Automated Federated Learning via Informed Pruning
2405.10271
0
0
Abstract
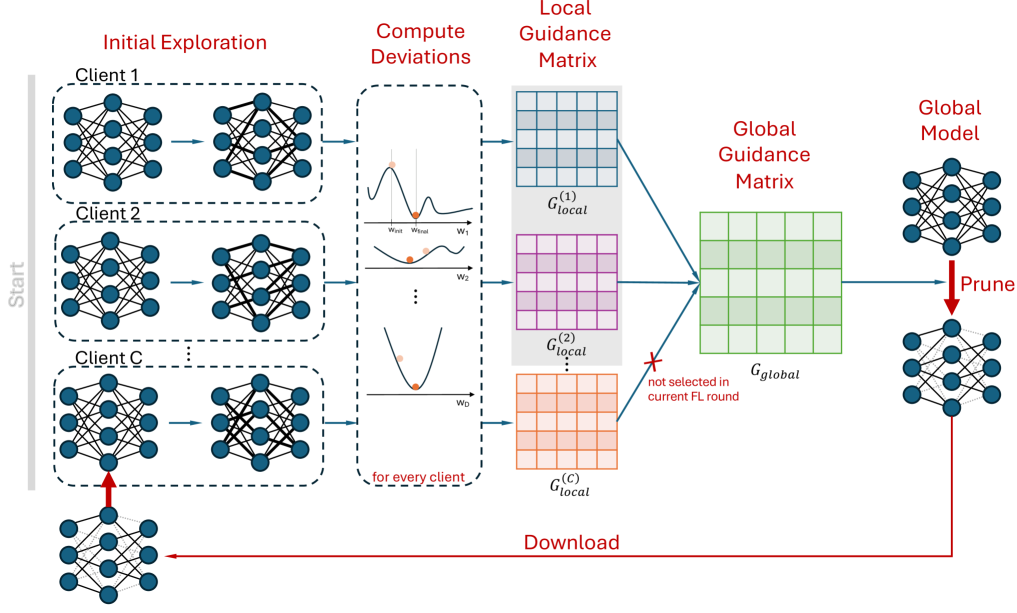
Federated learning (FL) represents a pivotal shift in machine learning (ML) as it enables collaborative training of local ML models coordinated by a central aggregator, all without the need to exchange local data. However, its application on edge devices is hindered by limited computational capabilities and data communication challenges, compounded by the inherent complexity of Deep Learning (DL) models. Model pruning is identified as a key technique for compressing DL models on devices with limited resources. Nonetheless, conventional pruning techniques typically rely on manually crafted heuristics and demand human expertise to achieve a balance between model size, speed, and accuracy, often resulting in sub-optimal solutions. In this study, we introduce an automated federated learning approach utilizing informed pruning, called AutoFLIP, which dynamically prunes and compresses DL models within both the local clients and the global server. It leverages a federated loss exploration phase to investigate model gradient behavior across diverse datasets and losses, providing insights into parameter significance. Our experiments showcase notable enhancements in scenarios with strong non-IID data, underscoring AutoFLIP's capacity to tackle computational constraints and achieve superior global convergence.
Create account to get full access
Overview
- This paper proposes a novel approach called "Automated Federated Learning via Informed Pruning" (AFLIP) to improve the efficiency of federated learning, a distributed machine learning technique.
- Federated learning allows multiple devices to collaboratively train a shared model without sharing their local data, which is important for privacy and data ownership.
- However, federated learning can be computationally expensive, so AFLIP aims to reduce the communication and computation required by selectively pruning the model during training.
Plain English Explanation
Federated learning is a way for different devices, like phones or computers, to work together to train a machine learning model without sharing their private data. This is useful because it protects people's privacy. However, federated learning can be slow and use a lot of computing power.
The researchers in this paper developed a new method called AFLIP that tries to make federated learning faster and more efficient. AFLIP does this by automatically figuring out which parts of the machine learning model are not as important, and then removing or "pruning" those parts. This reduces the amount of data that needs to be sent between the devices, and the amount of computation required, without significantly hurting the model's performance.
AFLIP uses information about how the model is being trained to decide which parts to prune. This "informed pruning" is more effective than just randomly removing parts of the model. By making federated learning more efficient, AFLIP could help bring the benefits of machine learning to more people and devices, while still protecting their privacy.
Technical Explanation
The key innovation in this paper is the AFLIP (Automated Federated Learning via Informed Pruning) approach, which combines federated learning with model pruning to improve the efficiency of the federated learning process.
In federated learning, multiple devices collaboratively train a shared machine learning model without sharing their local data. This is important for maintaining data privacy and ownership. However, federated learning can be computationally expensive due to the need to communicate model updates between devices.
AFLIP addresses this by selectively pruning the machine learning model during the federated training process. The pruning is "informed" in the sense that it leverages information about the model's training dynamics to identify which parameters are less important and can be safely removed without significantly degrading model performance.
The paper presents a thorough experimental evaluation of AFLIP across multiple federated learning benchmarks and datasets. The results show that AFLIP can achieve significant reductions in communication and computation costs compared to standard federated learning, with only minor losses in model accuracy.
The technical details of the AFLIP approach, including the pruning criteria and optimization procedures, are described in depth in the paper. The authors also provide insights into the tradeoffs between pruning aggressiveness, communication efficiency, and model quality.
Critical Analysis
The AFLIP approach proposed in this paper represents a promising step forward in improving the efficiency of federated learning. By selectively pruning the shared model, AFLIP can significantly reduce the communication and computation requirements, which are key bottlenecks in federated learning.
One potential limitation of the work is that the pruning decisions are made globally across all participating devices, rather than tailored to the unique characteristics of each local device. Techniques like adaptive federated learning may be able to further improve efficiency by personalizing the pruning to each device's resources and data distribution.
Additionally, the paper does not explore the implications of AFLIP for model personalization or the potential privacy risks associated with the pruning process. Techniques for personalized federated learning and privacy-preserving federated learning may be valuable extensions to consider in future work.
Overall, the AFLIP approach represents an important contribution to the field of federated learning, with the potential to enable more widespread adoption of privacy-preserving machine learning. However, further research is needed to address the remaining challenges and ensure the safe and ethical deployment of such techniques, particularly in sensitive domains like edge computing and mobile applications.
Conclusion
The "Automated Federated Learning via Informed Pruning" (AFLIP) technique proposed in this paper offers a novel way to improve the efficiency of federated learning, a distributed machine learning approach that protects data privacy. By selectively pruning the shared model during the training process, AFLIP can significantly reduce the communication and computation requirements without sacrificing model performance.
This work represents an important step forward in making federated learning more practical and accessible for a wider range of applications and devices. By improving the efficiency of federated learning, AFLIP could help bring the benefits of machine learning to more people and organizations, while still preserving their data privacy and ownership.
However, further research is needed to address the remaining challenges, such as personalizing the pruning to individual devices and ensuring the privacy and security of the federated learning process. As the field of federated learning continues to evolve, techniques like agglomerative federated learning may play an important role in unlocking the full potential of privacy-preserving machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Federated Learning: A Cutting-Edge Survey of the Latest Advancements and Applications
Azim Akhtarshenas, Mohammad Ali Vahedifar, Navid Ayoobi, Behrouz Maham, Tohid Alizadeh, Sina Ebrahimi, David L'opez-P'erez
0
0
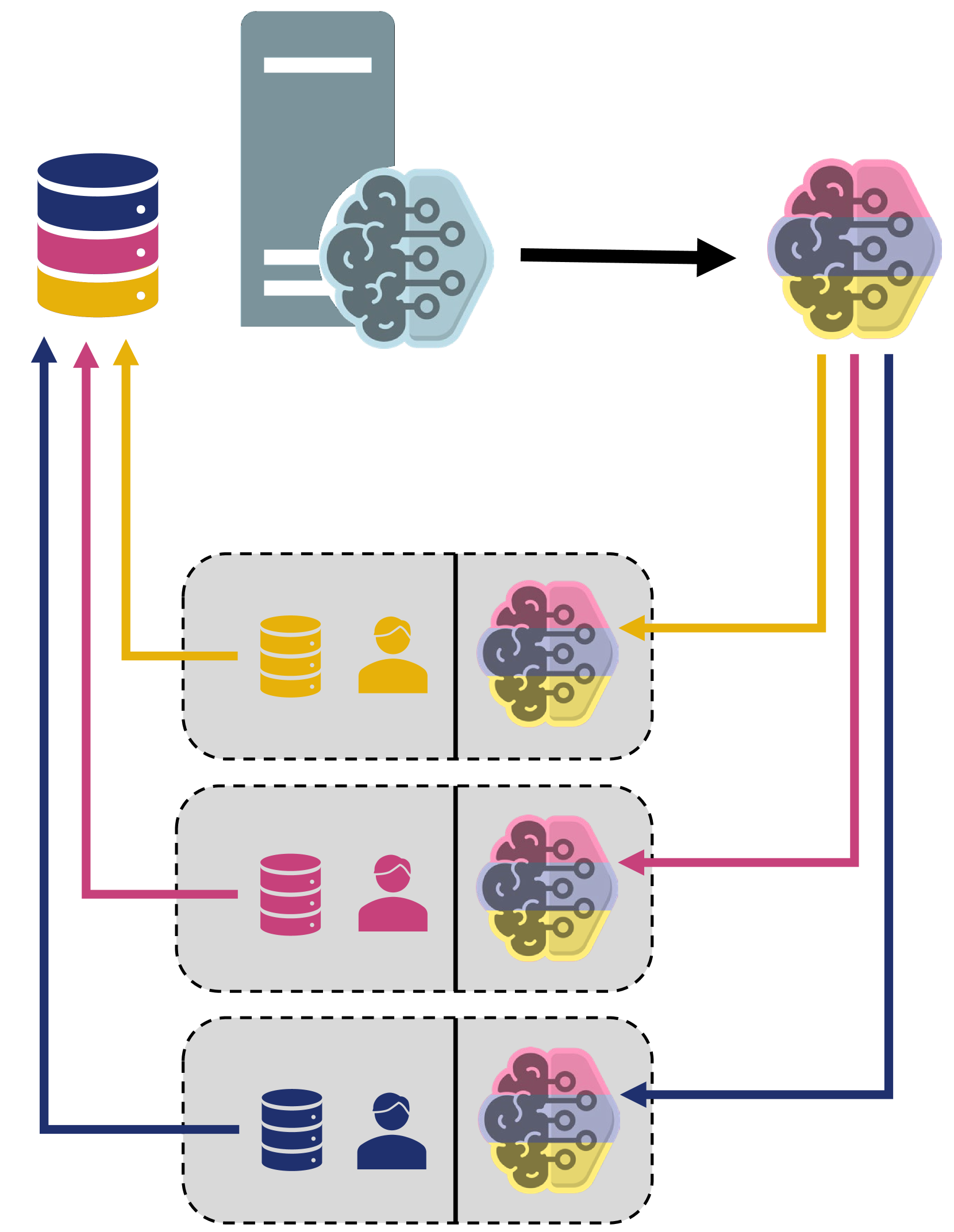
Robust machine learning (ML) models can be developed by leveraging large volumes of data and distributing the computational tasks across numerous devices or servers. Federated learning (FL) is a technique in the realm of ML that facilitates this goal by utilizing cloud infrastructure to enable collaborative model training among a network of decentralized devices. Beyond distributing the computational load, FL targets the resolution of privacy issues and the reduction of communication costs simultaneously. To protect user privacy, FL requires users to send model updates rather than transmitting large quantities of raw and potentially confidential data. Specifically, individuals train ML models locally using their own data and then upload the results in the form of weights and gradients to the cloud for aggregation into the global model. This strategy is also advantageous in environments with limited bandwidth or high communication costs, as it prevents the transmission of large data volumes. With the increasing volume of data and rising privacy concerns, alongside the emergence of large-scale ML models like Large Language Models (LLMs), FL presents itself as a timely and relevant solution. It is therefore essential to review current FL algorithms to guide future research that meets the rapidly evolving ML demands. This survey provides a comprehensive analysis and comparison of the most recent FL algorithms, evaluating them on various fronts including mathematical frameworks, privacy protection, resource allocation, and applications. Beyond summarizing existing FL methods, this survey identifies potential gaps, open areas, and future challenges based on the performance reports and algorithms used in recent studies. This survey enables researchers to readily identify existing limitations in the FL field for further exploration.
5/28/2024
Federated Learning driven Large Language Models for Swarm Intelligence: A Survey
Youyang Qu
0
0
Federated learning (FL) offers a compelling framework for training large language models (LLMs) while addressing data privacy and decentralization challenges. This paper surveys recent advancements in the federated learning of large language models, with a particular focus on machine unlearning, a crucial aspect for complying with privacy regulations like the Right to be Forgotten. Machine unlearning in the context of federated LLMs involves systematically and securely removing individual data contributions from the learned model without retraining from scratch. We explore various strategies that enable effective unlearning, such as perturbation techniques, model decomposition, and incremental learning, highlighting their implications for maintaining model performance and data privacy. Furthermore, we examine case studies and experimental results from recent literature to assess the effectiveness and efficiency of these approaches in real-world scenarios. Our survey reveals a growing interest in developing more robust and scalable federated unlearning methods, suggesting a vital area for future research in the intersection of AI ethics and distributed machine learning technologies.
6/17/2024
📊
Multi-level Personalized Federated Learning on Heterogeneous and Long-Tailed Data
Rongyu Zhang, Yun Chen, Chenrui Wu, Fangxin Wang, Bo Li
0
0
Federated learning (FL) offers a privacy-centric distributed learning framework, enabling model training on individual clients and central aggregation without necessitating data exchange. Nonetheless, FL implementations often suffer from non-i.i.d. and long-tailed class distributions across mobile applications, e.g., autonomous vehicles, which leads models to overfitting as local training may converge to sub-optimal. In our study, we explore the impact of data heterogeneity on model bias and introduce an innovative personalized FL framework, Multi-level Personalized Federated Learning (MuPFL), which leverages the hierarchical architecture of FL to fully harness computational resources at various levels. This framework integrates three pivotal modules: Biased Activation Value Dropout (BAVD) to mitigate overfitting and accelerate training; Adaptive Cluster-based Model Update (ACMU) to refine local models ensuring coherent global aggregation; and Prior Knowledge-assisted Classifier Fine-tuning (PKCF) to bolster classification and personalize models in accord with skewed local data with shared knowledge. Extensive experiments on diverse real-world datasets for image classification and semantic segmentation validate that MuPFL consistently outperforms state-of-the-art baselines, even under extreme non-i.i.d. and long-tail conditions, which enhances accuracy by as much as 7.39% and accelerates training by up to 80% at most, marking significant advancements in both efficiency and effectiveness.
5/13/2024
Efficient Model Compression for Hierarchical Federated Learning
Xi Zhu, Songcan Yu, Junbo Wang, Qinglin Yang
0
0
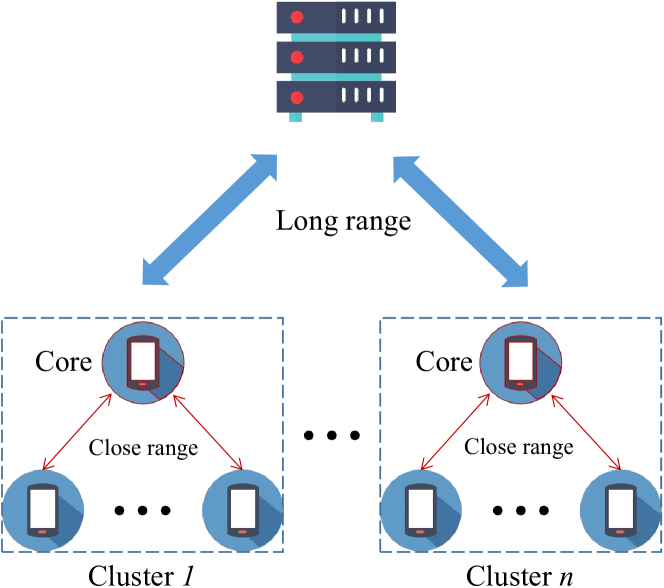
Federated learning (FL), as an emerging collaborative learning paradigm, has garnered significant attention due to its capacity to preserve privacy within distributed learning systems. In these systems, clients collaboratively train a unified neural network model using their local datasets and share model parameters rather than raw data, enhancing privacy. Predominantly, FL systems are designed for mobile and edge computing environments where training typically occurs over wireless networks. Consequently, as model sizes increase, the conventional FL frameworks increasingly consume substantial communication resources. To address this challenge and improve communication efficiency, this paper introduces a novel hierarchical FL framework that integrates the benefits of clustered FL and model compression. We present an adaptive clustering algorithm that identifies a core client and dynamically organizes clients into clusters. Furthermore, to enhance transmission efficiency, each core client implements a local aggregation with compression (LC aggregation) algorithm after collecting compressed models from other clients within the same cluster. Simulation results affirm that our proposed algorithms not only maintain comparable predictive accuracy but also significantly reduce energy consumption relative to existing FL mechanisms.
5/29/2024