Investigating Video Reasoning Capability of Large Language Models with Tropes in Movies

0
Sign in to get full access
Overview
- This paper investigates the video reasoning capabilities of large language models (LLMs) by analyzing their ability to identify and understand common movie tropes.
- The researchers evaluate several state-of-the-art LLMs on a novel video-based trope classification task, testing their ability to recognize and reason about different narrative patterns and storytelling devices often found in movies.
- The findings provide insights into the current strengths and limitations of LLMs when it comes to video-based reasoning and understanding higher-level semantic concepts.
Plain English Explanation
The researchers in this paper wanted to see how well large language models (LLMs) - powerful AI systems trained on massive amounts of text data - can understand and reason about the common storytelling techniques and narrative patterns found in movies. They created a new task where the models had to identify different "tropes" - familiar plot devices, character archetypes, or other recurring elements often used in films and TV shows.
By testing the LLMs on this trope classification task, the researchers could assess the models' ability to go beyond just recognizing individual objects or events in a video and instead grasp higher-level semantic concepts related to story, character, and theme. This provides insights into the current video understanding capabilities of these large language models and where there may still be room for improvement.
For example, can an LLM recognize when a character is going through a "fish out of water" storyline, where they are placed in an unfamiliar environment? Or can it detect classic villain tropes like the "evil genius" or "femme fatale"? The findings from this study shed light on the strengths and limitations of LLMs when it comes to this type of video-based reasoning and narrative comprehension.
Technical Explanation
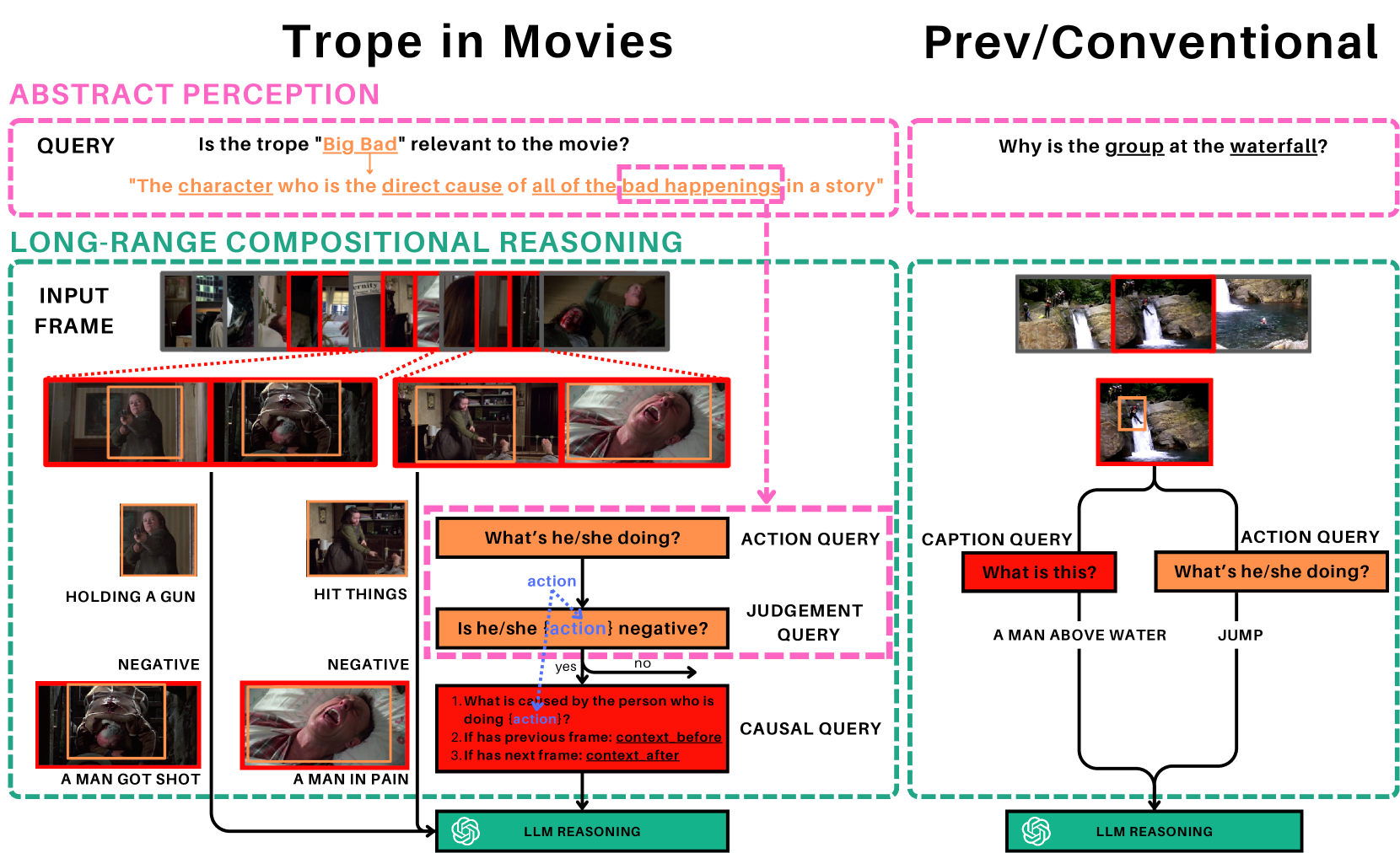
The paper introduces a novel video-based trope classification task to evaluate the reasoning capabilities of large language models (LLMs) on higher-level semantic concepts related to storytelling and narrative. The task involves classifying short video clips into one of 30 different movie tropes, such as "fish out of water," "evil genius," or "femme fatale."
The researchers evaluate several state-of-the-art LLMs, including MOMENTOR, VideoTree, and How Good Is My Video LMM, on this trope classification task. They find that while the LLMs demonstrate some ability to recognize certain tropes, there are still significant limitations in their video reasoning abilities compared to human performance.
The paper also explores the relationship between the LLMs' text-based and video-based reasoning capabilities, finding that text-based performance is not always a reliable indicator of video understanding. The researchers suggest that further advancements in areas like temporal reasoning and zero-shot compositional reasoning will be crucial for improving the video understanding of LLMs.
Critical Analysis
The researchers acknowledge several limitations of their study, including the relatively small size of the trope dataset and the potential biases introduced by the specific tropes chosen. They also note that the trope classification task may not fully capture the depth and nuance of how humans understand narrative structures in movies.
Additionally, while the paper provides valuable insights into the current video reasoning capabilities of LLMs, it does not offer a comprehensive solution or clear roadmap for addressing the identified limitations. The researchers suggest further research is needed to better understand the factors that contribute to effective video-based reasoning in LLMs.
One could also argue that the trope classification task, while interesting, may not be the most representative or pressing challenge for real-world video understanding applications. The researchers could have considered a broader range of video-based tasks and benchmarks to more fully assess the LLMs' capabilities.
Conclusion
This paper makes an important contribution to the ongoing research on the video understanding capabilities of large language models. By introducing a novel trope classification task and evaluating several state-of-the-art LLMs, the researchers provide valuable insights into the current strengths and limitations of these models when it comes to reasoning about higher-level semantic concepts in video data.
The findings suggest that while LLMs have made significant progress in natural language processing, there is still room for improvement in their ability to comprehend and reason about complex narrative structures and storytelling devices. Addressing these shortcomings will be crucial for developing LLMs that can truly understand and engage with the rich visual and narrative content that is ubiquitous in the modern digital landscape.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Investigating Video Reasoning Capability of Large Language Models with Tropes in Movies
Hung-Ting Su, Chun-Tong Chao, Ya-Ching Hsu, Xudong Lin, Yulei Niu, Hung-Yi Lee, Winston H. Hsu
Large Language Models (LLMs) have demonstrated effectiveness not only in language tasks but also in video reasoning. This paper introduces a novel dataset, Tropes in Movies (TiM), designed as a testbed for exploring two critical yet previously overlooked video reasoning skills: (1) Abstract Perception: understanding and tokenizing abstract concepts in videos, and (2) Long-range Compositional Reasoning: planning and integrating intermediate reasoning steps for understanding long-range videos with numerous frames. Utilizing tropes from movie storytelling, TiM evaluates the reasoning capabilities of state-of-the-art LLM-based approaches. Our experiments show that current methods, including Captioner-Reasoner, Large Multimodal Model Instruction Fine-tuning, and Visual Programming, only marginally outperform a random baseline when tackling the challenges of Abstract Perception and Long-range Compositional Reasoning. To address these deficiencies, we propose Face-Enhanced Viper of Role Interactions (FEVoRI) and Context Query Reduction (ConQueR), which enhance Visual Programming by fostering role interaction awareness and progressively refining movie contexts and trope queries during reasoning processes, significantly improving performance by 15 F1 points. However, this performance still lags behind human levels (40 vs. 65 F1). Additionally, we introduce a new protocol to evaluate the necessity of Abstract Perception and Long-range Compositional Reasoning for task resolution. This is done by analyzing the code generated through Visual Programming using an Abstract Syntax Tree (AST), thereby confirming the increased complexity of TiM. The dataset and code are available at: https://ander1119.github.io/TiM
Read more6/18/2024

0
Unveiling Narrative Reasoning Limits of Large Language Models with Trope in Movie Synopses
Hung-Ting Su, Ya-Ching Hsu, Xudong Lin, Xiang-Qian Shi, Yulei Niu, Han-Yuan Hsu, Hung-yi Lee, Winston H. Hsu
Large language models (LLMs) equipped with chain-of-thoughts (CoT) prompting have shown significant multi-step reasoning capabilities in factual content like mathematics, commonsense, and logic. However, their performance in narrative reasoning, which demands greater abstraction capabilities, remains unexplored. This study utilizes tropes in movie synopses to assess the abstract reasoning abilities of state-of-the-art LLMs and uncovers their low performance. We introduce a trope-wise querying approach to address these challenges and boost the F1 score by 11.8 points. Moreover, while prior studies suggest that CoT enhances multi-step reasoning, this study shows CoT can cause hallucinations in narrative content, reducing GPT-4's performance. We also introduce an Adversarial Injection method to embed trope-related text tokens into movie synopses without explicit tropes, revealing CoT's heightened sensitivity to such injections. Our comprehensive analysis provides insights for future research directions.
Read more9/24/2024

0
Towards Neuro-Symbolic Video Understanding
Minkyu Choi, Harsh Goel, Mohammad Omama, Yunhao Yang, Sahil Shah, Sandeep Chinchali
The unprecedented surge in video data production in recent years necessitates efficient tools to extract meaningful frames from videos for downstream tasks. Long-term temporal reasoning is a key desideratum for frame retrieval systems. While state-of-the-art foundation models, like VideoLLaMA and ViCLIP, are proficient in short-term semantic understanding, they surprisingly fail at long-term reasoning across frames. A key reason for this failure is that they intertwine per-frame perception and temporal reasoning into a single deep network. Hence, decoupling but co-designing semantic understanding and temporal reasoning is essential for efficient scene identification. We propose a system that leverages vision-language models for semantic understanding of individual frames but effectively reasons about the long-term evolution of events using state machines and temporal logic (TL) formulae that inherently capture memory. Our TL-based reasoning improves the F1 score of complex event identification by 9-15% compared to benchmarks that use GPT4 for reasoning on state-of-the-art self-driving datasets such as Waymo and NuScenes.
Read more7/17/2024
0
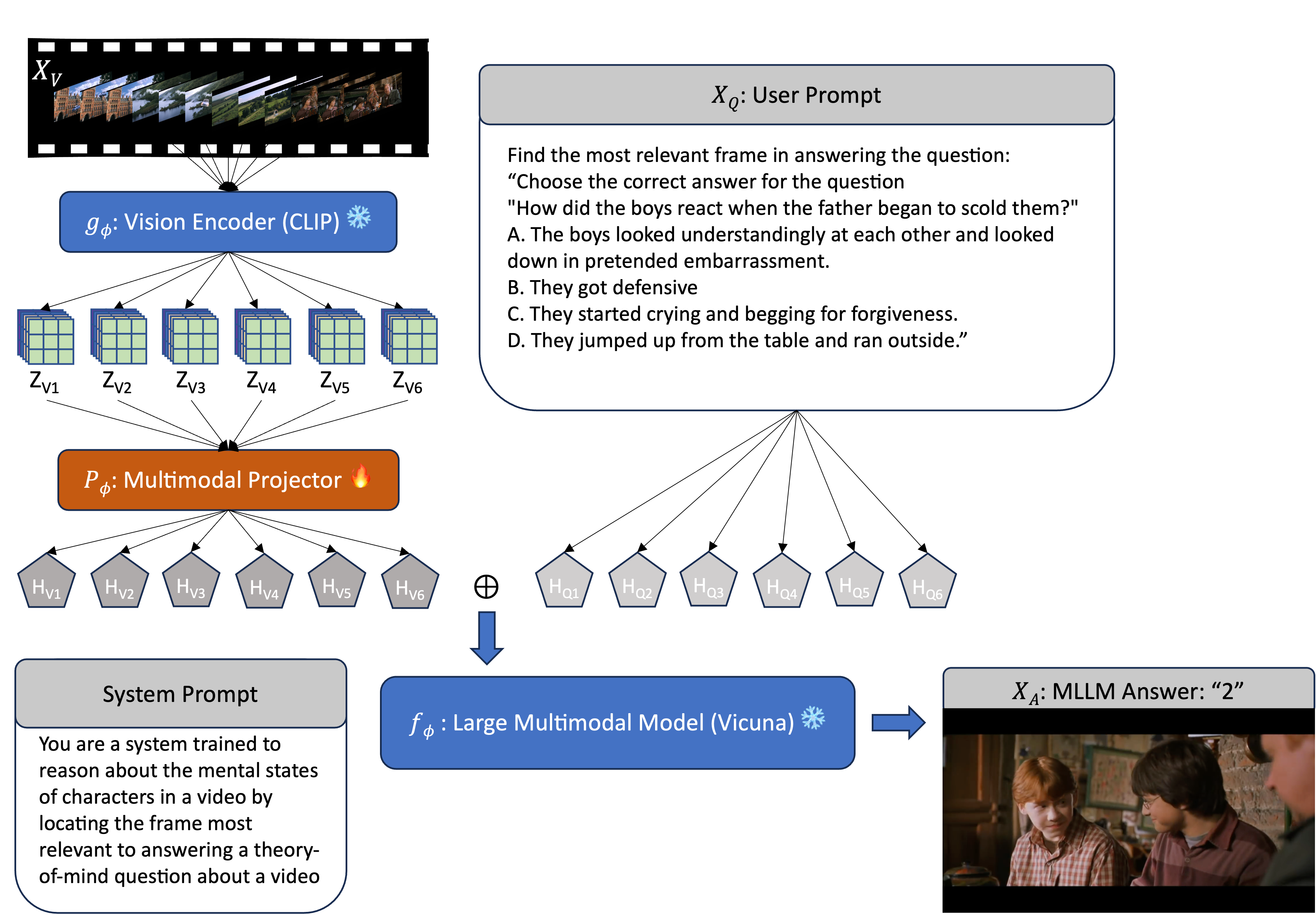
Through the Theory of Mind's Eye: Reading Minds with Multimodal Video Large Language Models
Zhawnen Chen, Tianchun Wang, Yizhou Wang, Michal Kosinski, Xiang Zhang, Yun Fu, Sheng Li
Can large multimodal models have a human-like ability for emotional and social reasoning, and if so, how does it work? Recent research has discovered emergent theory-of-mind (ToM) reasoning capabilities in large language models (LLMs). LLMs can reason about people's mental states by solving various text-based ToM tasks that ask questions about the actors' ToM (e.g., human belief, desire, intention). However, human reasoning in the wild is often grounded in dynamic scenes across time. Thus, we consider videos a new medium for examining spatio-temporal ToM reasoning ability. Specifically, we ask explicit probing questions about videos with abundant social and emotional reasoning content. We develop a pipeline for multimodal LLM for ToM reasoning using video and text. We also enable explicit ToM reasoning by retrieving key frames for answering a ToM question, which reveals how multimodal LLMs reason about ToM.
Read more6/21/2024