Time Awareness in Large Language Models: Benchmarking Fact Recall Across Time

0
Sign in to get full access
Overview
- This paper examines the temporal reasoning abilities of large language models (LLMs), specifically their ability to recall facts from different time periods.
- The researchers developed a new benchmark called TimeBERT to assess LLMs' temporal fact retrieval performance.
- They tested several popular LLMs, including GPT-3, BERT, and RoBERTa, on this benchmark and found significant differences in their temporal awareness.
Plain English Explanation
One of the key capabilities we expect from advanced AI systems like large language models (LLMs) is their ability to understand and reason about events that happen over time. For example, if we ask an LLM about historical facts, we would hope it could accurately recall information from the correct time period, rather than mixing up details from different eras.
The researchers in this paper wanted to carefully evaluate how well current LLMs can actually do this type of temporal reasoning. They created a new benchmark called TimeBERT that tests an LLM's ability to recall specific facts about events, people, and information from different years in the past.
By applying this benchmark to popular LLMs like GPT-3, BERT, and RoBERTa, the researchers found that these models can have quite varying levels of temporal awareness. Some performed well at recalling facts from the correct time periods, while others showed significant confusion, mixing up details from different years.
This suggests that temporal reasoning is an important capability that current LLMs have not yet fully mastered. Improving an AI system's understanding of when events occurred and its ability to reason about change over time could be an important area for future research and development.
Technical Explanation
The core of this paper is the introduction of a new benchmark called TimeBERT, which the researchers developed to assess large language models' (LLMs') temporal reasoning abilities. TimeBERT tests an LLM's ability to accurately recall facts about events, people, and information from different years in the past.
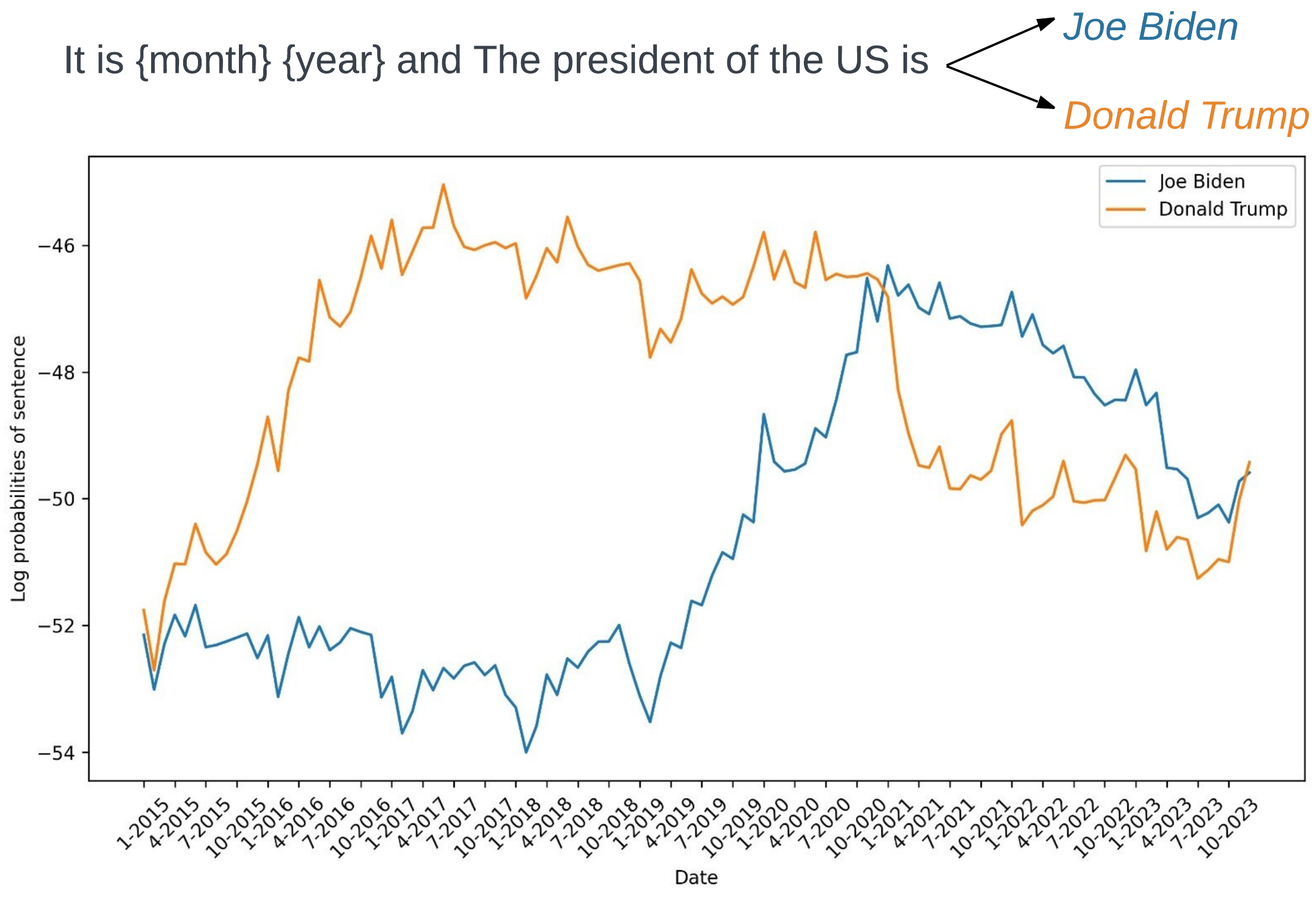
The benchmark consists of a set of prompts that ask the LLM to provide specific details about a given entity or event, along with the year it occurred. For example, a prompt might ask "What is the capital of France in 1789?" or "Who was the president of the United States in 1962?"
The researchers then evaluated the performance of several popular LLMs on this benchmark, including GPT-3, BERT, and RoBERTa. They found significant differences in how well these models were able to correctly recall facts from the appropriate time periods, with some models demonstrating much stronger temporal awareness than others.
The paper provides a detailed analysis of the results, identifying specific patterns and types of errors made by the different LLMs. It also discusses potential reasons for these differences, such as the models' training data and architectural differences.
Overall, this work highlights the importance of temporal reasoning as a capability for advanced AI systems and suggests that current LLMs may still have room for improvement when it comes to understanding and reasoning about events that occur over time.
Critical Analysis
The TimeBERT benchmark developed in this paper represents an important step forward in evaluating the temporal reasoning abilities of large language models. By focusing specifically on the recall of facts from different time periods, the researchers have identified a key dimension of LLM performance that is not always captured by more general language understanding evaluations.
That said, the paper acknowledges several limitations of the TimeBERT benchmark and the experiments conducted. For example, the prompts used in the benchmark may not fully capture the nuances of how humans integrate temporal information when answering questions. Additionally, the dataset used to construct the benchmark was primarily focused on North American and European history, so the findings may not generalize as well to other cultural and geographic contexts.
The paper also does not delve deeply into the potential reasons why some LLMs performed better than others on the temporal reasoning tasks. While it offers some high-level hypotheses, a more detailed investigation into the architectural differences, training data, and other factors that contribute to temporal awareness could be a valuable area for future research.
Finally, while the paper demonstrates significant differences in temporal reasoning abilities across LLMs, it does not assess the real-world impact of these differences. Further work is needed to understand how these limitations in temporal awareness might manifest in practical applications of these models, and what the implications could be for domains where accurate temporal reasoning is critical.
Overall, this paper provides an important new benchmark for evaluating a crucial capability of large language models. The findings highlight the need for continued progress in developing AI systems that can truly understand and reason about events and information in the context of time.
Conclusion
This paper presents a novel benchmark called TimeBERT that evaluates the temporal reasoning abilities of large language models (LLMs). By testing an LLM's capacity to accurately recall facts from different time periods, the researchers have uncovered significant differences in the temporal awareness of popular models like GPT-3, BERT, and RoBERTa.
These findings suggest that temporal reasoning is an important capability that current LLMs have not yet fully mastered. Improving an AI system's understanding of when events occurred and its ability to reason about change over time could be a crucial area for future research and development in the field of natural language processing.
The TimeBERT benchmark represents an important step forward in assessing this aspect of LLM performance. While the paper acknowledges several limitations, it highlights the need for continued progress in creating AI systems that can truly understand and reason about the world in the context of time. As these technologies become more deeply integrated into various applications, ensuring robust temporal awareness will be crucial for their real-world effectiveness and impact.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Time Awareness in Large Language Models: Benchmarking Fact Recall Across Time
David Herel, Vojtech Bartek, Tomas Mikolov
Who is the US President? The answer changes depending on when the question is asked. While large language models (LLMs) are evaluated on various reasoning tasks, they often miss a crucial dimension: time. In real-world scenarios, the correctness of answers is frequently tied to temporal context. In this paper, we introduce a novel dataset designed to rigorously test LLMs' ability to handle time-sensitive facts. Our benchmark offers a systematic way to measure how well LLMs align their knowledge with the correct time context, filling a key gap in current evaluation methods and offering a valuable tool for improving real-world applicability in future models.
Read more9/23/2024
0
Test of Time: A Benchmark for Evaluating LLMs on Temporal Reasoning
Bahare Fatemi, Mehran Kazemi, Anton Tsitsulin, Karishma Malkan, Jinyeong Yim, John Palowitch, Sungyong Seo, Jonathan Halcrow, Bryan Perozzi
Large language models (LLMs) have showcased remarkable reasoning capabilities, yet they remain susceptible to errors, particularly in temporal reasoning tasks involving complex temporal logic. Existing research has explored LLM performance on temporal reasoning using diverse datasets and benchmarks. However, these studies often rely on real-world data that LLMs may have encountered during pre-training or employ anonymization techniques that can inadvertently introduce factual inconsistencies. In this work, we address these limitations by introducing novel synthetic datasets specifically designed to assess LLM temporal reasoning abilities in various scenarios. The diversity of question types across these datasets enables systematic investigation into the impact of the problem structure, size, question type, fact order, and other factors on LLM performance. Our findings provide valuable insights into the strengths and weaknesses of current LLMs in temporal reasoning tasks. To foster further research in this area, we are open-sourcing the datasets and evaluation framework used in our experiments: https://huggingface.co/datasets/baharef/ToT.
Read more6/14/2024

0
Remember This Event That Year? Assessing Temporal Information and Reasoning in Large Language Models
Himanshu Beniwal, Dishant Patel, Kowsik Nandagopan D, Hritik Ladia, Ankit Yadav, Mayank Singh
Large Language Models (LLMs) are increasingly ubiquitous, yet their ability to retain and reason about temporal information remains limited, hindering their application in real-world scenarios where understanding the sequential nature of events is crucial. Our study experiments with 12 state-of-the-art models (ranging from 2B to 70B+ parameters) on a novel numerical-temporal dataset, textbf{TempUN}, spanning from 10,000 BCE to 2100 CE, to uncover significant temporal retention and comprehension limitations. We propose six metrics to assess three learning paradigms to enhance temporal knowledge acquisition. Our findings reveal that open-source models exhibit knowledge gaps more frequently, suggesting a trade-off between limited knowledge and incorrect responses. Additionally, various fine-tuning approaches significantly improved performance, reducing incorrect outputs and impacting the identification of 'information not available' in the generations. The associated dataset and code are available at (https://github.com/lingoiitgn/TempUN).
Read more7/8/2024
⛏️
0
Evaluating LLMs at Evaluating Temporal Generalization
Chenghao Zhu, Nuo Chen, Yufei Gao, Yunyi Zhang, Prayag Tiwari, Benyou Wang
The rapid advancement of Large Language Models (LLMs) highlights the urgent need for evolving evaluation methodologies that keep pace with improvements in language comprehension and information processing. However, traditional benchmarks, which are often static, fail to capture the continually changing information landscape, leading to a disparity between the perceived and actual effectiveness of LLMs in ever-changing real-world scenarios. Our study examines temporal generalization, which includes the ability to understand, predict, and generate text relevant to past, present, and future contexts, revealing significant temporal biases in LLMs. We propose an evaluation framework, for dynamically generating benchmarks from recent real-world predictions. Experiments demonstrate that LLMs struggle with temporal generalization, showing performance decline over time. These findings highlight the necessity for improved training and updating processes to enhance adaptability and reduce biases. Our code, dataset and benchmark are available at https://github.com/FreedomIntelligence/FreshBench.
Read more7/11/2024