Counterfactual Explanations for Face Forgery Detection via Adversarial Removal of Artifacts
2404.08341
0
0
Abstract
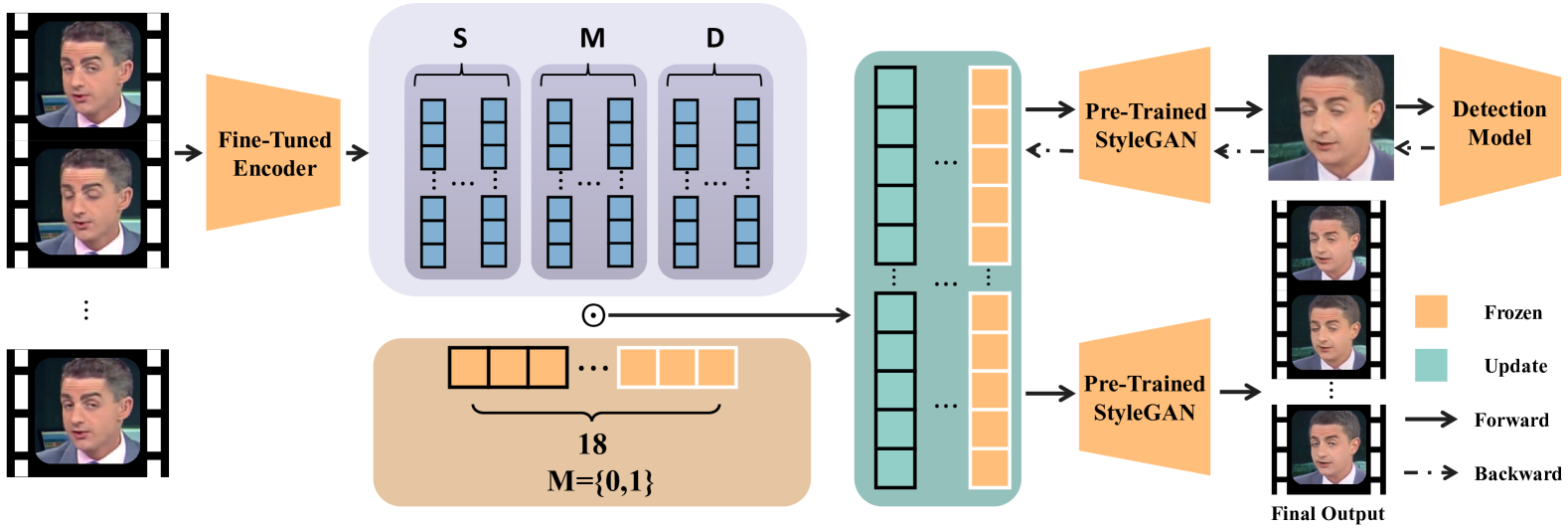
Highly realistic AI generated face forgeries known as deepfakes have raised serious social concerns. Although DNN-based face forgery detection models have achieved good performance, they are vulnerable to latest generative methods that have less forgery traces and adversarial attacks. This limitation of generalization and robustness hinders the credibility of detection results and requires more explanations. In this work, we provide counterfactual explanations for face forgery detection from an artifact removal perspective. Specifically, we first invert the forgery images into the StyleGAN latent space, and then adversarially optimize their latent representations with the discrimination supervision from the target detection model. We verify the effectiveness of the proposed explanations from two aspects: (1) Counterfactual Trace Visualization: the enhanced forgery images are useful to reveal artifacts by visually contrasting the original images and two different visualization methods; (2) Transferable Adversarial Attacks: the adversarial forgery images generated by attacking the detection model are able to mislead other detection models, implying the removed artifacts are general. Extensive experiments demonstrate that our method achieves over 90% attack success rate and superior attack transferability. Compared with naive adversarial noise methods, our method adopts both generative and discriminative model priors, and optimize the latent representations in a synthesis-by-analysis way, which forces the search of counterfactual explanations on the natural face manifold. Thus, more general counterfactual traces can be found and better adversarial attack transferability can be achieved.
Create account to get full access
Overview
- This paper proposes a method for explaining the decisions of face forgery detection models using counterfactual explanations.
- Counterfactual explanations show how the model's decision would change if certain features of the input were different, providing more interpretable insights.
- The authors use an adversarial approach to remove artifacts from face images that the detection model relies on, generating counterfactual examples.
- Experiments on multiple face forgery datasets demonstrate the effectiveness of this approach in generating plausible counterfactual explanations.
Plain English Explanation
The paper focuses on developing a way to better understand how face forgery detection models work. These models are used to identify when a face image has been digitally manipulated or "forged." However, it can be difficult to understand exactly what features or artifacts in the image the model is using to make its decision.
The authors propose using counterfactual explanations to provide more interpretable insights. Counterfactual explanations show how the model's decision would change if certain aspects of the input were different.
In this case, the authors use an adversarial approach to remove the specific artifacts that the detection model is relying on to identify a face as forged. By removing these artifacts, they can generate counterfactual examples that the model would then classify as real, even though the original image was forged.
This allows the researchers to better understand what types of visual cues the model is using to detect face forgeries. They demonstrate this approach on multiple face forgery datasets, showing that it can generate plausible counterfactual explanations.
Technical Explanation
The key aspects of the paper's technical approach are:
-
Counterfactual Explanation Generation: The authors use an adversarial approach to generate counterfactual examples that would change the face forgery detection model's decision. They train a generative adversarial network (GAN) to remove the artifacts in the input image that the detection model relies on.
-
Iterative Artifact Removal: The artifact removal process is performed iteratively, gradually reducing the magnitude of the perturbations applied to the input image. This ensures the generated counterfactual examples remain visually plausible.
-
Evaluation on Multiple Datasets: The authors evaluate their approach on three different face forgery datasets: DFDC, FF++, and DD3. They demonstrate that the generated counterfactual explanations are effective across these diverse datasets.
Critical Analysis
The paper presents a novel approach for generating counterfactual explanations for face forgery detection models. However, there are a few potential limitations and areas for further research:
-
Generalization to Other Modalities: The proposed method is focused on visual face forgery detection. It would be interesting to explore whether this approach could be extended to other types of media forgery detection, such as audio or video.
-
Robustness to Diverse Forgery Techniques: The authors test their approach on several existing face forgery datasets, but it's unclear how well it would perform against more advanced or novel forgery techniques that may emerge in the future.
-
Human Evaluation of Counterfactuals: While the authors demonstrate the effectiveness of their approach quantitatively, it would be valuable to also assess the plausibility and interpretability of the generated counterfactual examples through human evaluation.
-
Computational Efficiency: The iterative artifact removal process may be computationally intensive, which could limit the practical deployment of this approach. Optimizing the efficiency of the counterfactual generation process could be an area for future research.
Conclusion
This paper presents an innovative approach for generating counterfactual explanations to better understand face forgery detection models. By using an adversarial method to remove the artifacts that the models rely on, the authors are able to generate plausible counterfactual examples that provide more interpretable insights into the model's decision-making process.
The ability to explain the reasoning behind these detection models is crucial as they become more widely deployed, as it can help build trust and transparency. The authors' work represents an important step in this direction, and future research could explore extending the approach to other media forgery detection tasks and improving its computational efficiency.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Utilizing Adversarial Examples for Bias Mitigation and Accuracy Enhancement
Pushkar Shukla, Dhruv Srikanth, Lee Cohen, Matthew Turk
0
0
We propose a novel approach to mitigate biases in computer vision models by utilizing counterfactual generation and fine-tuning. While counterfactuals have been used to analyze and address biases in DNN models, the counterfactuals themselves are often generated from biased generative models, which can introduce additional biases or spurious correlations. To address this issue, we propose using adversarial images, that is images that deceive a deep neural network but not humans, as counterfactuals for fair model training. Our approach leverages a curriculum learning framework combined with a fine-grained adversarial loss to fine-tune the model using adversarial examples. By incorporating adversarial images into the training data, we aim to prevent biases from propagating through the pipeline. We validate our approach through both qualitative and quantitative assessments, demonstrating improved bias mitigation and accuracy compared to existing methods. Qualitatively, our results indicate that post-training, the decisions made by the model are less dependent on the sensitive attribute and our model better disentangles the relationship between sensitive attributes and classification variables.
4/19/2024
🔎
LatentForensics: Towards frugal deepfake detection in the StyleGAN latent space
Matthieu Delmas, Amine Kacete, Stephane Paquelet, Simon Leglaive, Renaud Seguier
0
0
The classification of forged videos has been a challenge for the past few years. Deepfake classifiers can now reliably predict whether or not video frames have been tampered with. However, their performance is tied to both the dataset used for training and the analyst's computational power. We propose a deepfake detection method that operates in the latent space of a state-of-the-art generative adversarial network (GAN) trained on high-quality face images. The proposed method leverages the structure of the latent space of StyleGAN to learn a lightweight binary classification model. Experimental results on standard datasets reveal that the proposed approach outperforms other state-of-the-art deepfake classification methods, especially in contexts where the data available to train the models is rare, such as when a new manipulation method is introduced. To the best of our knowledge, this is the first study showing the interest of the latent space of StyleGAN for deepfake classification. Combined with other recent studies on the interpretation and manipulation of this latent space, we believe that the proposed approach can further help in developing frugal deepfake classification methods based on interpretable high-level properties of face images.
5/7/2024

Deep Image Composition Meets Image Forgery
Eren Tahir, Mert Bal
0
0
Image forgery is a topic that has been studied for many years. Before the breakthrough of deep learning, forged images were detected using handcrafted features that did not require training. These traditional methods failed to perform satisfactorily even on datasets much worse in quality than real-life image manipulations. Advances in deep learning have impacted image forgery detection as much as they have impacted other areas of computer vision and have improved the state of the art. Deep learning models require large amounts of labeled data for training. In the case of image forgery, labeled data at the pixel level is a very important factor for the models to learn. None of the existing datasets have sufficient size, realism and pixel-level labeling at the same time. This is due to the high cost of producing and labeling quality images. It can take hours for an image editing expert to manipulate just one image. To bridge this gap, we automate data generation using image composition techniques that are very related to image forgery. Unlike other automated data generation frameworks, we use state of the art image composition deep learning models to generate spliced images close to the quality of real-life manipulations. Finally, we test the generated dataset on the SOTA image manipulation detection model and show that its prediction performance is lower compared to existing datasets, i.e. we produce realistic images that are more difficult to detect. Dataset will be available at https://github.com/99eren99/DIS25k .
4/29/2024

DeCoDEx: Confounder Detector Guidance for Improved Diffusion-based Counterfactual Explanations
Nima Fathi, Amar Kumar, Brennan Nichyporuk, Mohammad Havaei, Tal Arbel
0
0
Deep learning classifiers are prone to latching onto dominant confounders present in a dataset rather than on the causal markers associated with the target class, leading to poor generalization and biased predictions. Although explainability via counterfactual image generation has been successful at exposing the problem, bias mitigation strategies that permit accurate explainability in the presence of dominant and diverse artifacts remain unsolved. In this work, we propose the DeCoDEx framework and show how an external, pre-trained binary artifact detector can be leveraged during inference to guide a diffusion-based counterfactual image generator towards accurate explainability. Experiments on the CheXpert dataset, using both synthetic artifacts and real visual artifacts (support devices), show that the proposed method successfully synthesizes the counterfactual images that change the causal pathology markers associated with Pleural Effusion while preserving or ignoring the visual artifacts. Augmentation of ERM and Group-DRO classifiers with the DeCoDEx generated images substantially improves the results across underrepresented groups that are out of distribution for each class. The code is made publicly available at https://github.com/NimaFathi/DeCoDEx.
5/16/2024