Utilizing TTS Synthesized Data for Efficient Development of Keyword Spotting Model

0

Sign in to get full access
Overview
- The paper explores using text-to-speech (TTS) synthesized data to efficiently develop a keyword spotting model.
- Keyword spotting is the task of detecting predefined keywords in audio streams.
- The researchers investigate whether TTS-generated data can effectively supplement or replace real speech data for training keyword spotting models.
Plain English Explanation
The paper examines using computer-generated speech, created through text-to-speech (TTS) technology, to train a model that can identify specific words or "keywords" in audio recordings. Keyword spotting is an important task in areas like voice assistants, where the system needs to detect when the user says a particular command word.
Traditionally, keyword spotting models are trained on large datasets of real human speech. However, collecting and annotating high-quality speech data can be time-consuming and expensive. The researchers explore whether synthetic speech generated by TTS systems can be used instead, which could make the model development process more efficient.
They investigate whether TTS-synthesized data can effectively supplement or even fully replace real speech data for training keyword spotting models. The goal is to determine if these computer-generated audio samples can teach the model to accurately detect the target keywords, without needing as much real-world speech data.
Technical Explanation
The paper evaluates the use of TTS-synthesized data for training keyword spotting models. The researchers conduct experiments on the Google Speech Commands dataset, which contains recordings of people saying 35 different keywords.
They train keyword spotting models using varying mixes of real speech data and TTS-generated audio samples. The TTS data is created using publicly available text-to-speech APIs. The models are based on a convolutional neural network architecture and are trained to classify whether a given audio clip contains one of the target keywords.
The results show that models trained on a combination of real and synthetic data can achieve comparable, or even slightly better, performance compared to models trained solely on real speech data. In some cases, the TTS-supplemented models outperformed the real-data-only models. The researchers also find that models trained exclusively on synthetic data can provide reasonable keyword spotting accuracy, though they underperform compared to real-data-based models.
These findings suggest that TTS-synthesized audio can be effectively used to supplement or even replace real speech data for developing keyword spotting models, potentially streamlining the model training process.
Critical Analysis
The paper provides a useful exploration of using TTS-generated data to improve the efficiency of keyword spotting model development. The results indicate that synthetic speech can be a viable complement or alternative to real speech data, which has important practical implications.
However, the study is limited to a single dataset and a specific neural network architecture. Additional research is needed to understand how these findings generalize to other datasets, model designs, and application domains. The paper also does not extensively discuss potential biases or limitations of the TTS systems used to generate the synthetic data.
Further work could investigate the impact of TTS quality, speaker diversity, and acoustic variation in the synthetic data. It would also be valuable to explore how TTS-supplemented models perform on real-world, noisy audio conditions compared to models trained solely on clean, high-quality speech.
Conclusion
This paper presents a promising approach for leveraging TTS-synthesized data to efficiently develop keyword spotting models. The results suggest that computer-generated speech can effectively complement or even substitute for real speech data during model training, potentially reducing the time and cost required to build accurate keyword spotting systems.
While further research is needed, this work highlights the potential of synthetic data to advance the field of speech recognition and enable more accessible and scalable development of voice-based applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Utilizing TTS Synthesized Data for Efficient Development of Keyword Spotting Model
Hyun Jin Park, Dhruuv Agarwal, Neng Chen, Rentao Sun, Kurt Partridge, Justin Chen, Harry Zhang, Pai Zhu, Jacob Bartel, Kyle Kastner, Gary Wang, Andrew Rosenberg, Quan Wang
This paper explores the use of TTS synthesized training data for KWS (keyword spotting) task while minimizing development cost and time. Keyword spotting models require a huge amount of training data to be accurate, and obtaining such training data can be costly. In the current state of the art, TTS models can generate large amounts of natural-sounding data, which can help reducing cost and time for KWS model development. Still, TTS generated data can be lacking diversity compared to real data. To pursue maximizing KWS model accuracy under the constraint of limited resources and current TTS capability, we explored various strategies to mix TTS data and real human speech data, with a focus on minimizing real data use and maximizing diversity of TTS output. Our experimental results indicate that relatively small amounts of real audio data with speaker diversity (100 speakers, 2k utterances) and large amounts of TTS synthesized data can achieve reasonably high accuracy (within 3x error rate of baseline), compared to the baseline (trained with 3.8M real positive utterances).
Read more7/29/2024

0
Synth4Kws: Synthesized Speech for User Defined Keyword Spotting in Low Resource Environments
Pai Zhu, Dhruuv Agarwal, Jacob W. Bartel, Kurt Partridge, Hyun Jin Park, Quan Wang
One of the challenges in developing a high quality custom keyword spotting (KWS) model is the lengthy and expensive process of collecting training data covering a wide range of languages, phrases and speaking styles. We introduce Synth4Kws - a framework to leverage Text to Speech (TTS) synthesized data for custom KWS in different resource settings. With no real data, we found increasing TTS phrase diversity and utterance sampling monotonically improves model performance, as evaluated by EER and AUC metrics over 11k utterances of the speech command dataset. In low resource settings, with 50k real utterances as a baseline, we found using optimal amounts of TTS data can improve EER by 30.1% and AUC by 46.7%. Furthermore, we mix TTS data with varying amounts of real data and interpolate the real data needed to achieve various quality targets. Our experiments are based on English and single word utterances but the findings generalize to i18n languages and other keyword types.
Read more7/25/2024

0
Adversarial training of Keyword Spotting to Minimize TTS Data Overfitting
Hyun Jin Park, Dhruuv Agarwal, Neng Chen, Rentao Sun, Kurt Partridge, Justin Chen, Harry Zhang, Pai Zhu, Jacob Bartel, Kyle Kastner, Gary Wang, Andrew Rosenberg, Quan Wang
The keyword spotting (KWS) problem requires large amounts of real speech training data to achieve high accuracy across diverse populations. Utilizing large amounts of text-to-speech (TTS) synthesized data can reduce the cost and time associated with KWS development. However, TTS data may contain artifacts not present in real speech, which the KWS model can exploit (overfit), leading to degraded accuracy on real speech. To address this issue, we propose applying an adversarial training method to prevent the KWS model from learning TTS-specific features when trained on large amounts of TTS data. Experimental results demonstrate that KWS model accuracy on real speech data can be improved by up to 12% when adversarial loss is used in addition to the original KWS loss. Surprisingly, we also observed that the adversarial setup improves accuracy by up to 8%, even when trained solely on TTS and real negative speech data, without any real positive examples.
Read more8/21/2024
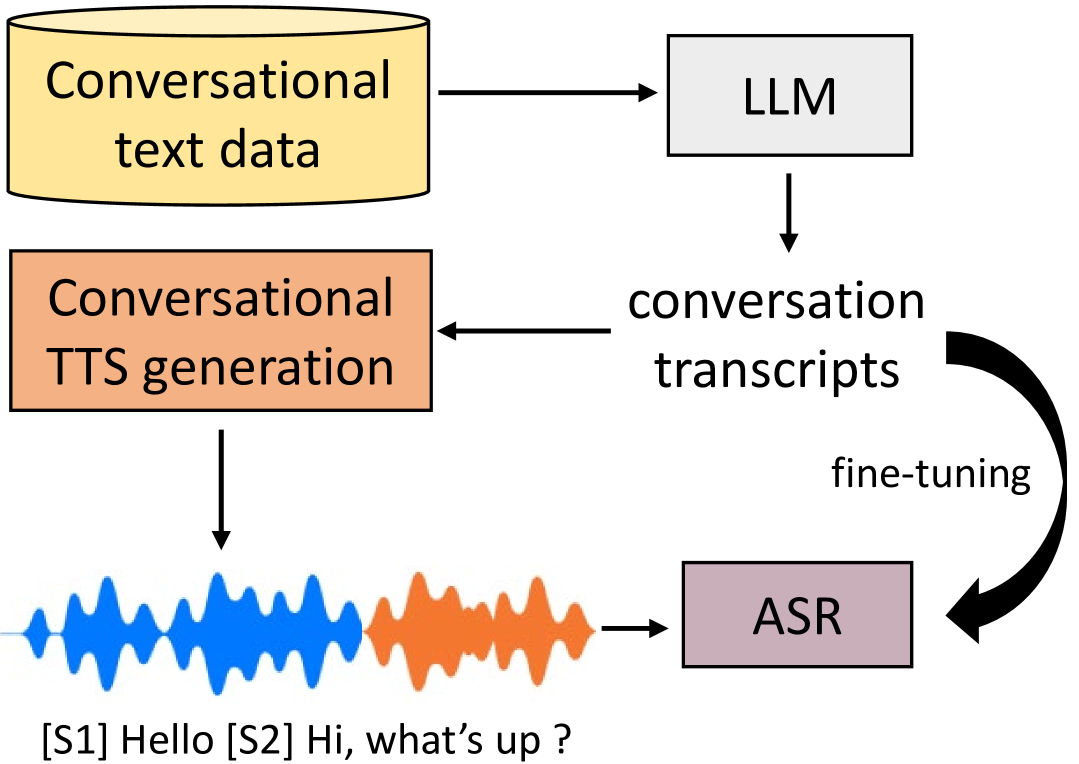
0
Generating Data with Text-to-Speech and Large-Language Models for Conversational Speech Recognition
Samuele Cornell, Jordan Darefsky, Zhiyao Duan, Shinji Watanabe
Currently, a common approach in many speech processing tasks is to leverage large scale pre-trained models by fine-tuning them on in-domain data for a particular application. Yet obtaining even a small amount of such data can be problematic, especially for sensitive domains and conversational speech scenarios, due to both privacy issues and annotation costs. To address this, synthetic data generation using single speaker datasets has been employed. Yet, for multi-speaker cases, such an approach often requires extensive manual effort and is prone to domain mismatches. In this work, we propose a synthetic data generation pipeline for multi-speaker conversational ASR, leveraging a large language model (LLM) for content creation and a conversational multi-speaker text-to-speech (TTS) model for speech synthesis. We conduct evaluation by fine-tuning the Whisper ASR model for telephone and distant conversational speech settings, using both in-domain data and generated synthetic data. Our results show that the proposed method is able to significantly outperform classical multi-speaker generation approaches that use external, non-conversational speech datasets.
Read more8/20/2024