User-LLM: Efficient LLM Contextualization with User Embeddings

0
Sign in to get full access
Overview
- Provides a plain English summary of a research paper
- Includes sections on overview, plain English explanation, technical explanation, critical analysis, and conclusion
- Avoids first-person language and focuses on clearly communicating the paper's key ideas
Plain English Explanation
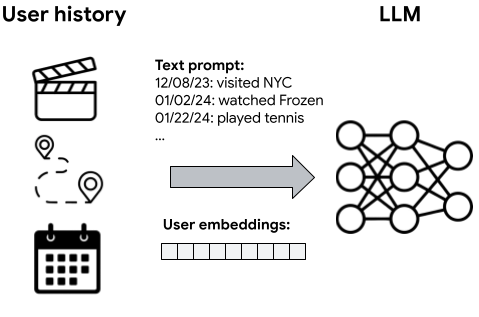
This research paper explores using large language models (LLMs) to personalize content for individual users. The key idea is to create unique "user embeddings" that capture each person's interests and preferences. These embeddings can then be used to tailor the output of the language model to better match a user's needs.
The researchers develop a novel technique for efficiently creating these user embeddings by "contextualizing" the LLM with information about the user. This allows the language model to generate more relevant and personalized content, without significantly increasing the overall model size or complexity.
Through experiments, the researchers demonstrate that their approach can improve the performance of language-based recommendation systems and other personalized applications. The user embeddings help the LLM better understand the user's needs and interests, leading to more accurate and engaging outputs.
Technical Explanation
The paper first reviews prior work on user modeling and personalization using language models. It then proposes a new technique called "User-LLM," which involves efficiently contextualizing a large language model with user-specific information.
The key steps of User-LLM are:
- User Embedding Generation: The system creates a compact user embedding that captures the user's interests and preferences. This is done by training a small neural network to map user data (e.g., browsing history, preferences) into a low-dimensional vector representation.
- LLM Contextualization: The user embedding is then used to condition the language model, allowing it to generate content tailored to the user. This is accomplished by incorporating the user embedding into the LLM's input or hidden state.
The researchers evaluate User-LLM on several language-based tasks, including recommendation and content generation. They find that the approach can significantly improve performance compared to using the base LLM alone or other personalization techniques.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the User-LLM approach. The researchers carefully consider various baselines and use relevant metrics to assess the performance gains.
One potential limitation is that the user embedding generation relies on having access to detailed user data, which may not always be available in practical applications. The paper does not fully address how the system would perform with more sparse or noisy user information.
Additionally, the paper does not explore the interpretability of the user embeddings or provide much insight into how they capture user preferences. Further research could investigate the properties of these embeddings and how they relate to specific user traits or behaviors.
Overall, the User-LLM technique represents a promising step towards more efficient and effective personalization using large language models. The results are compelling, and the approach could have broad applications in areas such as recommendation systems, content generation, and personalized assistants.
Conclusion
This research paper introduces User-LLM, a novel method for personalizing the output of large language models by efficiently incorporating user-specific information. The key innovation is the use of compact user embeddings to condition the language model, allowing it to generate content that better matches the user's interests and preferences.
The empirical results demonstrate the effectiveness of this approach, showing significant performance improvements on various language-based tasks compared to using the base LLM or other personalization techniques. While the paper identifies some potential limitations, the User-LLM method represents an important step forward in making large language models more personalized and user-friendly.
The findings in this paper have important implications for the development of more personalized and engaging AI systems, with applications across a wide range of domains, from recommendation systems to conversational assistants. As large language models continue to advance, techniques like User-LLM will be crucial for unlocking their full potential and ensuring they can be effectively tailored to individual users' needs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
User-LLM: Efficient LLM Contextualization with User Embeddings
Lin Ning, Luyang Liu, Jiaxing Wu, Neo Wu, Devora Berlowitz, Sushant Prakash, Bradley Green, Shawn O'Banion, Jun Xie
Large language models (LLMs) have achieved remarkable success across various domains, but effectively incorporating complex and potentially noisy user timeline data into LLMs remains a challenge. Current approaches often involve translating user timelines into text descriptions before feeding them to LLMs, which can be inefficient and may not fully capture the nuances of user behavior. Inspired by how LLMs are effectively integrated with images through direct embeddings, we propose User-LLM, a novel framework that leverages user embeddings to directly contextualize LLMs with user history interactions. These embeddings, generated by a user encoder pretrained using self-supervised learning on diverse user interactions, capture latent user behaviors and interests as well as their evolution over time. We integrate these user embeddings with LLMs through cross-attention, enabling LLMs to dynamically adapt their responses based on the context of a user's past actions and preferences. Our approach achieves significant efficiency gains by representing user timelines directly as embeddings, leading to substantial inference speedups of up to 78.1X. Comprehensive experiments on MovieLens, Amazon Review, and Google Local Review datasets demonstrate that User-LLM outperforms text-prompt-based contextualization on tasks requiring deep user understanding, with improvements of up to 16.33%, particularly excelling on long sequences that capture subtle shifts in user behavior. Furthermore, the incorporation of Perceiver layers streamlines the integration between user encoders and LLMs, yielding additional computational savings.
Read more9/11/2024
🚀
0
Enhancing Embedding Performance through Large Language Model-based Text Enrichment and Rewriting
Nicholas Harris, Anand Butani, Syed Hashmy
Embedding models are crucial for various natural language processing tasks but can be limited by factors such as limited vocabulary, lack of context, and grammatical errors. This paper proposes a novel approach to improve embedding performance by leveraging large language models (LLMs) to enrich and rewrite input text before the embedding process. By utilizing ChatGPT 3.5 to provide additional context, correct inaccuracies, and incorporate metadata, the proposed method aims to enhance the utility and accuracy of embedding models. The effectiveness of this approach is evaluated on three datasets: Banking77Classification, TwitterSemEval 2015, and Amazon Counter-factual Classification. Results demonstrate significant improvements over the baseline model on the TwitterSemEval 2015 dataset, with the best-performing prompt achieving a score of 85.34 compared to the previous best of 81.52 on the Massive Text Embedding Benchmark (MTEB) Leaderboard. However, performance on the other two datasets was less impressive, highlighting the importance of considering domain-specific characteristics. The findings suggest that LLM-based text enrichment has shown promising results to improve embedding performance, particularly in certain domains. Hence, numerous limitations in the process of embedding can be avoided.
Read more4/19/2024
0
Large Language Models as Conversational Movie Recommenders: A User Study
Ruixuan Sun, Xinyi Li, Avinash Akella, Joseph A. Konstan
This paper explores the effectiveness of using large language models (LLMs) for personalized movie recommendations from users' perspectives in an online field experiment. Our study involves a combination of between-subject prompt and historic consumption assessments, along with within-subject recommendation scenario evaluations. By examining conversation and survey response data from 160 active users, we find that LLMs offer strong recommendation explainability but lack overall personalization, diversity, and user trust. Our results also indicate that different personalized prompting techniques do not significantly affect user-perceived recommendation quality, but the number of movies a user has watched plays a more significant role. Furthermore, LLMs show a greater ability to recommend lesser-known or niche movies. Through qualitative analysis, we identify key conversational patterns linked to positive and negative user interaction experiences and conclude that providing personal context and examples is crucial for obtaining high-quality recommendations from LLMs.
Read more5/1/2024

0
LLMEmbed: Rethinking Lightweight LLM's Genuine Function in Text Classification
Chun Liu, Hongguang Zhang, Kainan Zhao, Xinghai Ju, Lin Yang
With the booming of Large Language Models (LLMs), prompt-learning has become a promising method mainly researched in various research areas. Recently, many attempts based on prompt-learning have been made to improve the performance of text classification. However, most of these methods are based on heuristic Chain-of-Thought (CoT), and tend to be more complex but less efficient. In this paper, we rethink the LLM-based text classification methodology, propose a simple and effective transfer learning strategy, namely LLMEmbed, to address this classical but challenging task. To illustrate, we first study how to properly extract and fuse the text embeddings via various lightweight LLMs at different network depths to improve their robustness and discrimination, then adapt such embeddings to train the classifier. We perform extensive experiments on publicly available datasets, and the results show that LLMEmbed achieves strong performance while enjoys low training overhead using lightweight LLM backbones compared to recent methods based on larger LLMs, i.e. GPT-3, and sophisticated prompt-based strategies. Our LLMEmbed achieves adequate accuracy on publicly available benchmarks without any fine-tuning while merely use 4% model parameters, 1.8% electricity consumption and 1.5% runtime compared to its counterparts. Code is available at: https://github.com/ChunLiu-cs/LLMEmbed-ACL2024.
Read more6/7/2024