SimpleLLM4AD: An End-to-End Vision-Language Model with Graph Visual Question Answering for Autonomous Driving

0
📈
Sign in to get full access
Overview
- This paper introduces SimpleLLM4AD, an end-to-end vision-language model for autonomous driving tasks.
- It combines advanced language understanding with graph-based visual reasoning to enable comprehensive scene understanding for self-driving cars.
- The model is designed to be efficient and lightweight, making it suitable for real-world deployment.
Plain English Explanation
The paper describes a new artificial intelligence system called SimpleLLM4AD that can help self-driving cars better understand their surroundings. The system combines two powerful AI techniques:
- Language Understanding: It can read and interpret natural language instructions or questions about the driving environment.
- Visual Reasoning: It can analyze camera images of the road, traffic, and other objects to answer questions or make decisions.
By bringing these capabilities together, SimpleLLM4AD aims to give self-driving cars a more comprehensive understanding of their environment. This could help them navigate more safely and make better decisions.
The key innovation is the use of a "graph-based visual question answering" approach. This allows the system to reason about the relationships between different objects and elements in the driving scene, rather than just identifying individual things.
The researchers designed SimpleLLM4AD to be efficient and lightweight, so it can be deployed in real self-driving cars without requiring a lot of computing power. This is an important consideration for making the technology practical for widespread use.
Technical Explanation
The SimpleLLM4AD model is built on a transformer-based architecture that takes in both visual and textual inputs. The visual input comes from camera images, which are processed through a series of convolutional neural network layers to extract visual features.
The textual input, such as natural language questions or instructions, is encoded using a language model. The visual and textual features are then combined and passed through a graph neural network that models the relationships between different elements in the scene.
This graph-based visual question answering approach allows the model to reason about the context and semantics of the driving environment, going beyond just object detection.
The researchers evaluated SimpleLLM4AD on a range of autonomous driving tasks, including answering questions about the scene, predicting future actions, and planning safe trajectories. The results showed that the model outperformed previous state-of-the-art approaches, while maintaining a relatively small and efficient footprint.
Critical Analysis
The paper presents a compelling vision for how large language models can be effectively integrated with computer vision to enable more comprehensive scene understanding for autonomous driving.
However, the authors acknowledge that the current version of SimpleLLM4AD is still limited in its ability to handle complex, open-ended language inputs. Further research is needed to improve the model's natural language understanding capabilities.
Additionally, the paper does not provide a detailed analysis of the model's performance in real-world driving scenarios, which can be significantly more challenging than the controlled test environments used in the experiments. Validating the system's robustness and safety in diverse and unpredictable situations will be crucial for widespread deployment.
Conclusion
The SimpleLLM4AD model represents an important step forward in the development of advanced AI systems for autonomous driving. By combining language understanding and graph-based visual reasoning, it demonstrates the potential for vision-language models to provide a more holistic and contextual understanding of driving environments.
As the research in this area continues to progress, the integration of these capabilities into real-world self-driving systems could lead to significant improvements in safety, efficiency, and user experience. However, further advancements in areas such as robustness, scalability, and real-world validation will be necessary to realize the full potential of this technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
SimpleLLM4AD: An End-to-End Vision-Language Model with Graph Visual Question Answering for Autonomous Driving
Peiru Zheng, Yun Zhao, Zhan Gong, Hong Zhu, Shaohua Wu
Many fields could benefit from the rapid development of the large language models (LLMs). The end-to-end autonomous driving (e2eAD) is one of the typically fields facing new opportunities as the LLMs have supported more and more modalities. Here, by utilizing vision-language model (VLM), we proposed an e2eAD method called SimpleLLM4AD. In our method, the e2eAD task are divided into four stages, which are perception, prediction, planning, and behavior. Each stage consists of several visual question answering (VQA) pairs and VQA pairs interconnect with each other constructing a graph called Graph VQA (GVQA). By reasoning each VQA pair in the GVQA through VLM stage by stage, our method could achieve e2e driving with language. In our method, vision transformers (ViT) models are employed to process nuScenes visual data, while VLM are utilized to interpret and reason about the information extracted from the visual inputs. In the perception stage, the system identifies and classifies objects from the driving environment. The prediction stage involves forecasting the potential movements of these objects. The planning stage utilizes the gathered information to develop a driving strategy, ensuring the safety and efficiency of the autonomous vehicle. Finally, the behavior stage translates the planned actions into executable commands for the vehicle. Our experiments demonstrate that SimpleLLM4AD achieves competitive performance in complex driving scenarios.
Read more8/1/2024
0
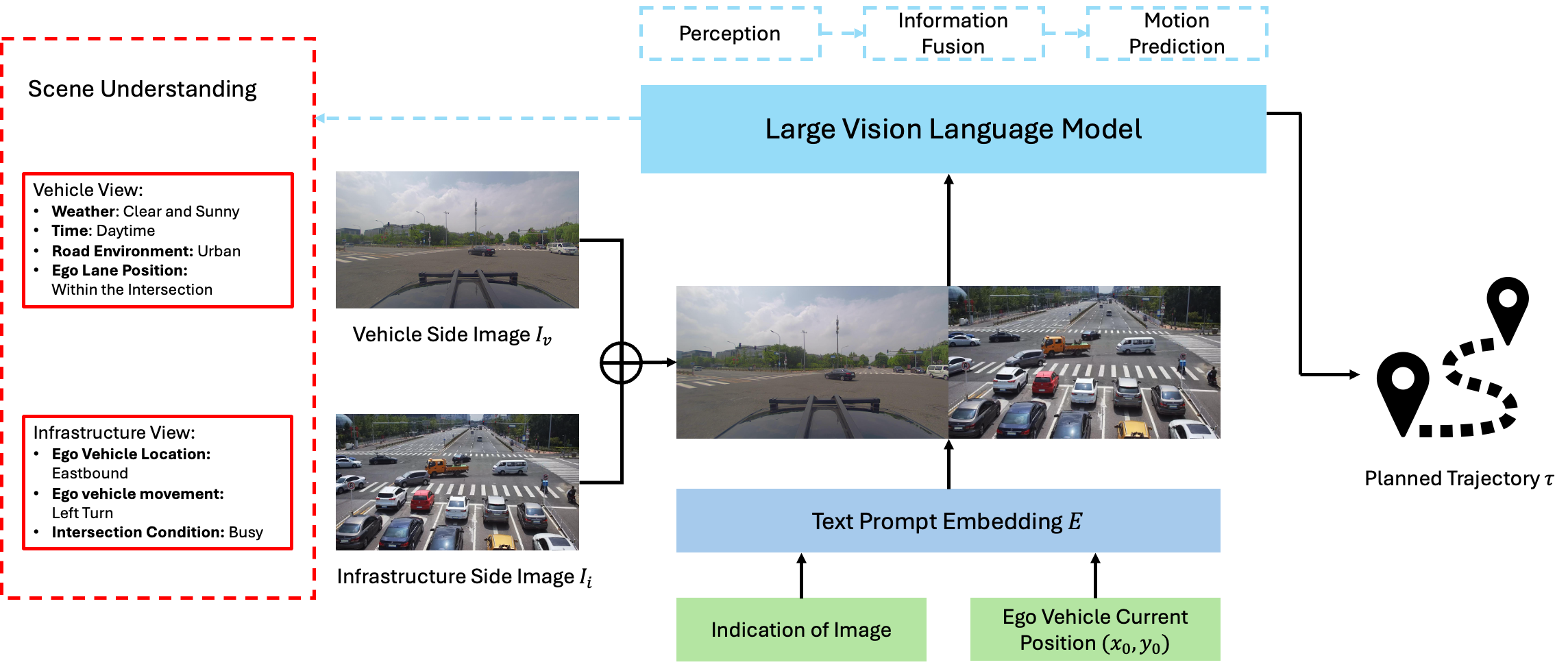
V2X-VLM: End-to-End V2X Cooperative Autonomous Driving Through Large Vision-Language Models
Junwei You, Haotian Shi, Zhuoyu Jiang, Zilin Huang, Rui Gan, Keshu Wu, Xi Cheng, Xiaopeng Li, Bin Ran
Advancements in autonomous driving have increasingly focused on end-to-end (E2E) systems that manage the full spectrum of driving tasks, from environmental perception to vehicle navigation and control. This paper introduces V2X-VLM, an innovative E2E vehicle-infrastructure cooperative autonomous driving (VICAD) framework with Vehicle-to-Everything (V2X) systems and large vision-language models (VLMs). V2X-VLM is designed to enhance situational awareness, decision-making, and ultimate trajectory planning by integrating multimodel data from vehicle-mounted cameras, infrastructure sensors, and textual information. The contrastive learning method is further employed to complement VLM by refining feature discrimination, assisting the model to learn robust representations of the driving environment. Evaluations on the DAIR-V2X dataset show that V2X-VLM outperforms state-of-the-art cooperative autonomous driving methods, while additional tests on corner cases validate its robustness in real-world driving conditions.
Read more9/17/2024
📈
0
Multi-Frame, Lightweight & Efficient Vision-Language Models for Question Answering in Autonomous Driving
Akshay Gopalkrishnan, Ross Greer, Mohan Trivedi
Vision-Language Models (VLMs) and Multi-Modal Language models (MMLMs) have become prominent in autonomous driving research, as these models can provide interpretable textual reasoning and responses for end-to-end autonomous driving safety tasks using traffic scene images and other data modalities. However, current approaches to these systems use expensive large language model (LLM) backbones and image encoders, making such systems unsuitable for real-time autonomous driving systems where tight memory constraints exist and fast inference time is necessary. To address these previous issues, we develop EM-VLM4AD, an efficient, lightweight, multi-frame vision language model which performs Visual Question Answering for autonomous driving. In comparison to previous approaches, EM-VLM4AD requires at least 10 times less memory and floating point operations, while also achieving higher CIDEr and ROUGE-L scores than the existing baseline on the DriveLM dataset. EM-VLM4AD also exhibits the ability to extract relevant information from traffic views related to prompts and can answer questions for various autonomous driving subtasks. We release our code to train and evaluate our model at https://github.com/akshaygopalkr/EM-VLM4AD.
Read more5/10/2024
📊
0
DriveLM: Driving with Graph Visual Question Answering
Chonghao Sima, Katrin Renz, Kashyap Chitta, Li Chen, Hanxue Zhang, Chengen Xie, Jens Bei{ss}wenger, Ping Luo, Andreas Geiger, Hongyang Li
We study how vision-language models (VLMs) trained on web-scale data can be integrated into end-to-end driving systems to boost generalization and enable interactivity with human users. While recent approaches adapt VLMs to driving via single-round visual question answering (VQA), human drivers reason about decisions in multiple steps. Starting from the localization of key objects, humans estimate object interactions before taking actions. The key insight is that with our proposed task, Graph VQA, where we model graph-structured reasoning through perception, prediction and planning question-answer pairs, we obtain a suitable proxy task to mimic the human reasoning process. We instantiate datasets (DriveLM-Data) built upon nuScenes and CARLA, and propose a VLM-based baseline approach (DriveLM-Agent) for jointly performing Graph VQA and end-to-end driving. The experiments demonstrate that Graph VQA provides a simple, principled framework for reasoning about a driving scene, and DriveLM-Data provides a challenging benchmark for this task. Our DriveLM-Agent baseline performs end-to-end autonomous driving competitively in comparison to state-of-the-art driving-specific architectures. Notably, its benefits are pronounced when it is evaluated zero-shot on unseen objects or sensor configurations. We hope this work can be the starting point to shed new light on how to apply VLMs for autonomous driving. To facilitate future research, all code, data, and models are available to the public.
Read more7/18/2024