V2X-VLM: End-to-End V2X Cooperative Autonomous Driving Through Large Vision-Language Models

0
Sign in to get full access
Overview
- The provided paper presents a new approach for enhancing end-to-end autonomous driving using large language models (LLMs).
- It explores how LLMs can be integrated with computer vision and other components to create a more robust and capable autonomous driving system.
- The key focus is on leveraging the powerful language understanding and generation capabilities of LLMs to improve various aspects of the autonomous driving pipeline.
Plain English Explanation
The paper discusses a novel method for improving self-driving cars by incorporating large language models (LLMs). LLMs are advanced AI systems that can understand and generate human-like text. The researchers propose integrating LLMs with the computer vision and other components of autonomous driving systems to create a more capable and reliable end-to-end solution.
The core idea is that LLMs can bring significant benefits to different stages of the autonomous driving process. For example, LLMs could help the car better understand the surrounding environment by interpreting visual information in the context of language. They could also assist with planning the vehicle's actions and generating natural language outputs to communicate with passengers or other road users.
By combining the strengths of LLMs with traditional autonomous driving technologies, the researchers aim to develop a more robust and adaptable self-driving system that can handle a wider range of real-world scenarios. This could ultimately lead to safer, more user-friendly, and more intelligent autonomous vehicles.
Technical Explanation
The paper proposes a new approach for enhancing end-to-end autonomous driving through the integration of large language models (LLMs). The key insight is that the powerful language understanding and generation capabilities of LLMs can be leveraged to improve various components of the autonomous driving pipeline.
The researchers explore how LLMs can be seamlessly integrated with the computer vision, planning, and control modules of an end-to-end autonomous driving system. For example, LLMs could be used to interpret visual information in the context of language, helping the car better understand its surroundings and make more informed decisions.
Additionally, the paper examines how LLMs can assist with generating natural language outputs, such as communicating with passengers or other road users. This could lead to more intuitive and user-friendly autonomous driving experiences.
The paper also discusses the potential challenges and limitations of this approach, as well as areas for future research. For instance, the researchers acknowledge the need to ensure the safety and reliability of the LLM-enhanced autonomous driving system, and the importance of addressing any biases or vulnerabilities that may arise from the integration of LLMs.
Critical Analysis
The paper presents a promising approach for enhancing end-to-end autonomous driving through the integration of large language models (LLMs). The key strength of this approach is the potential to leverage the powerful language understanding and generation capabilities of LLMs to improve various components of the autonomous driving pipeline.
However, the paper also acknowledges some potential limitations and areas for further research. For example, the researchers highlight the need to ensure the safety and reliability of the LLM-enhanced autonomous driving system, as well as the importance of addressing any biases or vulnerabilities that may arise from the integration of LLMs.
Additionally, while the paper provides a detailed technical explanation of the proposed approach, it may be helpful to see more empirical evidence or real-world case studies to fully assess the practical implications and effectiveness of this method.
Overall, this research represents an important step forward in the quest to develop more capable and user-friendly autonomous driving systems. However, continued exploration and careful consideration of the potential challenges and trade-offs will be crucial as the field of LLM-enhanced autonomous driving continues to evolve.
Conclusion
The paper presents a novel approach for enhancing end-to-end autonomous driving by integrating large language models (LLMs) with traditional autonomous driving technologies. The key idea is that the powerful language understanding and generation capabilities of LLMs can be leveraged to improve various aspects of the autonomous driving pipeline, such as interpreting visual information, generating natural language outputs, and planning the vehicle's actions.
By combining the strengths of LLMs with computer vision, planning, and control modules, the researchers aim to develop a more robust and adaptable autonomous driving system that can handle a wider range of real-world scenarios. This could lead to safer, more user-friendly, and more intelligent self-driving vehicles in the future.
While the paper highlights the potential benefits of this approach, it also acknowledges the need to address challenges related to safety, reliability, and potential biases. Continued research and experimentation will be necessary to fully realize the promise of LLM-enhanced autonomous driving and its implications for the future of transportation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
V2X-VLM: End-to-End V2X Cooperative Autonomous Driving Through Large Vision-Language Models
Junwei You, Haotian Shi, Zhuoyu Jiang, Zilin Huang, Rui Gan, Keshu Wu, Xi Cheng, Xiaopeng Li, Bin Ran
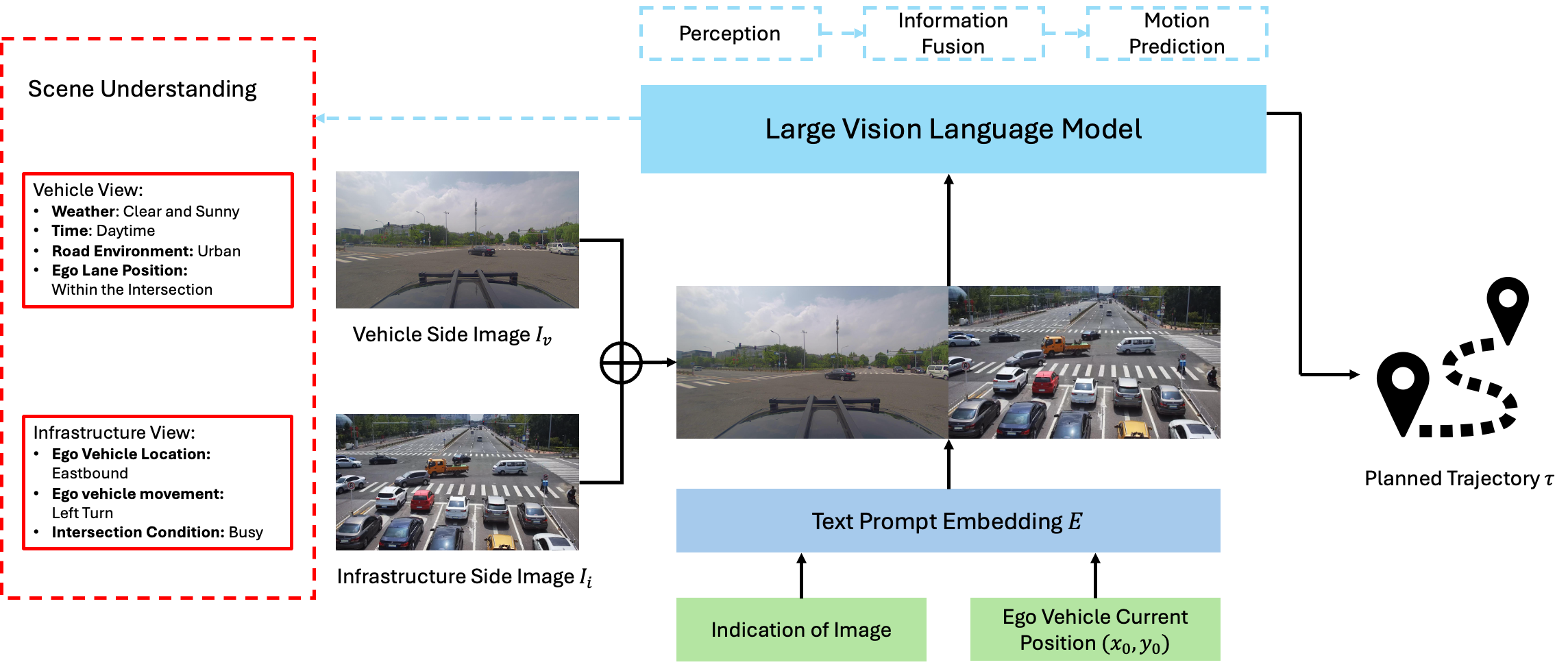
Advancements in autonomous driving have increasingly focused on end-to-end (E2E) systems that manage the full spectrum of driving tasks, from environmental perception to vehicle navigation and control. This paper introduces V2X-VLM, an innovative E2E vehicle-infrastructure cooperative autonomous driving (VICAD) framework with Vehicle-to-Everything (V2X) systems and large vision-language models (VLMs). V2X-VLM is designed to enhance situational awareness, decision-making, and ultimate trajectory planning by integrating multimodel data from vehicle-mounted cameras, infrastructure sensors, and textual information. The contrastive learning method is further employed to complement VLM by refining feature discrimination, assisting the model to learn robust representations of the driving environment. Evaluations on the DAIR-V2X dataset show that V2X-VLM outperforms state-of-the-art cooperative autonomous driving methods, while additional tests on corner cases validate its robustness in real-world driving conditions.
Read more9/17/2024
👁️
0
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
Xiaoyu Tian, Junru Gu, Bailin Li, Yicheng Liu, Yang Wang, Zhiyong Zhao, Kun Zhan, Peng Jia, Xianpeng Lang, Hang Zhao
A primary hurdle of autonomous driving in urban environments is understanding complex and long-tail scenarios, such as challenging road conditions and delicate human behaviors. We introduce DriveVLM, an autonomous driving system leveraging Vision-Language Models (VLMs) for enhanced scene understanding and planning capabilities. DriveVLM integrates a unique combination of reasoning modules for scene description, scene analysis, and hierarchical planning. Furthermore, recognizing the limitations of VLMs in spatial reasoning and heavy computational requirements, we propose DriveVLM-Dual, a hybrid system that synergizes the strengths of DriveVLM with the traditional autonomous driving pipeline. Experiments on both the nuScenes dataset and our SUP-AD dataset demonstrate the efficacy of DriveVLM and DriveVLM-Dual in handling complex and unpredictable driving conditions. Finally, we deploy the DriveVLM-Dual on a production vehicle, verifying it is effective in real-world autonomous driving environments.
Read more6/26/2024

0
Unified End-to-End V2X Cooperative Autonomous Driving
Zhiwei Li, Bozhen Zhang, Lei Yang, Tianyu Shen, Nuo Xu, Ruosen Hao, Weiting Li, Tao Yan, Huaping Liu
V2X cooperation, through the integration of sensor data from both vehicles and infrastructure, is considered a pivotal approach to advancing autonomous driving technology. Current research primarily focuses on enhancing perception accuracy, often overlooking the systematic improvement of accident prediction accuracy through end-to-end learning, leading to insufficient attention to the safety issues of autonomous driving. To address this challenge, this paper introduces the UniE2EV2X framework, a V2X-integrated end-to-end autonomous driving system that consolidates key driving modules within a unified network. The framework employs a deformable attention-based data fusion strategy, effectively facilitating cooperation between vehicles and infrastructure. The main advantages include: 1) significantly enhancing agents' perception and motion prediction capabilities, thereby improving the accuracy of accident predictions; 2) ensuring high reliability in the data fusion process; 3) superior end-to-end perception compared to modular approaches. Furthermore, We implement the UniE2EV2X framework on the challenging DeepAccident, a simulation dataset designed for V2X cooperative driving.
Read more5/8/2024
📈
0
SimpleLLM4AD: An End-to-End Vision-Language Model with Graph Visual Question Answering for Autonomous Driving
Peiru Zheng, Yun Zhao, Zhan Gong, Hong Zhu, Shaohua Wu
Many fields could benefit from the rapid development of the large language models (LLMs). The end-to-end autonomous driving (e2eAD) is one of the typically fields facing new opportunities as the LLMs have supported more and more modalities. Here, by utilizing vision-language model (VLM), we proposed an e2eAD method called SimpleLLM4AD. In our method, the e2eAD task are divided into four stages, which are perception, prediction, planning, and behavior. Each stage consists of several visual question answering (VQA) pairs and VQA pairs interconnect with each other constructing a graph called Graph VQA (GVQA). By reasoning each VQA pair in the GVQA through VLM stage by stage, our method could achieve e2e driving with language. In our method, vision transformers (ViT) models are employed to process nuScenes visual data, while VLM are utilized to interpret and reason about the information extracted from the visual inputs. In the perception stage, the system identifies and classifies objects from the driving environment. The prediction stage involves forecasting the potential movements of these objects. The planning stage utilizes the gathered information to develop a driving strategy, ensuring the safety and efficiency of the autonomous vehicle. Finally, the behavior stage translates the planned actions into executable commands for the vehicle. Our experiments demonstrate that SimpleLLM4AD achieves competitive performance in complex driving scenarios.
Read more8/1/2024