Unsupervised Federated Optimization at the Edge: D2D-Enabled Learning without Labels
2404.09861
0
0

Abstract
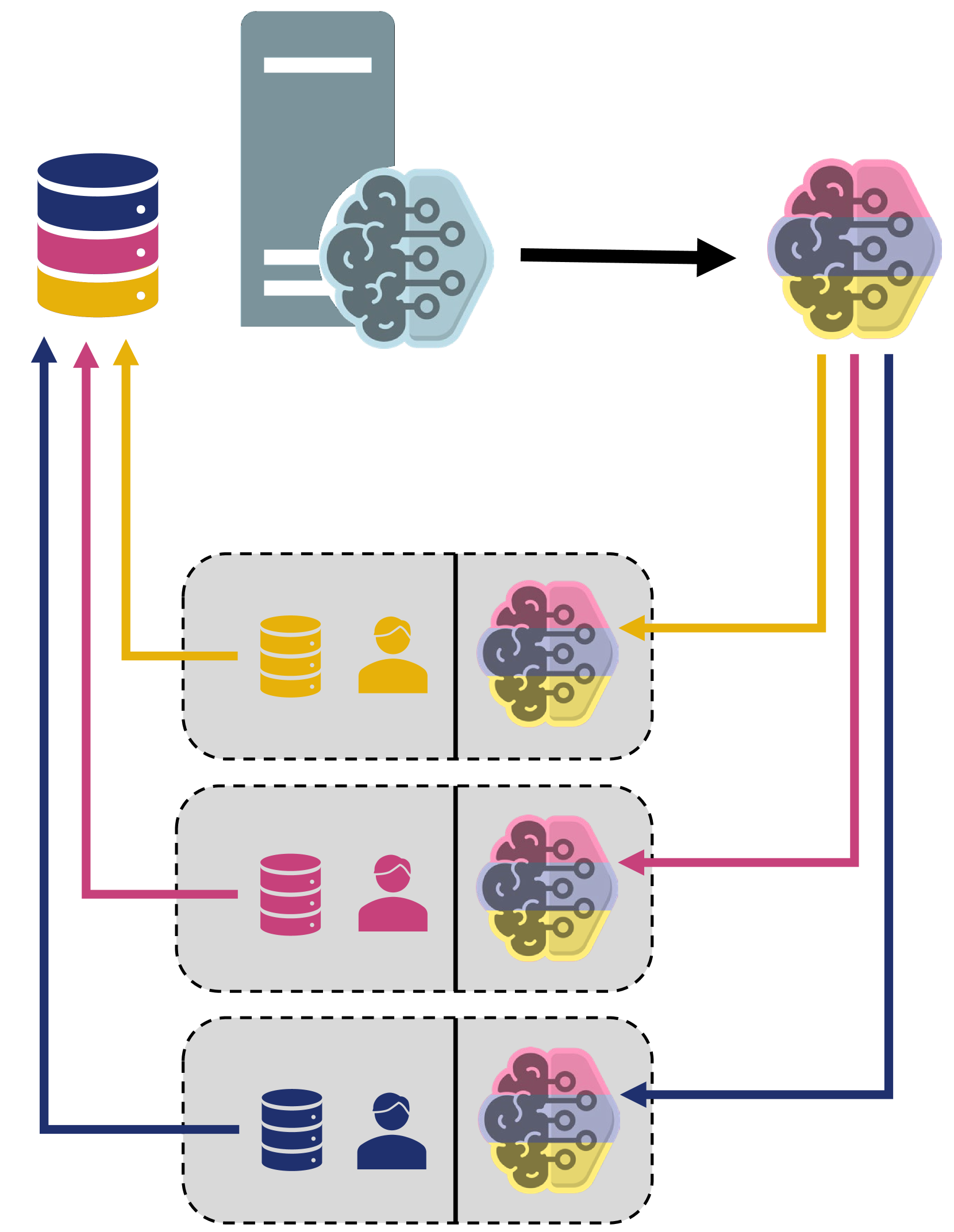
Federated learning (FL) is a popular solution for distributed machine learning (ML). While FL has traditionally been studied for supervised ML tasks, in many applications, it is impractical to assume availability of labeled data across devices. To this end, we develop Cooperative Federated unsupervised Contrastive Learning ({tt CF-CL)} to facilitate FL across edge devices with unlabeled datasets. {tt CF-CL} employs local device cooperation where either explicit (i.e., raw data) or implicit (i.e., embeddings) information is exchanged through device-to-device (D2D) communications to improve local diversity. Specifically, we introduce a textit{smart information push-pull} methodology for data/embedding exchange tailored to FL settings with either soft or strict data privacy restrictions. Information sharing is conducted through a probabilistic importance sampling technique at receivers leveraging a carefully crafted reserve dataset provided by transmitters. In the implicit case, embedding exchange is further integrated into the local ML training at the devices via a regularization term incorporated into the contrastive loss, augmented with a dynamic contrastive margin to adjust the volume of latent space explored. Numerical evaluations demonstrate that {tt CF-CL} leads to alignment of latent spaces learned across devices, results in faster and more efficient global model training, and is effective in extreme non-i.i.d. data distribution settings across devices.
Create account to get full access
Overview
- This paper explores unsupervised federated learning at the edge, where devices collaborate to train machine learning models without labeled data.
- The key innovation is the use of device-to-device (D2D) communication to enable this type of federated learning without labels.
- The researchers propose a novel algorithm and framework to facilitate this unsupervised federated optimization at the edge.
Plain English Explanation
In typical federated learning, devices collaborate to train a shared machine learning model, but they need labeled training data on each device. This paper explores a different approach called unsupervised federated learning, where the devices can collaborate without needing labeled data.
The key insight is to use device-to-device (D2D) communication to enable this type of federated learning without labels. Devices can share unlabeled data with each other and use unsupervised learning techniques to train the model cooperatively, without relying on centralized supervision.
The researchers propose a novel algorithm and framework to facilitate this unsupervised federated optimization at the edge. This allows devices to collaborate and learn from each other's unlabeled data, rather than requiring a central server or labeled training examples.
Technical Explanation
The paper introduces an unsupervised federated optimization framework that leverages D2D communication to enable federated learning without labeled data. The key idea is to have devices share unlabeled data with each other and use unsupervised learning techniques to jointly train a shared model.
The proposed framework includes several novel components:
- A D2D-based data sharing mechanism that allows devices to efficiently exchange unlabeled data samples.
- An unsupervised federated optimization algorithm that can learn from the shared unlabeled data, without relying on labeled examples.
- A communication-efficient model aggregation method that reduces the bandwidth required for model updates.
- An adaptive resource allocation strategy to handle the heterogeneous compute and communication capabilities of edge devices.
The researchers evaluate their framework through extensive simulations and demonstrate its effectiveness in training accurate models from unlabeled data, while requiring significantly less communication overhead compared to traditional federated learning approaches.
Critical Analysis
The paper presents a promising approach to federated learning that can operate without labeled data, which is a significant limitation of existing federated learning techniques. The use of D2D communication to enable this unsupervised federated optimization is a novel and compelling idea.
However, the paper does not address several important practical considerations:
- The impact of device heterogeneity and potential data drift on the unsupervised federated optimization algorithm.
- The security and privacy implications of sharing unlabeled data between devices, and how to mitigate potential privacy risks.
- The scalability of the proposed framework as the number of participating devices grows.
Additionally, the evaluation is limited to simulation-based experiments, and it would be valuable to see real-world deployments and their performance characteristics.
Conclusion
This paper introduces an innovative approach to federated learning that enables cooperative model training without the need for labeled data. By leveraging D2D communication, the proposed framework allows edge devices to share unlabeled data and jointly learn a shared model through unsupervised optimization.
The technical contributions, including the unsupervised federated optimization algorithm and the communication-efficient model aggregation, offer promising solutions to some of the key challenges in federated learning. While the paper highlights several important considerations, the overall approach represents a significant step forward in enabling more accessible and inclusive federated learning at the edge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
Enhancing Efficiency in Multidevice Federated Learning through Data Selection
Fan Mo, Mohammad Malekzadeh, Soumyajit Chatterjee, Fahim Kawsar, Akhil Mathur
0
0
Federated learning (FL) in multidevice environments creates new opportunities to learn from a vast and diverse amount of private data. Although personal devices capture valuable data, their memory, computing, connectivity, and battery resources are often limited. Since deep neural networks (DNNs) are the typical machine learning models employed in FL, there are demands for integrating ubiquitous constrained devices into the training process of DNNs. In this paper, we develop an FL framework to incorporate on-device data selection on such constrained devices, which allows partition-based training of a DNN through collaboration between constrained devices and resourceful devices of the same client. Evaluations on five benchmark DNNs and six benchmark datasets across different modalities show that, on average, our framework achieves ~19% higher accuracy and ~58% lower latency; compared to the baseline FL without our implemented strategies. We demonstrate the effectiveness of our FL framework when dealing with imbalanced data, client participation heterogeneity, and various mobility patterns. As a benchmark for the community, our code is available at https://github.com/dr-bell/data-centric-federated-learning
4/11/2024
Federated Learning: A Cutting-Edge Survey of the Latest Advancements and Applications
Azim Akhtarshenas, Mohammad Ali Vahedifar, Navid Ayoobi, Behrouz Maham, Tohid Alizadeh, Sina Ebrahimi, David L'opez-P'erez
0
0
Robust machine learning (ML) models can be developed by leveraging large volumes of data and distributing the computational tasks across numerous devices or servers. Federated learning (FL) is a technique in the realm of ML that facilitates this goal by utilizing cloud infrastructure to enable collaborative model training among a network of decentralized devices. Beyond distributing the computational load, FL targets the resolution of privacy issues and the reduction of communication costs simultaneously. To protect user privacy, FL requires users to send model updates rather than transmitting large quantities of raw and potentially confidential data. Specifically, individuals train ML models locally using their own data and then upload the results in the form of weights and gradients to the cloud for aggregation into the global model. This strategy is also advantageous in environments with limited bandwidth or high communication costs, as it prevents the transmission of large data volumes. With the increasing volume of data and rising privacy concerns, alongside the emergence of large-scale ML models like Large Language Models (LLMs), FL presents itself as a timely and relevant solution. It is therefore essential to review current FL algorithms to guide future research that meets the rapidly evolving ML demands. This survey provides a comprehensive analysis and comparison of the most recent FL algorithms, evaluating them on various fronts including mathematical frameworks, privacy protection, resource allocation, and applications. Beyond summarizing existing FL methods, this survey identifies potential gaps, open areas, and future challenges based on the performance reports and algorithms used in recent studies. This survey enables researchers to readily identify existing limitations in the FL field for further exploration.
5/28/2024
👁️
Privacy-Preserving Edge Federated Learning for Intelligent Mobile-Health Systems
Amin Aminifar, Matin Shokri, Amir Aminifar
0
0
Machine Learning (ML) algorithms are generally designed for scenarios in which all data is stored in one data center, where the training is performed. However, in many applications, e.g., in the healthcare domain, the training data is distributed among several entities, e.g., different hospitals or patients' mobile devices/sensors. At the same time, transferring the data to a central location for learning is certainly not an option, due to privacy concerns and legal issues, and in certain cases, because of the communication and computation overheads. Federated Learning (FL) is the state-of-the-art collaborative ML approach for training an ML model across multiple parties holding local data samples, without sharing them. However, enabling learning from distributed data over such edge Internet of Things (IoT) systems (e.g., mobile-health and wearable technologies, involving sensitive personal/medical data) in a privacy-preserving fashion presents a major challenge mainly due to their stringent resource constraints, i.e., limited computing capacity, communication bandwidth, memory storage, and battery lifetime. In this paper, we propose a privacy-preserving edge FL framework for resource-constrained mobile-health and wearable technologies over the IoT infrastructure. We evaluate our proposed framework extensively and provide the implementation of our technique on Amazon's AWS cloud platform based on the seizure detection application in epilepsy monitoring using wearable technologies.
5/10/2024
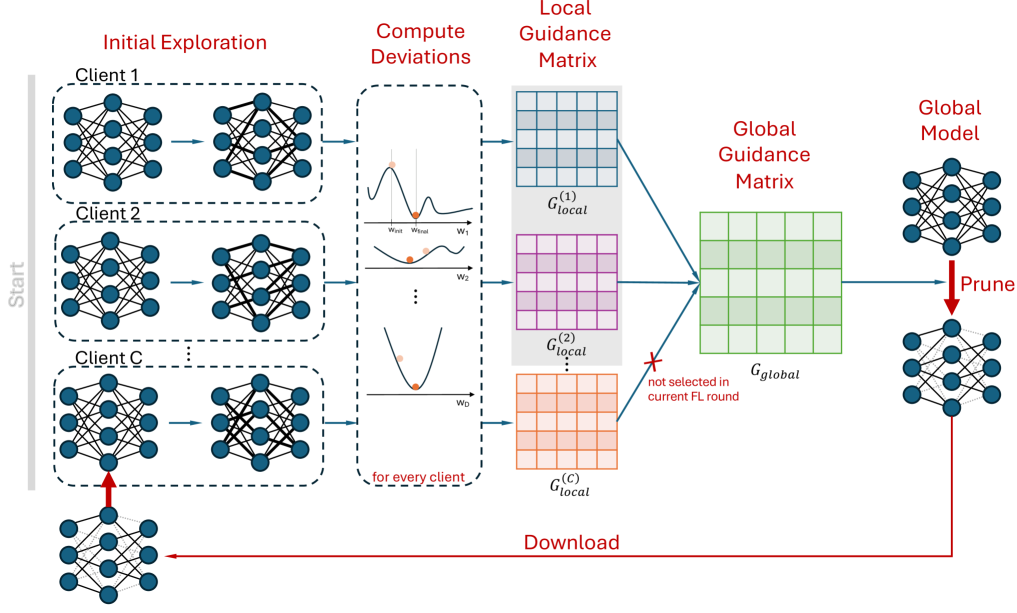
Automated Federated Learning via Informed Pruning
Christian Intern`o, Elena Raponi, Niki van Stein, Thomas Back, Markus Olhofer, Yaochu Jin, Barbara Hammer
0
0
Federated learning (FL) represents a pivotal shift in machine learning (ML) as it enables collaborative training of local ML models coordinated by a central aggregator, all without the need to exchange local data. However, its application on edge devices is hindered by limited computational capabilities and data communication challenges, compounded by the inherent complexity of Deep Learning (DL) models. Model pruning is identified as a key technique for compressing DL models on devices with limited resources. Nonetheless, conventional pruning techniques typically rely on manually crafted heuristics and demand human expertise to achieve a balance between model size, speed, and accuracy, often resulting in sub-optimal solutions. In this study, we introduce an automated federated learning approach utilizing informed pruning, called AutoFLIP, which dynamically prunes and compresses DL models within both the local clients and the global server. It leverages a federated loss exploration phase to investigate model gradient behavior across diverse datasets and losses, providing insights into parameter significance. Our experiments showcase notable enhancements in scenarios with strong non-IID data, underscoring AutoFLIP's capacity to tackle computational constraints and achieve superior global convergence.
5/17/2024