Generalization in diffusion models arises from geometry-adaptive harmonic representations
2310.02557
0
18
🎯
Abstract
Deep neural networks (DNNs) trained for image denoising are able to generate high-quality samples with score-based reverse diffusion algorithms. These impressive capabilities seem to imply an escape from the curse of dimensionality, but recent reports of memorization of the training set raise the question of whether these networks are learning the true continuous density of the data. Here, we show that two DNNs trained on non-overlapping subsets of a dataset learn nearly the same score function, and thus the same density, when the number of training images is large enough. In this regime of strong generalization, diffusion-generated images are distinct from the training set, and are of high visual quality, suggesting that the inductive biases of the DNNs are well-aligned with the data density. We analyze the learned denoising functions and show that the inductive biases give rise to a shrinkage operation in a basis adapted to the underlying image. Examination of these bases reveals oscillating harmonic structures along contours and in homogeneous regions. We demonstrate that trained denoisers are inductively biased towards these geometry-adaptive harmonic bases since they arise not only when the network is trained on photographic images, but also when it is trained on image classes supported on low-dimensional manifolds for which the harmonic basis is suboptimal. Finally, we show that when trained on regular image classes for which the optimal basis is known to be geometry-adaptive and harmonic, the denoising performance of the networks is near-optimal.
Create account to get full access
Overview
- Deep neural networks (DNNs) trained for image denoising can generate high-quality samples using score-based reverse diffusion algorithms.
- However, recent reports of training set memorization raise questions about whether these networks are truly learning the underlying data distribution.
- This paper investigates whether DNNs trained on non-overlapping subsets of a dataset learn the same score function and data density when the training set is large enough.
Plain English Explanation
The paper looks at deep neural networks that have been trained to remove noise from images. These networks have shown impressive capabilities, generating high-quality images by reversing the diffusion process. This suggests the networks have learned a deep understanding of the underlying image data.
However, there have been concerns that the networks might simply be memorizing the training data, rather than learning the true continuous density of the data. To investigate this, the researchers trained two separate networks on non-overlapping subsets of the same dataset. They found that when the dataset was large enough, the two networks learned nearly the same score function - meaning they had learned the same underlying data density.
This suggests the networks' inductive biases are well-aligned with the true data distribution, and the high-quality images they generate are distinct from the training data. The researchers analyze the learned denoising functions and find that the networks are biased towards geometry-adaptive harmonic bases, which can capture important structures in the images.
Importantly, this bias towards harmonic bases arises even when the networks are trained on image classes that are not well-described by such bases, indicating it is a fundamental inductive bias of the networks. When trained on image classes where the optimal basis is known to be harmonic, the networks achieve near-optimal denoising performance.
Technical Explanation
The researchers trained two separate deep neural networks (DNNs) on non-overlapping subsets of a dataset and found that when the dataset was large enough, the two networks learned nearly the same score function. The score function is a key component of score-based generative models like the ones used to generate high-quality samples from the trained DNNs.
This suggests that in the regime of strong generalization, the inductive biases of the DNNs are well-aligned with the true underlying data density, and the generated samples are distinct from the training set.
Analysis of the learned denoising functions reveals that the networks are biased towards geometry-adaptive harmonic bases, which can efficiently capture important structures in the images, such as oscillating patterns along contours and in homogeneous regions. Interestingly, this bias arises even when the networks are trained on image classes that are not well-described by harmonic bases, indicating it is a fundamental inductive bias of the architecture.
When the networks are trained on image classes for which the optimal basis is known to be geometry-adaptive and harmonic, they achieve near-optimal denoising performance. This further supports the idea that the networks' inductive biases are well-matched to the true data distribution, allowing them to learn efficient representations.
Critical Analysis
The paper provides compelling evidence that deep neural networks trained for image denoising are learning the true underlying data distribution, rather than simply memorizing the training set. The finding that two networks trained on non-overlapping subsets learn the same score function is a strong indicator of generalization.
However, the paper does not address the scalability of this approach. The researchers used a relatively small dataset (CIFAR-10) and it's unclear whether the same level of generalization would be observed with larger, more complex datasets like ImageNet.
Additionally, the analysis of the learned denoising functions and the networks' bias towards harmonic bases is intriguing, but the paper does not provide a theoretical explanation for why this bias arises. Further research is needed to understand the underlying mechanisms that give rise to this inductive bias.
Overall, the paper makes a valuable contribution to our understanding of how deep neural networks learn representations of image data, and suggests that these models may be able to escape the curse of dimensionality under certain conditions. However, more work is needed to fully characterize the capabilities and limitations of these approaches.
Conclusion
This paper provides evidence that deep neural networks trained for image denoising can learn the true underlying data distribution, rather than simply memorizing the training set. By training two networks on non-overlapping subsets of a dataset, the researchers show that the networks converge to the same score function, indicating strong generalization.
Analysis of the learned denoising functions reveals that the networks are biased towards geometry-adaptive harmonic bases, which can efficiently capture important structures in the images. This bias arises even for image classes that are not well-described by harmonic bases, suggesting it is a fundamental inductive bias of the architecture.
These findings have important implications for the development of efficient and robust generative models that can escape the curse of dimensionality. Further research is needed to understand the scalability of these approaches and the theoretical underpinnings of the observed inductive biases.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
Denoising: from classical methods to deep CNNs
Jean-Eric Campagne
0
0
This paper aims to explore the evolution of image denoising in a pedagological way. We briefly review classical methods such as Fourier analysis and wavelet bases, highlighting the challenges they faced until the emergence of neural networks, notably the U-Net, in the 2010s. The remarkable performance of these networks has been demonstrated in studies such as Kadkhodaie et al. (2024). They exhibit adaptability to various image types, including those with fixed regularity, facial images, and bedroom scenes, achieving optimal results and biased towards geometry-adaptive harmonic basis. The introduction of score diffusion has played a crucial role in image generation. In this context, denoising becomes essential as it facilitates the estimation of probability density scores. We discuss the prerequisites for genuine learning of probability densities, offering insights that extend from mathematical research to the implications of universal structures.
4/30/2024
✅
Physics-Informed Diffusion Models
Jan-Hendrik Bastek, WaiChing Sun, Dennis M. Kochmann
0
0
Generative models such as denoising diffusion models are quickly advancing their ability to approximate highly complex data distributions. They are also increasingly leveraged in scientific machine learning, where samples from the implied data distribution are expected to adhere to specific governing equations. We present a framework to inform denoising diffusion models of underlying constraints on such generated samples during model training. Our approach improves the alignment of the generated samples with the imposed constraints and significantly outperforms existing methods without affecting inference speed. Additionally, our findings suggest that incorporating such constraints during training provides a natural regularization against overfitting. Our framework is easy to implement and versatile in its applicability for imposing equality and inequality constraints as well as auxiliary optimization objectives.
5/24/2024
🛠️
Interpreting and Improving Diffusion Models from an Optimization Perspective
Frank Permenter, Chenyang Yuan
0
0
Denoising is intuitively related to projection. Indeed, under the manifold hypothesis, adding random noise is approximately equivalent to orthogonal perturbation. Hence, learning to denoise is approximately learning to project. In this paper, we use this observation to interpret denoising diffusion models as approximate gradient descent applied to the Euclidean distance function. We then provide straight-forward convergence analysis of the DDIM sampler under simple assumptions on the projection error of the denoiser. Finally, we propose a new gradient-estimation sampler, generalizing DDIM using insights from our theoretical results. In as few as 5-10 function evaluations, our sampler achieves state-of-the-art FID scores on pretrained CIFAR-10 and CelebA models and can generate high quality samples on latent diffusion models.
6/4/2024
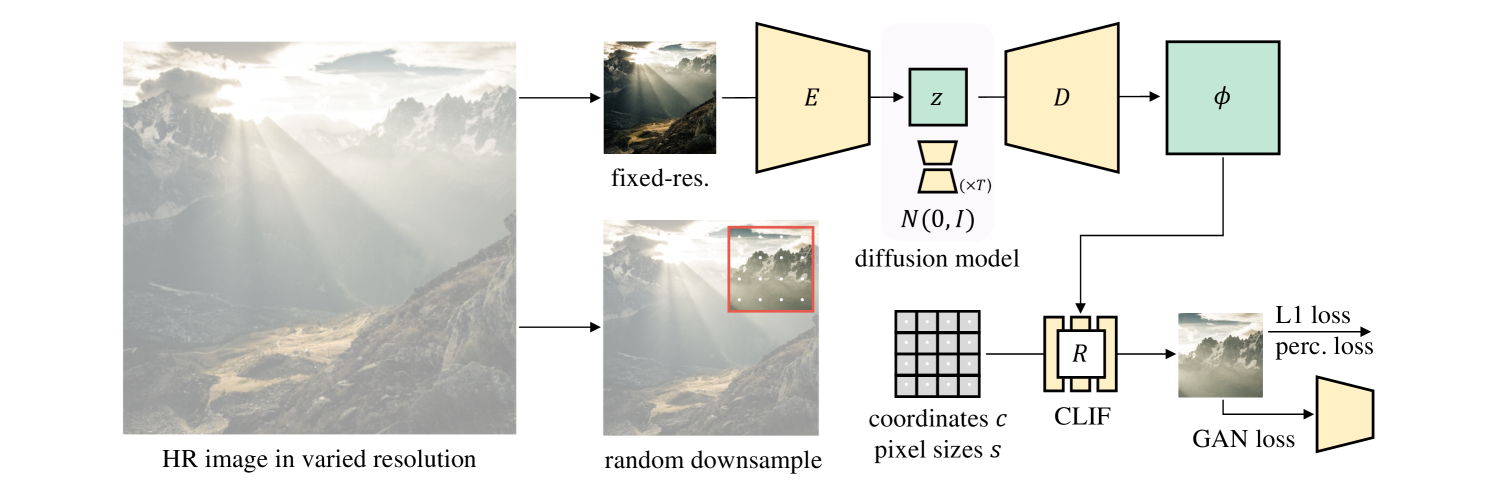
Image Neural Field Diffusion Models
Yinbo Chen, Oliver Wang, Richard Zhang, Eli Shechtman, Xiaolong Wang, Michael Gharbi
0
0
Diffusion models have shown an impressive ability to model complex data distributions, with several key advantages over GANs, such as stable training, better coverage of the training distribution's modes, and the ability to solve inverse problems without extra training. However, most diffusion models learn the distribution of fixed-resolution images. We propose to learn the distribution of continuous images by training diffusion models on image neural fields, which can be rendered at any resolution, and show its advantages over fixed-resolution models. To achieve this, a key challenge is to obtain a latent space that represents photorealistic image neural fields. We propose a simple and effective method, inspired by several recent techniques but with key changes to make the image neural fields photorealistic. Our method can be used to convert existing latent diffusion autoencoders into image neural field autoencoders. We show that image neural field diffusion models can be trained using mixed-resolution image datasets, outperform fixed-resolution diffusion models followed by super-resolution models, and can solve inverse problems with conditions applied at different scales efficiently.
6/12/2024