User-Driven Voice Generation and Editing through Latent Space Navigation

0

Sign in to get full access
Overview
- This paper presents a method for user-driven voice generation and editing through latent space navigation.
- The proposed approach allows users to customize and edit voice characteristics in a flexible and intuitive way.
- The system utilizes disentangled edit directions in the latent space to enable fine-grained control over voice attributes.
Plain English Explanation
The paper introduces a new way for users to generate and edit voices. Typically, voice generation and editing can be a complex and technical process, requiring specialized knowledge and skills. However, this research aims to make it more accessible and intuitive for regular users.
The key idea is to map voice characteristics to a "latent space" - a mathematical representation where different voice attributes are separated out and can be manipulated independently. This allows users to navigate this latent space and adjust specific aspects of the voice, such as pitch, timbre, or accent, without affecting other traits.
By providing this level of fine-grained control, the system enables users to customize voices in a more natural and expressive way, similar to how they might edit an image or adjust the settings on a musical instrument. This could have applications in text-to-speech, voice conversion, and other voice-related technologies.
Technical Explanation
The paper proposes a framework for user-driven voice generation and editing that leverages a disentangled latent space representation. The key components include:
-
Voice Encoder: A neural network that maps input voice samples into a high-dimensional latent space, where different voice attributes are disentangled.
-
Voice Decoder: A separate network that can generate voice samples from the latent space representation.
-
Latent Space Navigation: The system allows users to navigate the latent space and make targeted edits to specific voice characteristics, such as pitch, timbre, or accent, by adjusting the corresponding latent dimensions.
-
Disentangled Edit Directions: The researchers identify meaningful edit directions in the latent space that correspond to intuitive voice attributes. This enables fine-grained control over the voice generation process.
The authors evaluate their approach through both objective and subjective measures, demonstrating its effectiveness at generating high-quality, customized voices that match user preferences.
Critical Analysis
The paper presents a compelling approach for user-driven voice generation and editing, addressing an important challenge in making voice customization more accessible and intuitive. The use of a disentangled latent space representation is a key strength, as it allows for targeted and interpretable control over voice characteristics.
However, the paper does not extensively discuss potential limitations or caveats of the proposed system. For example, it would be helpful to understand the system's robustness to different speaker profiles, its ability to handle diverse voice types and emotions, and the scalability of the approach to larger datasets.
Additionally, the paper could have delved deeper into the ethical implications of such technology, particularly around the potential for misuse in areas like deepfakes or voice impersonation. Addressing these concerns would help readers better understand the broader societal impact of the research.
Conclusion
This paper introduces an innovative approach to user-driven voice generation and editing that leverages disentangled latent space representations. By providing fine-grained control over voice attributes, the system enables users to customize and personalize voices in an intuitive and expressive manner.
The proposed framework has the potential to significantly impact a wide range of voice-related applications, from text-to-speech to voice conversion. While the paper demonstrates the technical feasibility of the approach, future research should also consider the broader ethical and societal implications of such technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
User-Driven Voice Generation and Editing through Latent Space Navigation
Yusheng Tian, Junbin Liu, Tan Lee
This paper presents a user-driven approach for synthesizing highly specific target voices based on user feedback, which is particularly beneficial for speech-impaired individuals who wish to recreate their lost voices but lack prior recordings. Specifically, we leverage the neural analysis and synthesis framework to construct a low-dimensional, yet sufficiently expressive latent speaker embedding space. Within this latent space, we implement a search algorithm that guides users to their desired voice through completing a sequence of straightforward comparison tasks. Both synthetic simulations and real-world user studies demonstrate that the proposed approach can effectively approximate target voices. Moreover, by analyzing the mel-spectrogram generator's Jacobians, we identify a set of meaningful voice editing directions within the latent space. These directions enable users to further fine-tune specific attributes of the generated voice, including the pitch level, pitch range, volume, vocal tension, nasality, and tone color. Audio samples are available at https://myspeechprojects.github.io/voicedesign/.
Read more9/10/2024
0
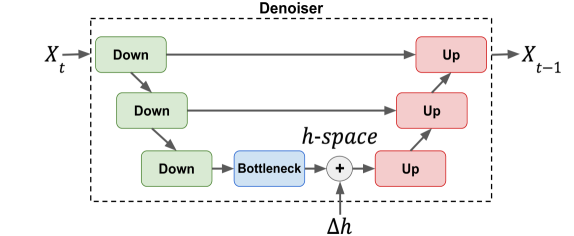
On the Semantic Latent Space of Diffusion-Based Text-to-Speech Models
Miri Varshavsky-Hassid, Roy Hirsch, Regev Cohen, Tomer Golany, Daniel Freedman, Ehud Rivlin
The incorporation of Denoising Diffusion Models (DDMs) in the Text-to-Speech (TTS) domain is rising, providing great value in synthesizing high quality speech. Although they exhibit impressive audio quality, the extent of their semantic capabilities is unknown, and controlling their synthesized speech's vocal properties remains a challenge. Inspired by recent advances in image synthesis, we explore the latent space of frozen TTS models, which is composed of the latent bottleneck activations of the DDM's denoiser. We identify that this space contains rich semantic information, and outline several novel methods for finding semantic directions within it, both supervised and unsupervised. We then demonstrate how these enable off-the-shelf audio editing, without any further training, architectural changes or data requirements. We present evidence of the semantic and acoustic qualities of the edited audio, and provide supplemental samples: https://latent-analysis-grad-tts.github.io/speech-samples/.
Read more6/5/2024

0
A Mapping Strategy for Interacting with Latent Audio Synthesis Using Artistic Materials
Shuoyang Zheng, Anna Xamb'o Sed'o, Nick Bryan-Kinns
This paper presents a mapping strategy for interacting with the latent spaces of generative AI models. Our approach involves using unsupervised feature learning to encode a human control space and mapping it to an audio synthesis model's latent space. To demonstrate how this mapping strategy can turn high-dimensional sensor data into control mechanisms of a deep generative model, we present a proof-of-concept system that uses visual sketches to control an audio synthesis model. We draw on emerging discourses in XAIxArts to discuss how this approach can contribute to XAI in artistic and creative contexts, we also discuss its current limitations and propose future research directions.
Read more7/8/2024
🛸
0
SwapTalk: Audio-Driven Talking Face Generation with One-Shot Customization in Latent Space
Zeren Zhang, Haibo Qin, Jiayu Huang, Yixin Li, Hui Lin, Yitao Duan, Jinwen Ma
Combining face swapping with lip synchronization technology offers a cost-effective solution for customized talking face generation. However, directly cascading existing models together tends to introduce significant interference between tasks and reduce video clarity because the interaction space is limited to the low-level semantic RGB space. To address this issue, we propose an innovative unified framework, SwapTalk, which accomplishes both face swapping and lip synchronization tasks in the same latent space. Referring to recent work on face generation, we choose the VQ-embedding space due to its excellent editability and fidelity performance. To enhance the framework's generalization capabilities for unseen identities, we incorporate identity loss during the training of the face swapping module. Additionally, we introduce expert discriminator supervision within the latent space during the training of the lip synchronization module to elevate synchronization quality. In the evaluation phase, previous studies primarily focused on the self-reconstruction of lip movements in synchronous audio-visual videos. To better approximate real-world applications, we expand the evaluation scope to asynchronous audio-video scenarios. Furthermore, we introduce a novel identity consistency metric to more comprehensively assess the identity consistency over time series in generated facial videos. Experimental results on the HDTF demonstrate that our method significantly surpasses existing techniques in video quality, lip synchronization accuracy, face swapping fidelity, and identity consistency. Our demo is available at http://swaptalk.cc.
Read more5/10/2024