Unveiling and Mitigating Generalized Biases of DNNs through the Intrinsic Dimensions of Perceptual Manifolds
2404.13859
0
0

Abstract
Building fair deep neural networks (DNNs) is a crucial step towards achieving trustworthy artificial intelligence. Delving into deeper factors that affect the fairness of DNNs is paramount and serves as the foundation for mitigating model biases. However, current methods are limited in accurately predicting DNN biases, relying solely on the number of training samples and lacking more precise measurement tools. Here, we establish a geometric perspective for analyzing the fairness of DNNs, comprehensively exploring how DNNs internally shape the intrinsic geometric characteristics of datasets-the intrinsic dimensions (IDs) of perceptual manifolds, and the impact of IDs on the fairness of DNNs. Based on multiple findings, we propose Intrinsic Dimension Regularization (IDR), which enhances the fairness and performance of models by promoting the learning of concise and ID-balanced class perceptual manifolds. In various image recognition benchmark tests, IDR significantly mitigates model bias while improving its performance.
Create account to get full access
Overview
- This paper explores how the intrinsic dimensions of perceptual manifolds can be used to unveil and mitigate generalized biases in deep neural networks (DNNs).
- The authors investigate the geometry of the perceptual manifold learned by DNNs and its relation to generalization and biases.
- They propose methods to identify and address biases by leveraging the underlying structure of the perceptual manifold.
Plain English Explanation
Deep neural networks (DNNs) have become powerful tools for various AI tasks, such as image recognition and natural language processing. However, these models can exhibit biases, which can lead to unfair or inaccurate outputs, particularly when applied to diverse datasets or real-world scenarios.
This paper explores a novel approach to unveiling and mitigating these generalized biases in DNNs by examining the intrinsic dimensions of the perceptual manifold - the underlying geometric structure that the model learns to represent the input data. By understanding the properties of this manifold, the researchers aim to identify and address the biases inherent in the model's learning process.
The key insight is that the geometry of the perceptual manifold, specifically its intrinsic dimensionality, can provide valuable clues about the model's biases and generalization capabilities. For example, if the manifold has a lower intrinsic dimensionality than the input data, it may indicate that the model has learned to focus on a limited set of features, potentially leading to biased outputs. By analyzing the manifold's structure, the researchers can develop techniques to uncover and mitigate these biases.
The paper presents several methods for leveraging the intrinsic dimensions of the perceptual manifold to improve DNN fairness and generalization. These include link to "Predicting and Enhancing Fairness of DNNs via Curvature of Perceptual Manifolds", link to "Unbiased Image Synthesis via Manifold Guidance Diffusion", and link to "Generalization of Diffusion Models Arises from Geometry and Adaptive Behavior". By understanding the underlying geometry of the perceptual manifold, the researchers aim to develop more robust and equitable AI systems.
Technical Explanation
The core idea of this paper is to leverage the intrinsic dimensions of the perceptual manifold learned by deep neural networks (DNNs) to unveil and mitigate generalized biases in these models. The authors hypothesize that the geometry of the perceptual manifold, as captured by its intrinsic dimensionality, can provide valuable insights into the model's biases and generalization capabilities.
The researchers start by formally defining the concept of a perceptual manifold - the underlying geometric structure that DNNs learn to represent the input data. They then propose several methods to analyze the intrinsic dimensions of this manifold, including link to "Can the Biases of ImageNet Models Explain Generalization?" and link to "FairVision: Equitable Deep Learning for Eye Disease Screening".
Through extensive experiments, the authors demonstrate that the intrinsic dimensionality of the perceptual manifold is closely linked to the model's biases and generalization performance. For example, they show that if the manifold has a lower intrinsic dimensionality than the input data, the model may have learned to focus on a limited set of features, leading to biased outputs.
Building on these insights, the paper presents several techniques to leverage the perceptual manifold's geometry to improve DNN fairness and generalization. These include methods for link to "Predicting and Enhancing Fairness of DNNs via Curvature of Perceptual Manifolds", link to "Unbiased Image Synthesis via Manifold Guidance Diffusion", and link to "Generalization of Diffusion Models Arises from Geometry and Adaptive Behavior".
The authors validate their approaches on a range of benchmark tasks and datasets, demonstrating the potential of their techniques to improve the fairness and robustness of state-of-the-art DNN models.
Critical Analysis
The paper presents a thoughtful and well-designed approach to addressing the critical issue of bias in deep neural networks. By focusing on the underlying geometry of the perceptual manifold, the authors have introduced a novel and promising direction for bias mitigation.
One key strength of the research is the rigorous experimental evaluation, which provides strong evidence for the connection between the intrinsic dimensions of the perceptual manifold and DNN biases. The authors have also developed a suite of practical techniques that leverage these insights, which could have far-reaching implications for the development of more equitable and robust AI systems.
However, the paper also acknowledges several limitations and areas for further research. For instance, the proposed methods may not be able to address all types of biases, and their effectiveness may depend on the specific task and dataset. Additionally, the computational complexity of some of the techniques could pose challenges for deployment in real-world scenarios.
Moreover, the paper does not explore the potential ethical implications of this research, such as the risk of these methods being misused to hide or perpetuate biases. It would be valuable for the authors to address these concerns and provide guidance on the responsible use of their techniques.
Overall, this paper represents a significant contribution to the growing body of work on bias in deep learning. By link to "Unveiling and Mitigating Generalized Biases of DNNs through the Intrinsic Dimensions of Perceptual Manifolds", the authors have opened up a promising new direction for researchers and practitioners to explore in their pursuit of more equitable and trustworthy AI.
Conclusion
This paper introduces a novel approach to unveiling and mitigating generalized biases in deep neural networks by analyzing the intrinsic dimensions of the perceptual manifold. The key insight is that the geometry of this underlying representation can provide valuable clues about the model's biases and generalization capabilities.
By developing techniques to leverage the properties of the perceptual manifold, the researchers have demonstrated the potential to improve the fairness and robustness of state-of-the-art DNN models. This work represents an important step forward in addressing a critical challenge facing the AI community - the need for more equitable and trustworthy machine learning systems.
The paper's findings have broad implications for a wide range of AI applications, from computer vision to natural language processing. As the use of deep learning continues to expand, the ability to unveil and mitigate biases will become increasingly crucial for ensuring that these powerful technologies benefit all members of society.
Overall, this research opens up an exciting new direction for bias mitigation in deep learning, and the authors have laid the groundwork for further exploration and development in this important area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Beyond the noise: intrinsic dimension estimation with optimal neighbourhood identification
Antonio Di Noia, Iuri Macocco, Aldo Glielmo, Alessandro Laio, Antonietta Mira
0
0
The Intrinsic Dimension (ID) is a key concept in unsupervised learning and feature selection, as it is a lower bound to the number of variables which are necessary to describe a system. However, in almost any real-world dataset the ID depends on the scale at which the data are analysed. Quite typically at a small scale, the ID is very large, as the data are affected by measurement errors. At large scale, the ID can also be erroneously large, due to the curvature and the topology of the manifold containing the data. In this work, we introduce an automatic protocol to select the sweet spot, namely the correct range of scales in which the ID is meaningful and useful. This protocol is based on imposing that for distances smaller than the correct scale the density of the data is constant. Since to estimate the density it is necessary to know the ID, this condition is imposed self-consistently. We illustrate the usefulness and robustness of this procedure by benchmarks on artificial and real-world datasets.
5/27/2024

Does Machine Bring in Extra Bias in Learning? Approximating Fairness in Models Promptly
Yijun Bian, Yujie Luo
0
0
Providing various machine learning (ML) applications in the real world, concerns about discrimination hidden in ML models are growing, particularly in high-stakes domains. Existing techniques for assessing the discrimination level of ML models include commonly used group and individual fairness measures. However, these two types of fairness measures are usually hard to be compatible with each other, and even two different group fairness measures might be incompatible as well. To address this issue, we investigate to evaluate the discrimination level of classifiers from a manifold perspective and propose a harmonic fairness measure via manifolds (HFM) based on distances between sets. Yet the direct calculation of distances might be too expensive to afford, reducing its practical applicability. Therefore, we devise an approximation algorithm named Approximation of distance between sets (ApproxDist) to facilitate accurate estimation of distances, and we further demonstrate its algorithmic effectiveness under certain reasonable assumptions. Empirical results indicate that the proposed fairness measure HFM is valid and that the proposed ApproxDist is effective and efficient.
5/16/2024
🧠
Enhancing Fairness in Neural Networks Using FairVIC
Charmaine Barker, Daniel Bethell, Dimitar Kazakov
0
0
Mitigating bias in automated decision-making systems, specifically deep learning models, is a critical challenge in achieving fairness. This complexity stems from factors such as nuanced definitions of fairness, unique biases in each dataset, and the trade-off between fairness and model accuracy. To address such issues, we introduce FairVIC, an innovative approach designed to enhance fairness in neural networks by addressing inherent biases at the training stage. FairVIC differs from traditional approaches that typically address biases at the data preprocessing stage. Instead, it integrates variance, invariance and covariance into the loss function to minimise the model's dependency on protected characteristics for making predictions, thus promoting fairness. Our experimentation and evaluation consists of training neural networks on three datasets known for their biases, comparing our results to state-of-the-art algorithms, evaluating on different sizes of model architectures, and carrying out sensitivity analysis to examine the fairness-accuracy trade-off. Through our implementation of FairVIC, we observed a significant improvement in fairness across all metrics tested, without compromising the model's accuracy to a detrimental extent. Our findings suggest that FairVIC presents a straightforward, out-of-the-box solution for the development of fairer deep learning models, thereby offering a generalisable solution applicable across many tasks and datasets.
4/30/2024
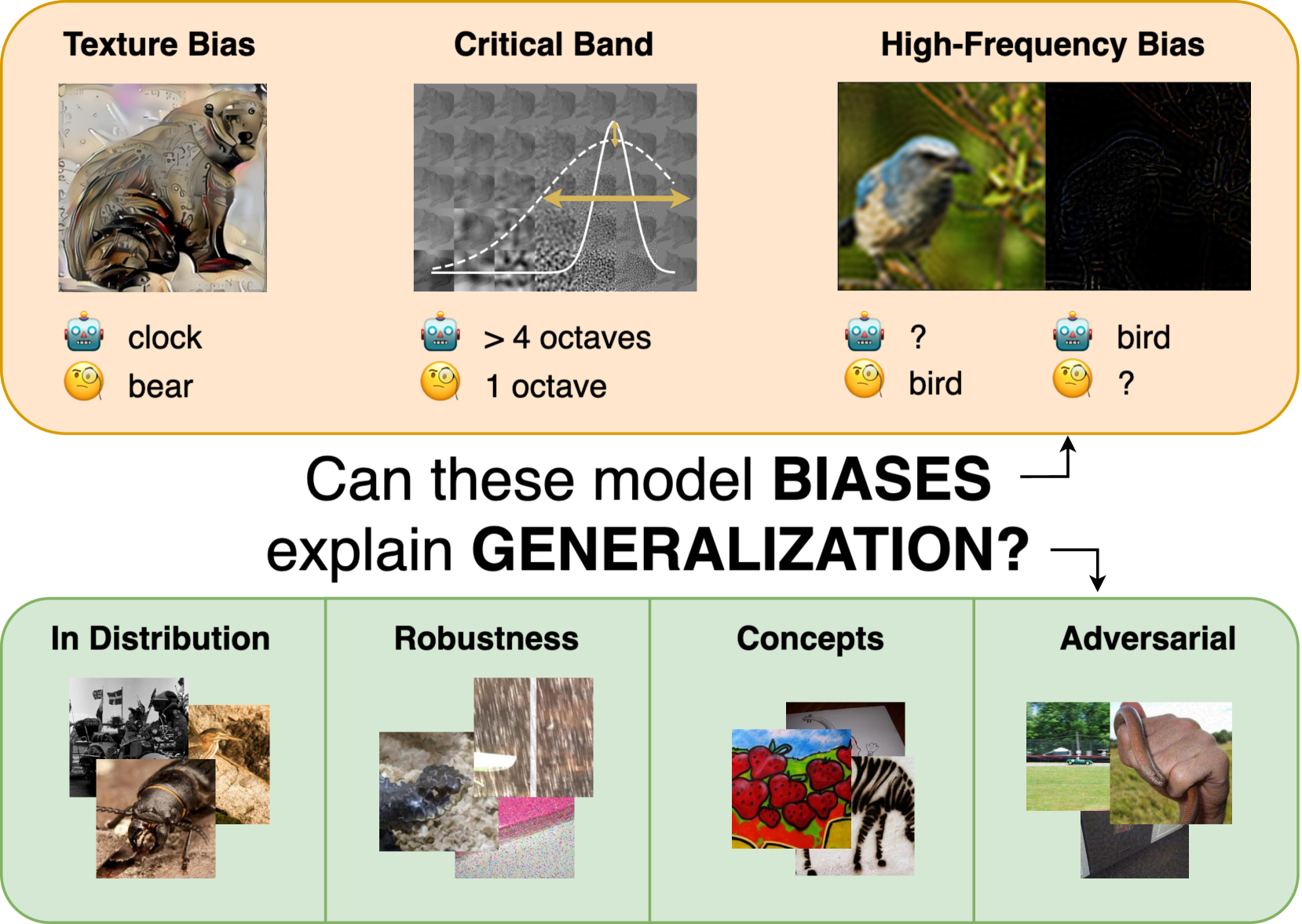
Can Biases in ImageNet Models Explain Generalization?
Paul Gavrikov, Janis Keuper
0
0
The robust generalization of models to rare, in-distribution (ID) samples drawn from the long tail of the training distribution and to out-of-training-distribution (OOD) samples is one of the major challenges of current deep learning methods. For image classification, this manifests in the existence of adversarial attacks, the performance drops on distorted images, and a lack of generalization to concepts such as sketches. The current understanding of generalization in neural networks is very limited, but some biases that differentiate models from human vision have been identified and might be causing these limitations. Consequently, several attempts with varying success have been made to reduce these biases during training to improve generalization. We take a step back and sanity-check these attempts. Fixing the architecture to the well-established ResNet-50, we perform a large-scale study on 48 ImageNet models obtained via different training methods to understand how and if these biases - including shape bias, spectral biases, and critical bands - interact with generalization. Our extensive study results reveal that contrary to previous findings, these biases are insufficient to accurately predict the generalization of a model holistically. We provide access to all checkpoints and evaluation code at https://github.com/paulgavrikov/biases_vs_generalization
4/3/2024