
Time Awareness in Large Language Models: Benchmarking Fact Recall Across Time
David Herel, Vojtech Bartek, Tomas Mikolov
Who is the US President? The answer changes depending on when the question is asked. While large language models (LLMs) are evaluated on various reasoning tasks, they often miss a crucial dimension: time. In real-world scenarios, the correctness of answers is frequently tied to temporal context. In this paper, we introduce a novel dataset designed to rigorously test LLMs' ability to handle time-sensitive facts. Our benchmark offers a systematic way to measure how well LLMs align their knowledge with the correct time context, filling a key gap in current evaluation methods and offering a valuable tool for improving real-world applicability in future models.
Read more9/23/2024