Unveiling Narrative Reasoning Limits of Large Language Models with Trope in Movie Synopses

0

Sign in to get full access
Overview
- Examines the narrative reasoning limits of large language models (LLMs) using movie synopses
- Leverages "trope" - a common storytelling device or motif - to test LLM capabilities
- Finds that LLMs struggle to reason about complex narrative structures and character motivations
Plain English Explanation
This research paper investigates the limits of large language models's ability to understand and reason about complex narratives, such as those found in movie plots. The researchers use the concept of "trope" - a common storytelling element or pattern - as a way to test the narrative reasoning capabilities of these powerful AI models.
The key finding is that while LLMs excel at many language-related tasks, they struggle when it comes to comprehending the nuanced character motivations and intricate plot structures that are central to storytelling. The models often fail to grasp the deeper significance of tropes and how they shape the narrative arc.
This suggests that current LLMs, despite their impressive capabilities, still have significant limitations when it comes to the type of holistic, contextual reasoning required to truly understand human-crafted stories. Overcoming these limitations will be an important challenge as these models are increasingly applied to higher-level language tasks.
Technical Explanation
The paper first provides an overview of related work on assessing the reasoning abilities of LLMs, including efforts to test their video comprehension and multi-step logical reasoning skills.
The core of the study involves using a large dataset of movie synopses annotated with common tropes. The researchers then prompt LLMs to generate continuations of these synopses, evaluating how well the models can reason about the narrative implications of the tropes and extend the story in a coherent manner.
Through extensive experiments, the paper demonstrates that LLMs struggle to capture the deeper significance of tropes and incorporate them into plausible story extensions. The models often produce outputs that are logically inconsistent or fail to build on the established narrative context.
The authors argue that this points to fundamental limitations in the narrative reasoning capabilities of current LLMs, which tend to rely heavily on surface-level pattern matching rather than deeper understanding of storytelling structure and character motivations.
Critical Analysis
The paper provides a thoughtful and nuanced analysis of the shortcomings of LLMs when it comes to narrative reasoning. The use of tropes as a testing framework is a clever way to probe the models' understanding of common storytelling devices and their role in driving plot and character development.
However, the study is limited to text-based movie synopses, and it remains to be seen how LLMs would perform on more visually-rich narrative formats, such as film or television. Additionally, the paper does not explore potential methods for improving the narrative reasoning abilities of LLMs, which could be a valuable avenue for future research.
While the findings are concerning for those hoping to deploy LLMs in applications that require deep narrative understanding, the authors are careful to maintain an objective, analytical tone. They acknowledge the impressive capabilities of these models in other domains and encourage readers to think critically about the limitations uncovered in this study.
Conclusion
This research paper sheds important light on the narrative reasoning limits of current large language models, using the concept of "trope" as a lens to probe their understanding of storytelling structure and character motivation. The key finding is that LLMs struggle to coherently extend narratives in a way that fully captures the significance of common storytelling devices.
These results suggest that while LLMs excel at many language-related tasks, there are still significant hurdles to overcome in developing AI systems that can truly comprehend and reason about complex, human-crafted stories. Addressing these limitations will be an important challenge as these models are increasingly deployed in real-world applications that require a deeper, more contextual understanding of language and narrative.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Unveiling Narrative Reasoning Limits of Large Language Models with Trope in Movie Synopses
Hung-Ting Su, Ya-Ching Hsu, Xudong Lin, Xiang-Qian Shi, Yulei Niu, Han-Yuan Hsu, Hung-yi Lee, Winston H. Hsu
Large language models (LLMs) equipped with chain-of-thoughts (CoT) prompting have shown significant multi-step reasoning capabilities in factual content like mathematics, commonsense, and logic. However, their performance in narrative reasoning, which demands greater abstraction capabilities, remains unexplored. This study utilizes tropes in movie synopses to assess the abstract reasoning abilities of state-of-the-art LLMs and uncovers their low performance. We introduce a trope-wise querying approach to address these challenges and boost the F1 score by 11.8 points. Moreover, while prior studies suggest that CoT enhances multi-step reasoning, this study shows CoT can cause hallucinations in narrative content, reducing GPT-4's performance. We also introduce an Adversarial Injection method to embed trope-related text tokens into movie synopses without explicit tropes, revealing CoT's heightened sensitivity to such injections. Our comprehensive analysis provides insights for future research directions.
Read more9/24/2024
0
Investigating Video Reasoning Capability of Large Language Models with Tropes in Movies
Hung-Ting Su, Chun-Tong Chao, Ya-Ching Hsu, Xudong Lin, Yulei Niu, Hung-Yi Lee, Winston H. Hsu
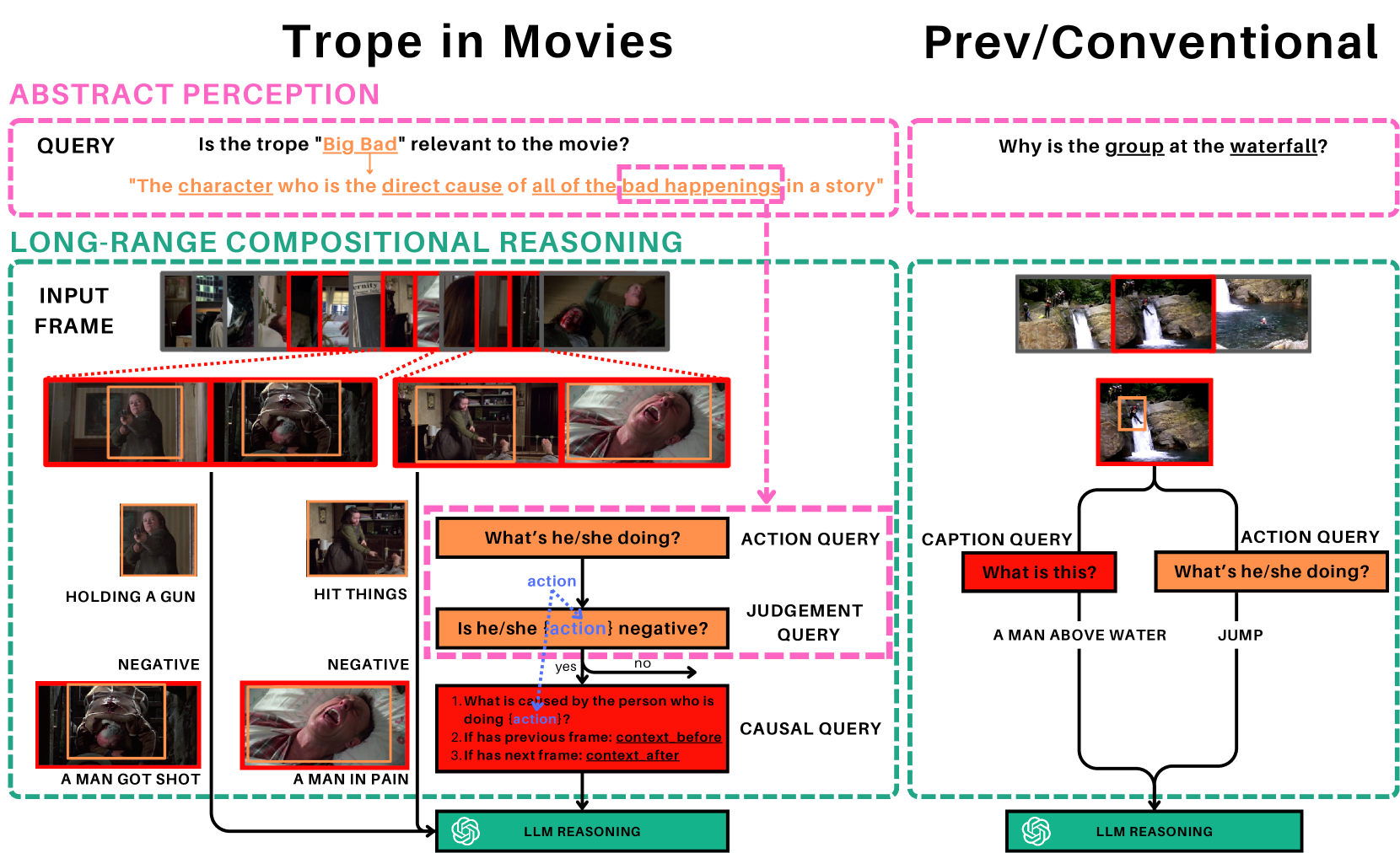
Large Language Models (LLMs) have demonstrated effectiveness not only in language tasks but also in video reasoning. This paper introduces a novel dataset, Tropes in Movies (TiM), designed as a testbed for exploring two critical yet previously overlooked video reasoning skills: (1) Abstract Perception: understanding and tokenizing abstract concepts in videos, and (2) Long-range Compositional Reasoning: planning and integrating intermediate reasoning steps for understanding long-range videos with numerous frames. Utilizing tropes from movie storytelling, TiM evaluates the reasoning capabilities of state-of-the-art LLM-based approaches. Our experiments show that current methods, including Captioner-Reasoner, Large Multimodal Model Instruction Fine-tuning, and Visual Programming, only marginally outperform a random baseline when tackling the challenges of Abstract Perception and Long-range Compositional Reasoning. To address these deficiencies, we propose Face-Enhanced Viper of Role Interactions (FEVoRI) and Context Query Reduction (ConQueR), which enhance Visual Programming by fostering role interaction awareness and progressively refining movie contexts and trope queries during reasoning processes, significantly improving performance by 15 F1 points. However, this performance still lags behind human levels (40 vs. 65 F1). Additionally, we introduce a new protocol to evaluate the necessity of Abstract Perception and Long-range Compositional Reasoning for task resolution. This is done by analyzing the code generated through Visual Programming using an Abstract Syntax Tree (AST), thereby confirming the increased complexity of TiM. The dataset and code are available at: https://ander1119.github.io/TiM
Read more6/18/2024
💬
28
Multimodal Chain-of-Thought Reasoning in Language Models
Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, Alex Smola
Large language models (LLMs) have shown impressive performance on complex reasoning by leveraging chain-of-thought (CoT) prompting to generate intermediate reasoning chains as the rationale to infer the answer. However, existing CoT studies have primarily focused on the language modality. We propose Multimodal-CoT that incorporates language (text) and vision (images) modalities into a two-stage framework that separates rationale generation and answer inference. In this way, answer inference can leverage better generated rationales that are based on multimodal information. Experimental results on ScienceQA and A-OKVQA benchmark datasets show the effectiveness of our proposed approach. With Multimodal-CoT, our model under 1 billion parameters achieves state-of-the-art performance on the ScienceQA benchmark. Our analysis indicates that Multimodal-CoT offers the advantages of mitigating hallucination and enhancing convergence speed. Code is publicly available at https://github.com/amazon-science/mm-cot.
Read more5/21/2024
🌿
65
Chain-of-Thought Reasoning Without Prompting
Xuezhi Wang, Denny Zhou
In enhancing the reasoning capabilities of large language models (LLMs), prior research primarily focuses on specific prompting techniques such as few-shot or zero-shot chain-of-thought (CoT) prompting. These methods, while effective, often involve manually intensive prompt engineering. Our study takes a novel approach by asking: Can LLMs reason effectively without prompting? Our findings reveal that, intriguingly, CoT reasoning paths can be elicited from pre-trained LLMs by simply altering the textit{decoding} process. Rather than conventional greedy decoding, we investigate the top-$k$ alternative tokens, uncovering that CoT paths are frequently inherent in these sequences. This approach not only bypasses the confounders of prompting but also allows us to assess the LLMs' textit{intrinsic} reasoning abilities. Moreover, we observe that the presence of a CoT in the decoding path correlates with a higher confidence in the model's decoded answer. This confidence metric effectively differentiates between CoT and non-CoT paths. Extensive empirical studies on various reasoning benchmarks show that the proposed CoT-decoding effectively elicits reasoning capabilities from language models, which were previously obscured by standard greedy decoding.
Read more5/27/2024