Temporal Grounding of Activities using Multimodal Large Language Models

0

Sign in to get full access
Overview
- This paper explores the use of multimodal large language models (LLMs) for temporally grounding activities in video.
- The researchers developed a model that can understand the temporal context of actions and events in videos by leveraging both visual and textual information.
- The model was trained on a large dataset of videos and captions, allowing it to learn patterns and associations between visual cues and temporal descriptions.
- The researchers evaluated the model on several benchmark tasks, demonstrating its effectiveness in accurately pinpointing when activities occur in video.
Plain English Explanation
The researchers in this paper set out to create a system that can understand the timing of different actions and events shown in videos. To do this, they used a type of artificial intelligence called a "multimodal large language model" (or multimodal LLM for short).
Multimodal LLMs are AI systems that can process and understand information from multiple sources, like text and images. In this case, the researchers trained their model on a huge dataset of videos and the captions that describe what's happening in them. This allowed the model to learn patterns and associations between the visual cues in the videos and the language used to describe when different actions occur.
For example, the model might learn that when it sees someone stirring a pot, the caption is likely to mention words like "then" or "next" to describe the temporal sequence of events. By recognizing these connections between the visual and textual information, the model can then take a new video and accurately pinpoint when specific activities are taking place.
This kind of technology could be really useful for all sorts of applications, like video summarization, video question answering, or activity recognition. It's an exciting step forward in helping machines really understand the rich temporal context of the world around us, just like humans do.
Technical Explanation
The researchers in this paper developed a multimodal LLM for the task of temporally grounding activities in video. They trained their model on a large dataset of video-caption pairs, where the captions describe the temporal sequence of events shown in the videos.
The model architecture consists of a visual encoder (e.g., a convolutional neural network) to process the video frames, and a text encoder (e.g., a transformer-based language model) to process the captions. These two encoders are then combined through cross-attention mechanisms to allow the model to learn associations between the visual and textual information.
During training, the model learns to predict the temporal offset (i.e., timestamp) of each activity mention in the caption, relative to the start of the video. This is done by having the model output a time offset for each word in the caption, which can then be used to infer when the corresponding activity occurs in the video.
The researchers evaluated their model on several benchmark datasets for temporal activity grounding, including VIOLIN and EPIC-Kitchens. Their results showed that the multimodal LLM outperformed previous state-of-the-art methods, demonstrating the effectiveness of this approach for temporally grounding activities in video.
Critical Analysis
The researchers acknowledge several limitations and areas for future work in their paper. One notable limitation is that the model was trained and evaluated on relatively short, well-curated videos, which may not reflect the complexity and diversity of real-world video data. Additionally, the model was trained on English-language captions, so its performance may not generalize as well to other languages or cultural contexts.
Further research could explore techniques to improve the model's robustness and generalization, such as using more diverse training data, incorporating additional modalities (e.g., audio), or developing better cross-modal alignment methods. There is also an opportunity to investigate how these models might be applied in practical applications, such as video summarization or video-based instruction systems.
Overall, this research represents a promising step forward in the field of multimodal understanding, demonstrating the potential for LLMs to provide rich temporal grounding of activities in video. As the field continues to evolve, it will be important to carefully consider the limitations and potential societal impacts of these technologies.
Conclusion
This paper presents a novel approach to temporally grounding activities in video using multimodal large language models. By leveraging both visual and textual information, the researchers developed a model that can accurately pinpoint when different actions and events occur in a video, outperforming previous state-of-the-art methods.
The implications of this work are far-reaching, as this kind of technology could enable a wide range of applications, from video summarization to video question answering to activity recognition. As the field of multimodal understanding continues to evolve, research like this will be crucial for advancing our ability to build AI systems that can truly comprehend the rich temporal context of the world around us.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Temporal Grounding of Activities using Multimodal Large Language Models
Young Chol Song
Temporal grounding of activities, the identification of specific time intervals of actions within a larger event context, is a critical task in video understanding. Recent advancements in multimodal large language models (LLMs) offer new opportunities for enhancing temporal reasoning capabilities. In this paper, we evaluate the effectiveness of combining image-based and text-based large language models (LLMs) in a two-stage approach for temporal activity localization. We demonstrate that our method outperforms existing video-based LLMs. Furthermore, we explore the impact of instruction-tuning on a smaller multimodal LLM, showing that refining its ability to process action queries leads to more expressive and informative outputs, thereby enhancing its performance in identifying specific time intervals of activities. Our experimental results on the Charades-STA dataset highlight the potential of this approach in advancing the field of temporal activity localization and video understanding.
Read more7/9/2024

0
Training-free Video Temporal Grounding using Large-scale Pre-trained Models
Minghang Zheng, Xinhao Cai, Qingchao Chen, Yuxin Peng, Yang Liu
Video temporal grounding aims to identify video segments within untrimmed videos that are most relevant to a given natural language query. Existing video temporal localization models rely on specific datasets for training and have high data collection costs, but they exhibit poor generalization capability under the across-dataset and out-of-distribution (OOD) settings. In this paper, we propose a Training-Free Video Temporal Grounding (TFVTG) approach that leverages the ability of pre-trained large models. A naive baseline is to enumerate proposals in the video and use the pre-trained visual language models (VLMs) to select the best proposal according to the vision-language alignment. However, most existing VLMs are trained on image-text pairs or trimmed video clip-text pairs, making it struggle to (1) grasp the relationship and distinguish the temporal boundaries of multiple events within the same video; (2) comprehend and be sensitive to the dynamic transition of events (the transition from one event to another) in the video. To address these issues, we propose leveraging large language models (LLMs) to analyze multiple sub-events contained in the query text and analyze the temporal order and relationships between these events. Secondly, we split a sub-event into dynamic transition and static status parts and propose the dynamic and static scoring functions using VLMs to better evaluate the relevance between the event and the description. Finally, for each sub-event description, we use VLMs to locate the top-k proposals and leverage the order and relationships between sub-events provided by LLMs to filter and integrate these proposals. Our method achieves the best performance on zero-shot video temporal grounding on Charades-STA and ActivityNet Captions datasets without any training and demonstrates better generalization capabilities in cross-dataset and OOD settings.
Read more8/30/2024
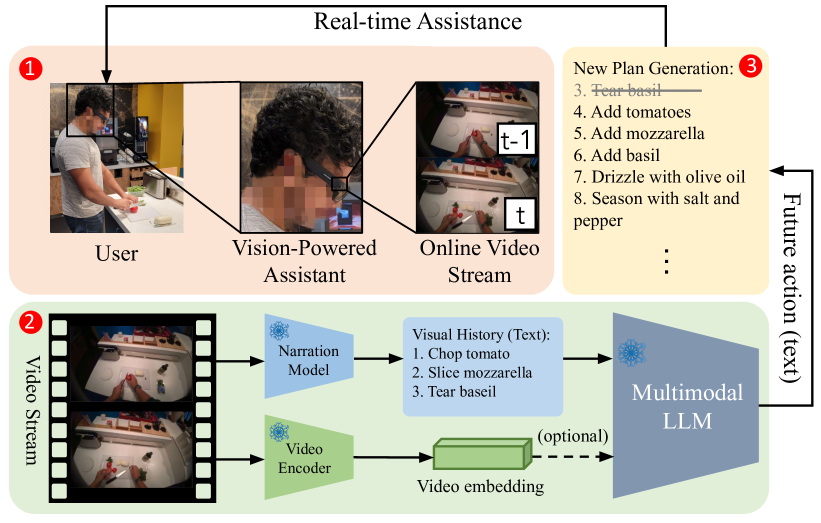
0
User-in-the-loop Evaluation of Multimodal LLMs for Activity Assistance
Mrinal Verghese, Brian Chen, Hamid Eghbalzadeh, Tushar Nagarajan, Ruta Desai
Our research investigates the capability of modern multimodal reasoning models, powered by Large Language Models (LLMs), to facilitate vision-powered assistants for multi-step daily activities. Such assistants must be able to 1) encode relevant visual history from the assistant's sensors, e.g., camera, 2) forecast future actions for accomplishing the activity, and 3) replan based on the user in the loop. To evaluate the first two capabilities, grounding visual history and forecasting in short and long horizons, we conduct benchmarking of two prominent classes of multimodal LLM approaches -- Socratic Models and Vision Conditioned Language Models (VCLMs) on video-based action anticipation tasks using offline datasets. These offline benchmarks, however, do not allow us to close the loop with the user, which is essential to evaluate the replanning capabilities and measure successful activity completion in assistive scenarios. To that end, we conduct a first-of-its-kind user study, with 18 participants performing 3 different multi-step cooking activities while wearing an egocentric observation device called Aria and following assistance from multimodal LLMs. We find that the Socratic approach outperforms VCLMs in both offline and online settings. We further highlight how grounding long visual history, common in activity assistance, remains challenging in current models, especially for VCLMs, and demonstrate that offline metrics do not indicate online performance.
Read more8/14/2024

0
Open-vocabulary Temporal Action Localization using VLMs
Naoki Wake, Atsushi Kanehira, Kazuhiro Sasabuchi, Jun Takamatsu, Katsushi Ikeuchi
Video action localization aims to find timings of a specific action from a long video. Although existing learning-based approaches have been successful, those require annotating videos that come with a considerable labor cost. This paper proposes a learning-free, open-vocabulary approach based on emerging off-the-shelf vision-language models (VLM). The challenge stems from the fact that VLMs are neither designed to process long videos nor tailored for finding actions. We overcome these problems by extending an iterative visual prompting technique. Specifically, we sample video frames into a concatenated image with frame index labels, making a VLM guess a frame that is considered to be closest to the start/end of the action. Iterating this process by narrowing a sampling time window results in finding a specific frame of start and end of an action. We demonstrate that this sampling technique yields reasonable results, illustrating a practical extension of VLMs for understanding videos. A sample code is available at https://microsoft.github.io/VLM-Video-Action-Localization/.
Read more9/10/2024