Unsupervised Video Domain Adaptation with Masked Pre-Training and Collaborative Self-Training

0
Sign in to get full access
Overview
- This paper proposes a novel unsupervised video domain adaptation method that combines masked pre-training and collaborative self-training.
- The method aims to address the challenge of adapting video models from a source domain to a target domain without labeled data in the target domain.
- The key contributions include a masked pre-training approach to learn robust video representations, and a collaborative self-training strategy to effectively leverage unlabeled target domain data.
Plain English Explanation
When training machine learning models for video analysis, it's common to have a large dataset of labeled video examples in one domain (the "source" domain), but limited or no labeled data in another domain (the "target" domain) you want to apply the model to. This can lead to poor performance when deploying the model in the target domain.
The researchers in this paper introduce a new approach to address this "domain adaptation" problem for videos. Their method has two main components:
-
Masked Pre-Training: They start by pre-training the model on the source domain data, but during this pre-training they randomly "mask" or hide parts of the video frames. This forces the model to learn more robust and generalizable video representations, beyond just memorizing the source domain data.
-
Collaborative Self-Training: After the pre-training, they use the pre-trained model to make predictions on unlabeled target domain videos. They then have the model "teach itself" by updating its own weights based on these predictions, in an iterative process. Crucially, they also have the model collaborate with other instances of itself, sharing information to improve the self-training.
By combining these two techniques - masked pre-training and collaborative self-training - the researchers are able to effectively adapt video models from the source domain to the target domain, without requiring any labeled data in the target domain. This is a valuable capability, as obtaining labeled video data can be time-consuming and expensive.
Technical Explanation
The paper proposes an Unsupervised Video Domain Adaptation (UVDA) method that leverages masked pre-training and collaborative self-training to adapt video models from a labeled source domain to an unlabeled target domain.
In the masked pre-training stage, the model is pre-trained on the source domain videos, but during this pre-training, random patches of the video frames are masked out. This forces the model to learn more robust and generalizable video representations, beyond just memorizing the source data.
The collaborative self-training stage then follows. Here, the pre-trained model is applied to unlabeled target domain videos, and it makes predictions on those videos. The model then updates its own weights based on those predictions, in an iterative self-training process. Crucially, multiple instances of the model collaborate with each other, sharing information to improve the self-training.
The authors evaluate their UVDA method on several video domain adaptation benchmarks, and show that it outperforms existing unsupervised domain adaptation techniques. They attribute the success to the complementary benefits of masked pre-training (for learning transferable representations) and collaborative self-training (for effectively leveraging unlabeled target data).
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed UVDA method, with comparisons to multiple baseline approaches on several standard benchmarks. The results convincingly demonstrate the effectiveness of the combined masked pre-training and collaborative self-training strategy.
That said, the paper does not extensively discuss potential limitations or caveats of the approach. For example, it's unclear how the method would scale to very large or diverse target domains, or how sensitive the performance is to the hyperparameter settings.
Additionally, the collaborative self-training component relies on multiple instances of the same model iteratively teaching each other. In a real-world deployment scenario, this may not be feasible, and it would be valuable to explore alternative ways of leveraging the unlabeled target data.
Overall, the research represents a meaningful advance in unsupervised video domain adaptation, but there are opportunities for further investigation into the robustness, scalability, and practicality of the proposed techniques.
Conclusion
This paper introduces a novel unsupervised video domain adaptation method that combines masked pre-training and collaborative self-training. The key ideas are to (1) learn robust video representations through masked pre-training, and (2) effectively leverage unlabeled target domain data via a collaborative self-training strategy.
The empirical results demonstrate the effectiveness of this approach, outperforming existing unsupervised domain adaptation techniques on several video benchmarks. While the paper does not extensively explore limitations, the proposed UVDA method represents an important step forward in adapting video models to new domains without requiring labeled target data.
The techniques presented in this work could have significant real-world impact, as the ability to deploy video models across different domains without costly data labeling is a valuable capability. Further research to enhance the robustness and practicality of these methods could unlock even broader applications in video understanding and analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Unsupervised Video Domain Adaptation with Masked Pre-Training and Collaborative Self-Training
Arun Reddy, William Paul, Corban Rivera, Ketul Shah, Celso M. de Melo, Rama Chellappa
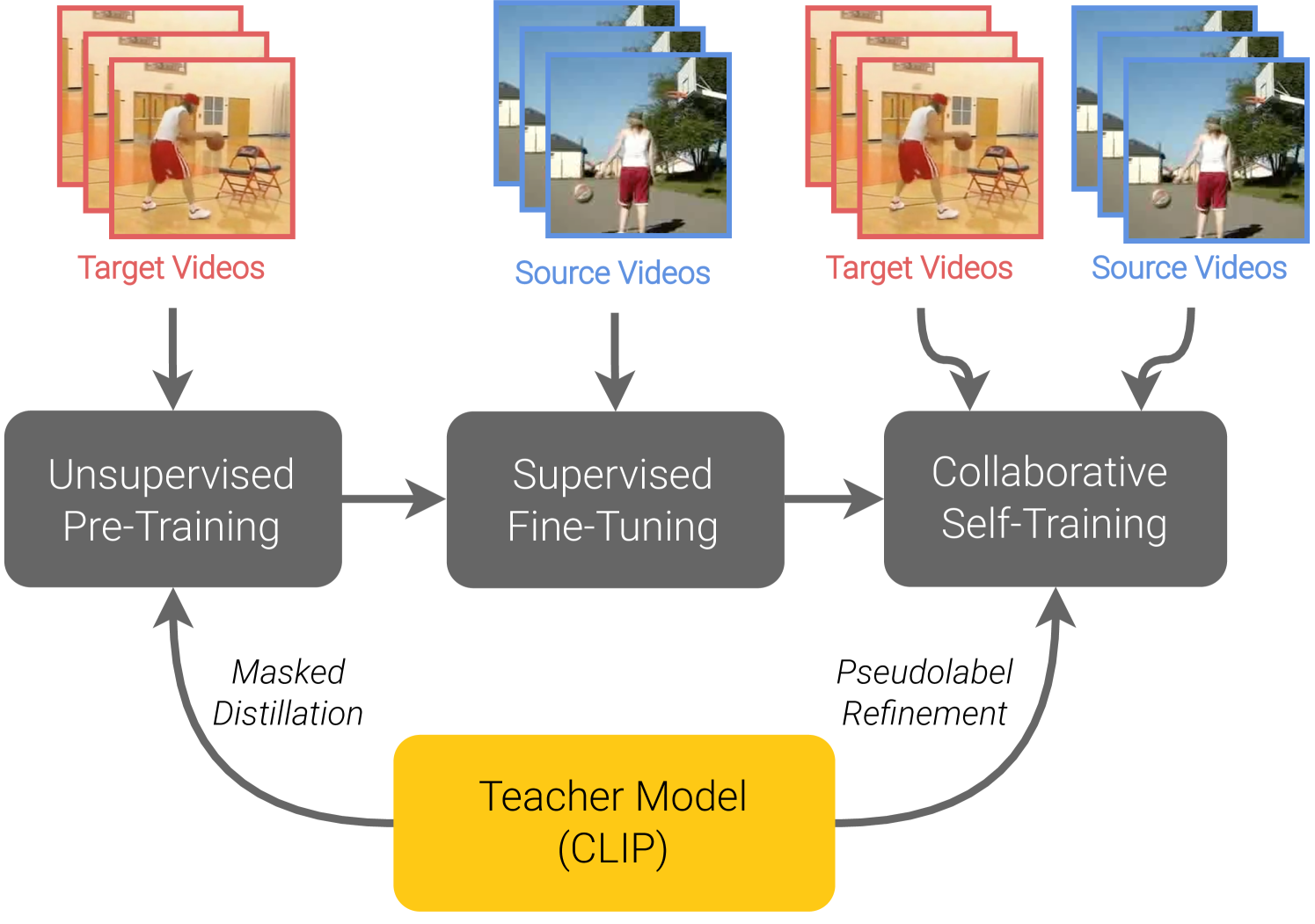
In this work, we tackle the problem of unsupervised domain adaptation (UDA) for video action recognition. Our approach, which we call UNITE, uses an image teacher model to adapt a video student model to the target domain. UNITE first employs self-supervised pre-training to promote discriminative feature learning on target domain videos using a teacher-guided masked distillation objective. We then perform self-training on masked target data, using the video student model and image teacher model together to generate improved pseudolabels for unlabeled target videos. Our self-training process successfully leverages the strengths of both models to achieve strong transfer performance across domains. We evaluate our approach on multiple video domain adaptation benchmarks and observe significant improvements upon previously reported results.
Read more4/23/2024
🤷
0
Video Unsupervised Domain Adaptation with Deep Learning: A Comprehensive Survey
Yuecong Xu, Haozhi Cao, Zhenghua Chen, Xiaoli Li, Lihua Xie, Jianfei Yang
Video analysis tasks such as action recognition have received increasing research interest with growing applications in fields such as smart healthcare, thanks to the introduction of large-scale datasets and deep learning-based representations. However, video models trained on existing datasets suffer from significant performance degradation when deployed directly to real-world applications due to domain shifts between the training public video datasets (source video domains) and real-world videos (target video domains). Further, with the high cost of video annotation, it is more practical to use unlabeled videos for training. To tackle performance degradation and address concerns in high video annotation cost uniformly, the video unsupervised domain adaptation (VUDA) is introduced to adapt video models from the labeled source domain to the unlabeled target domain by alleviating video domain shift, improving the generalizability and portability of video models. This paper surveys recent progress in VUDA with deep learning. We begin with the motivation of VUDA, followed by its definition, and recent progress of methods for both closed-set VUDA and VUDA under different scenarios, and current benchmark datasets for VUDA research. Eventually, future directions are provided to promote further VUDA research. The repository of this survey is provided at https://github.com/xuyu0010/awesome-video-domain-adaptation.
Read more7/30/2024

0
EUDA: An Efficient Unsupervised Domain Adaptation via Self-Supervised Vision Transformer
Ali Abedi, Q. M. Jonathan Wu, Ning Zhang, Farhad Pourpanah
Unsupervised domain adaptation (UDA) aims to mitigate the domain shift issue, where the distribution of training (source) data differs from that of testing (target) data. Many models have been developed to tackle this problem, and recently vision transformers (ViTs) have shown promising results. However, the complexity and large number of trainable parameters of ViTs restrict their deployment in practical applications. This underscores the need for an efficient model that not only reduces trainable parameters but also allows for adjustable complexity based on specific needs while delivering comparable performance. To achieve this, in this paper we introduce an Efficient Unsupervised Domain Adaptation (EUDA) framework. EUDA employs the DINOv2, which is a self-supervised ViT, as a feature extractor followed by a simplified bottleneck of fully connected layers to refine features for enhanced domain adaptation. Additionally, EUDA employs the synergistic domain alignment loss (SDAL), which integrates cross-entropy (CE) and maximum mean discrepancy (MMD) losses, to balance adaptation by minimizing classification errors in the source domain while aligning the source and target domain distributions. The experimental results indicate the effectiveness of EUDA in producing comparable results as compared with other state-of-the-art methods in domain adaptation with significantly fewer trainable parameters, between 42% to 99.7% fewer. This showcases the ability to train the model in a resource-limited environment. The code of the model is available at: https://github.com/A-Abedi/EUDA.
Read more8/1/2024
0
Style Adaptation for Domain-adaptive Semantic Segmentation
Ting Li, Jianshu Chao, Deyu An
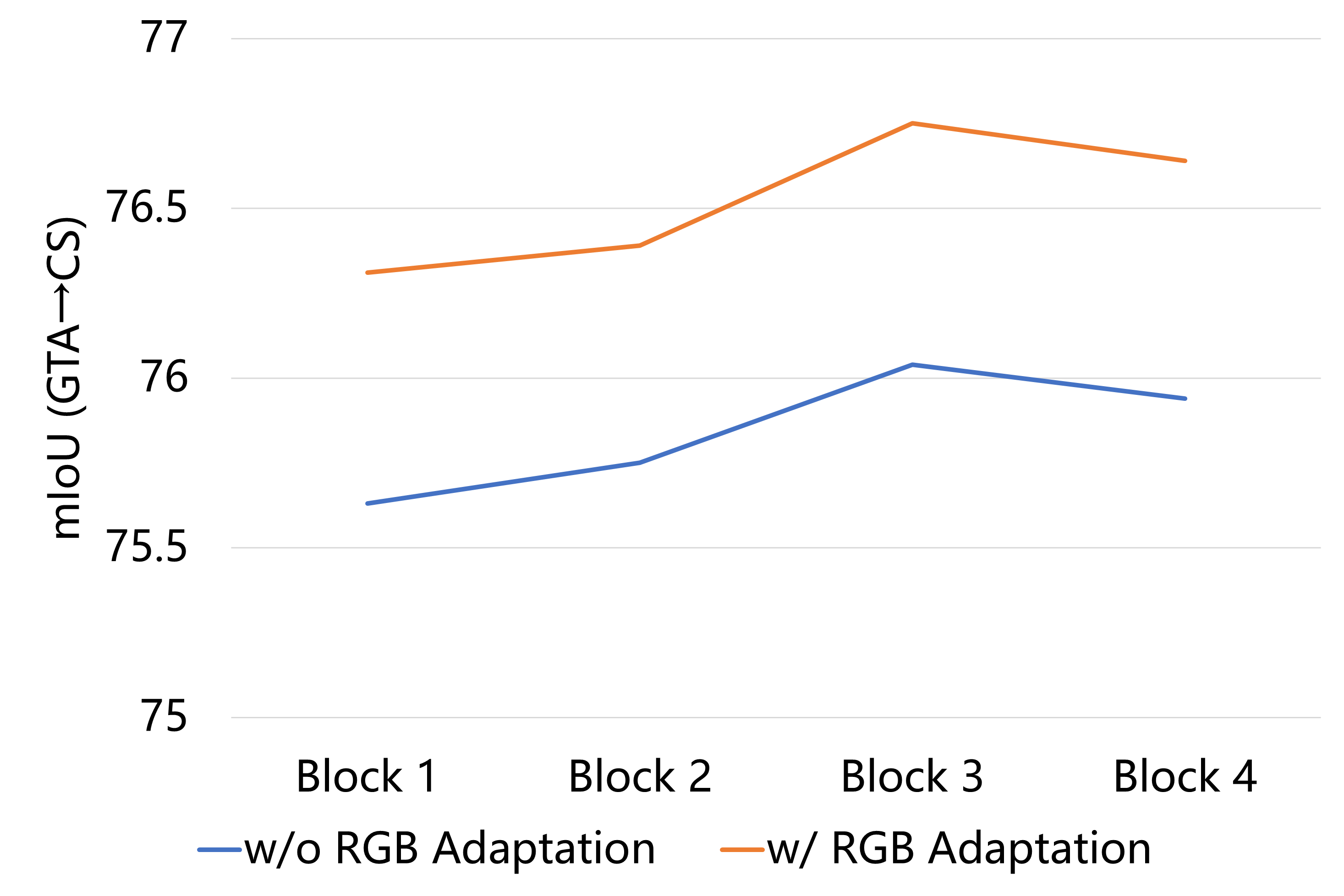
Unsupervised Domain Adaptation (UDA) refers to the method that utilizes annotated source domain data and unlabeled target domain data to train a model capable of generalizing to the target domain data. Domain discrepancy leads to a significant decrease in the performance of general network models trained on the source domain data when applied to the target domain. We introduce a straightforward approach to mitigate the domain discrepancy, which necessitates no additional parameter calculations and seamlessly integrates with self-training-based UDA methods. Through the transfer of the target domain style to the source domain in the latent feature space, the model is trained to prioritize the target domain style during the decision-making process. We tackle the problem at both the image-level and shallow feature map level by transferring the style information from the target domain to the source domain data. As a result, we obtain a model that exhibits superior performance on the target domain. Our method yields remarkable enhancements in the state-of-the-art performance for synthetic-to-real UDA tasks. For example, our proposed method attains a noteworthy UDA performance of 76.93 mIoU on the GTA->Cityscapes dataset, representing a notable improvement of +1.03 percentage points over the previous state-of-the-art results.
Read more4/26/2024