User-in-the-loop Evaluation of Multimodal LLMs for Activity Assistance

0
Sign in to get full access
Overview
- Researchers evaluate how well multimodal large language models (LLMs) can assist users with activity-based tasks
- They use a "user-in-the-loop" approach, where users provide feedback to iteratively improve the models
- The study explores the strengths and limitations of multimodal LLMs for activity assistance through user experiments
Plain English Explanation
The paper explores how well large language models that can process both text and images (called "multimodal" models) can help users with tasks related to everyday activities. The researchers used an approach where the users provide feedback to the models, allowing the models to be improved over time.
The key idea is to see how effective these powerful AI models can be at understanding the context and requirements of activity-based tasks, and then providing useful assistance to the users. By incorporating user feedback, the researchers aim to identify the strengths and weaknesses of these multimodal models for this type of real-world application.
Technical Explanation
The paper presents a "user-in-the-loop" evaluation of multimodal large language models (LLMs) for activity assistance tasks. The researchers designed an interactive experiment where users worked with the models to complete various activity-related prompts, such as planning a meal or organizing a workspace.
The users provided feedback on the quality and usefulness of the model's responses, and this feedback was then used to fine-tune and improve the models. This iterative process allowed the researchers to deeply explore the capabilities and limitations of the multimodal LLMs in a real-world, user-centric setting.
The key technical aspects of the study include the experiment design, the specific multimodal LLM architectures evaluated, and the analysis of how user feedback impacted model performance over time. The researchers also examine the types of activity tasks that were better or worse suited for these multimodal AI assistants.
Critical Analysis
The paper provides a thoughtful and nuanced exploration of the potential for multimodal LLMs to assist users with activity-based tasks. By incorporating user feedback, the researchers were able to uncover important insights about the strengths and limitations of these models in a real-world context.
One potential limitation is the relatively small scale of the user study, which may limit the generalizability of the findings. Additionally, the paper does not delve deeply into the specific technical details of the model architectures or training procedures, which could make it challenging for readers to fully understand the underlying mechanisms.
That said, the user-centric approach and the focus on activity assistance are valuable contributions to the growing body of research on multimodal AI systems. The findings could help guide the development of more effective and user-friendly activity assistance tools powered by advanced language models.
Conclusion
This paper presents a novel user-in-the-loop evaluation of multimodal large language models for activity assistance tasks. The researchers found that these models can be quite effective at understanding context and providing useful guidance, but also highlighted areas where they still struggle, such as with complex, multi-step activities.
By incorporating user feedback, the study offers important insights into how these powerful AI systems can be further refined and improved to better support users in their everyday tasks and routines. As multimodal LLMs continue to evolve, this type of user-centric research will be crucial for ensuring that the technology delivers on its promise of enhancing human capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
User-in-the-loop Evaluation of Multimodal LLMs for Activity Assistance
Mrinal Verghese, Brian Chen, Hamid Eghbalzadeh, Tushar Nagarajan, Ruta Desai
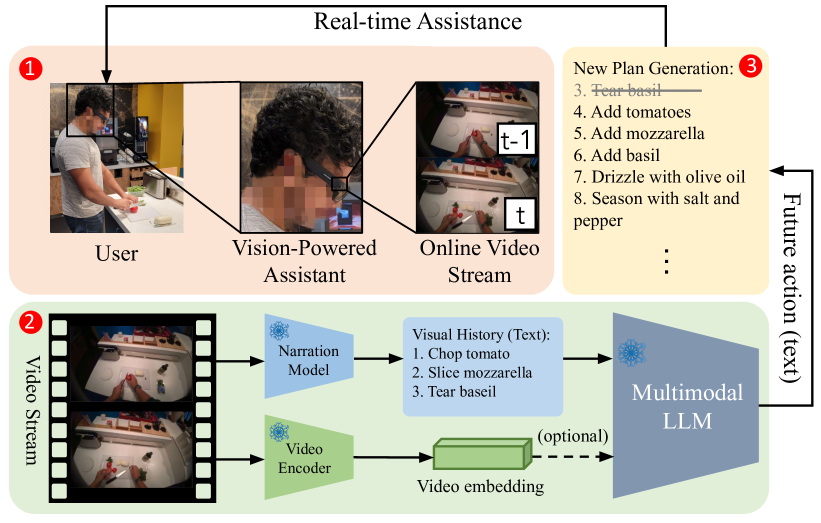
Our research investigates the capability of modern multimodal reasoning models, powered by Large Language Models (LLMs), to facilitate vision-powered assistants for multi-step daily activities. Such assistants must be able to 1) encode relevant visual history from the assistant's sensors, e.g., camera, 2) forecast future actions for accomplishing the activity, and 3) replan based on the user in the loop. To evaluate the first two capabilities, grounding visual history and forecasting in short and long horizons, we conduct benchmarking of two prominent classes of multimodal LLM approaches -- Socratic Models and Vision Conditioned Language Models (VCLMs) on video-based action anticipation tasks using offline datasets. These offline benchmarks, however, do not allow us to close the loop with the user, which is essential to evaluate the replanning capabilities and measure successful activity completion in assistive scenarios. To that end, we conduct a first-of-its-kind user study, with 18 participants performing 3 different multi-step cooking activities while wearing an egocentric observation device called Aria and following assistance from multimodal LLMs. We find that the Socratic approach outperforms VCLMs in both offline and online settings. We further highlight how grounding long visual history, common in activity assistance, remains challenging in current models, especially for VCLMs, and demonstrate that offline metrics do not indicate online performance.
Read more8/14/2024

0
Temporal Grounding of Activities using Multimodal Large Language Models
Young Chol Song
Temporal grounding of activities, the identification of specific time intervals of actions within a larger event context, is a critical task in video understanding. Recent advancements in multimodal large language models (LLMs) offer new opportunities for enhancing temporal reasoning capabilities. In this paper, we evaluate the effectiveness of combining image-based and text-based large language models (LLMs) in a two-stage approach for temporal activity localization. We demonstrate that our method outperforms existing video-based LLMs. Furthermore, we explore the impact of instruction-tuning on a smaller multimodal LLM, showing that refining its ability to process action queries leads to more expressive and informative outputs, thereby enhancing its performance in identifying specific time intervals of activities. Our experimental results on the Charades-STA dataset highlight the potential of this approach in advancing the field of temporal activity localization and video understanding.
Read more7/9/2024
📈
0
Emerging Practices for Large Multimodal Model (LMM) Assistance for People with Visual Impairments: Implications for Design
Jingyi Xie, Rui Yu, He Zhang, Sooyeon Lee, Syed Masum Billah, John M. Carroll
People with visual impairments perceive their environment non-visually and often use AI-powered assistive tools to obtain textual descriptions of visual information. Recent large vision-language model-based AI-powered tools like Be My AI are more capable of understanding users' inquiries in natural language and describing the scene in audible text; however, the extent to which these tools are useful to visually impaired users is currently understudied. This paper aims to fill this gap. Our study with 14 visually impaired users reveals that they are adapting these tools organically -- not only can these tools facilitate complex interactions in household, spatial, and social contexts, but they also act as an extension of users' cognition, as if the cognition were distributed in the visual information. We also found that although the tools are currently not goal-oriented, users accommodate this limitation and embrace the tools' capabilities for broader use. These findings enable us to envision design implications for creating more goal-oriented, real-time processing, and reliable AI-powered assistive technology.
Read more7/15/2024
0
A Survey on Evaluation of Multimodal Large Language Models
Jiaxing Huang, Jingyi Zhang
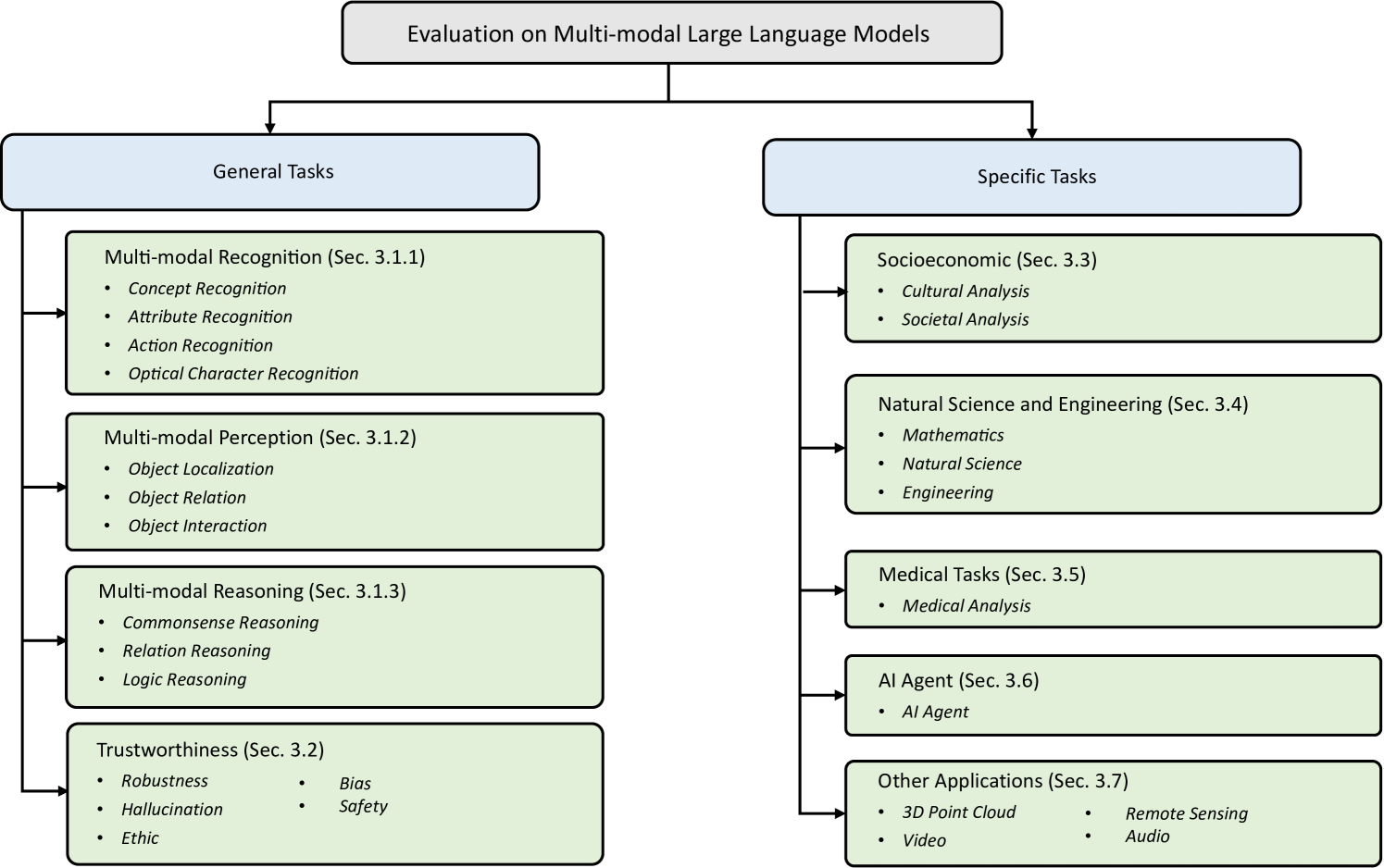
Multimodal Large Language Models (MLLMs) mimic human perception and reasoning system by integrating powerful Large Language Models (LLMs) with various modality encoders (e.g., vision, audio), positioning LLMs as the brain and various modality encoders as sensory organs. This framework endows MLLMs with human-like capabilities, and suggests a potential pathway towards achieving artificial general intelligence (AGI). With the emergence of all-round MLLMs like GPT-4V and Gemini, a multitude of evaluation methods have been developed to assess their capabilities across different dimensions. This paper presents a systematic and comprehensive review of MLLM evaluation methods, covering the following key aspects: (1) the background of MLLMs and their evaluation; (2) what to evaluate that reviews and categorizes existing MLLM evaluation tasks based on the capabilities assessed, including general multimodal recognition, perception, reasoning and trustworthiness, and domain-specific applications such as socioeconomic, natural sciences and engineering, medical usage, AI agent, remote sensing, video and audio processing, 3D point cloud analysis, and others; (3) where to evaluate that summarizes MLLM evaluation benchmarks into general and specific benchmarks; (4) how to evaluate that reviews and illustrates MLLM evaluation steps and metrics; Our overarching goal is to provide valuable insights for researchers in the field of MLLM evaluation, thereby facilitating the development of more capable and reliable MLLMs. We emphasize that evaluation should be regarded as a critical discipline, essential for advancing the field of MLLMs.
Read more8/29/2024