Vamos: Versatile Action Models for Video Understanding
2311.13627
0
0

Abstract
What makes good representations for video understanding, such as anticipating future activities, or answering video-conditioned questions? While earlier approaches focus on end-to-end learning directly from video pixels, we propose to revisit text-based representations, such as general-purpose video captions, which are interpretable and can be directly consumed by large language models (LLMs). Intuitively, different video understanding tasks may require representations that are complementary and at different granularity. To this end, we propose versatile action models (Vamos), a learning framework powered by a large language model as the ``reasoner'', and can flexibly leverage visual embedding and free-form text descriptions as its input. To interpret the important text evidence for question answering, we generalize the concept bottleneck model to work with tokens and nonlinear models, which uses hard attention to select a small subset of tokens from the free-form text as inputs to the LLM reasoner. We evaluate Vamos on four complementary video understanding benchmarks, Ego4D, NeXT-QA, IntentQA, and EgoSchema, on its capability to model temporal dynamics, encode visual history, and perform reasoning. Surprisingly, we observe that text-based representations consistently achieve competitive performance on all benchmarks, and that visual embeddings provide marginal or no performance improvement, demonstrating the effectiveness of text-based video representation in the LLM era. We also demonstrate that our token bottleneck model is able to select relevant evidence from free-form text, support test-time intervention, and achieves nearly 5 times inference speedup while keeping a competitive question answering performance. Code and models are publicly released at https://brown-palm.github.io/Vamos/.
Create account to get full access
Overview
- This paper introduces a new video understanding model called Vamos, which is designed to be versatile and applicable to a wide range of video understanding tasks.
- Vamos leverages large language models to learn powerful video representations that can be effectively finetuned for various downstream tasks, such as action recognition, video retrieval, and video question answering.
- The paper showcases the versatility of Vamos through extensive experiments on multiple video benchmarks, demonstrating its strong performance compared to other state-of-the-art approaches.
Plain English Explanation
The paper presents a new video understanding model called Vamos that is designed to be flexible and useful for a variety of video-related tasks. Vamos uses large language models, which are powerful AI systems trained on vast amounts of text data, to learn meaningful representations of video content. These representations can then be fine-tuned, or adapted, to perform different tasks, like recognizing actions in videos, finding relevant videos based on a query, or answering questions about the contents of a video.
The key idea behind Vamos is that by leveraging the rich language understanding capabilities of large language models, the model can learn powerful video representations that are applicable to many different video understanding problems. This is in contrast to more specialized models that may perform well on a specific task but struggle to generalize to other tasks.
Through extensive experiments on various video benchmarks, the researchers demonstrate that Vamos outperforms other state-of-the-art approaches across a range of video understanding tasks. This showcases the versatility and effectiveness of the Vamos model, making it a promising tool for researchers and developers working on video-related applications.
Technical Explanation
The paper introduces the Vamos (Versatile Action Models for Video Understanding) framework, which leverages large language models to learn powerful video representations that can be effectively fine-tuned for a variety of downstream tasks. Vamos consists of a video encoder and a task-specific head, where the video encoder is based on a large language model that has been pretrained on vast amounts of text data.
The key innovation of Vamos is its ability to transfer the rich language understanding capabilities of large language models to the video domain. By fine-tuning the pretrained language model on video data, Vamos learns video representations that capture both visual and semantic information, making them versatile and applicable to a wide range of video understanding tasks.
The paper presents a thorough evaluation of Vamos on multiple video benchmarks, including action recognition, video retrieval, and video question answering. The results demonstrate that Vamos outperforms state-of-the-art approaches on these tasks, highlighting the versatility and effectiveness of the proposed framework.
Critical Analysis
The Vamos paper presents a compelling approach to video understanding that builds on the success of large language models. By leveraging these powerful language models, the researchers are able to develop a versatile video understanding framework that can be effectively applied to a variety of tasks.
One potential limitation of the Vamos approach is that it relies on the availability of large-scale video datasets for fine-tuning the language model. In settings where such datasets are scarce or difficult to obtain, the performance of Vamos may be limited. Additionally, the paper does not deeply explore the interpretability or explainability of the Vamos model, which could be an important consideration for certain applications.
That said, the strong empirical results presented in the paper suggest that Vamos is a promising direction for video understanding research. The ability to leverage language models to learn versatile video representations is a significant advancement in the field, and the paper lays the groundwork for further exploration and refinement of this approach.
Conclusion
The Vamos paper introduces a novel video understanding framework that leverages large language models to learn powerful and versatile video representations. By fine-tuning these language models on video data, Vamos is able to capture both visual and semantic information, enabling it to perform well on a range of video understanding tasks.
The impressive results demonstrated in the paper suggest that Vamos represents a significant step forward in video understanding research. The versatility and effectiveness of the Vamos model have the potential to enable a wide range of video-based applications, from action recognition to video retrieval and question answering.
As the field of video understanding continues to evolve, the Vamos approach offers a promising direction for researchers and developers to explore, potentially leading to even more advanced and capable video understanding systems in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
A Survey on Vision-Language-Action Models for Embodied AI
Yueen Ma, Zixing Song, Yuzheng Zhuang, Jianye Hao, Irwin King
0
0
Deep learning has demonstrated remarkable success across many domains, including computer vision, natural language processing, and reinforcement learning. Representative artificial neural networks in these fields span convolutional neural networks, Transformers, and deep Q-networks. Built upon unimodal neural networks, numerous multi-modal models have been introduced to address a range of tasks such as visual question answering, image captioning, and speech recognition. The rise of instruction-following robotic policies in embodied AI has spurred the development of a novel category of multi-modal models known as vision-language-action models (VLAs). Their multi-modality capability has become a foundational element in robot learning. Various methods have been proposed to enhance traits such as versatility, dexterity, and generalizability. Some models focus on refining specific components through pretraining. Others aim to develop control policies adept at predicting low-level actions. Certain VLAs serve as high-level task planners capable of decomposing long-horizon tasks into executable subtasks. Over the past few years, a myriad of VLAs have emerged, reflecting the rapid advancement of embodied AI. Therefore, it is imperative to capture the evolving landscape through a comprehensive survey.
5/24/2024

AlanaVLM: A Multimodal Embodied AI Foundation Model for Egocentric Video Understanding
Alessandro Suglia, Claudio Greco, Katie Baker, Jose L. Part, Ioannis Papaioannou, Arash Eshghi, Ioannis Konstas, Oliver Lemon
0
0
AI personal assistants deployed via robots or wearables require embodied understanding to collaborate with humans effectively. However, current Vision-Language Models (VLMs) primarily focus on third-person view videos, neglecting the richness of egocentric perceptual experience. To address this gap, we propose three key contributions. First, we introduce the Egocentric Video Understanding Dataset (EVUD) for training VLMs on video captioning and question answering tasks specific to egocentric videos. Second, we present AlanaVLM, a 7B parameter VLM trained using parameter-efficient methods on EVUD. Finally, we evaluate AlanaVLM's capabilities on OpenEQA, a challenging benchmark for embodied video question answering. Our model achieves state-of-the-art performance, outperforming open-source models including strong Socratic models using GPT-4 as a planner by 3.6%. Additionally, we outperform Claude 3 and Gemini Pro Vision 1.0 and showcase competitive results compared to Gemini Pro 1.5 and GPT-4V, even surpassing the latter in spatial reasoning. This research paves the way for building efficient VLMs that can be deployed in robots or wearables, leveraging embodied video understanding to collaborate seamlessly with humans in everyday tasks, contributing to the next generation of Embodied AI.
6/24/2024
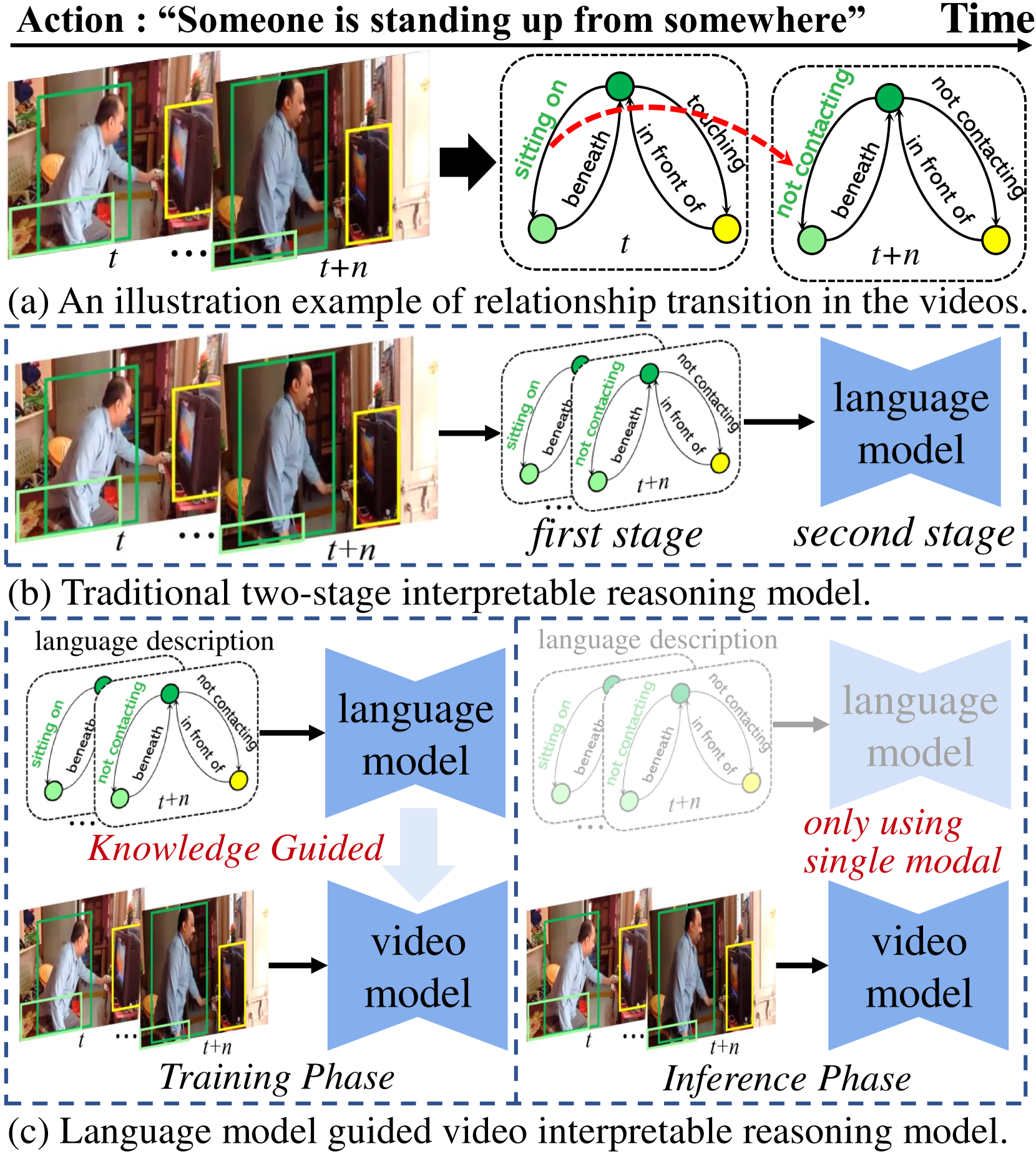
Language Model Guided Interpretable Video Action Reasoning
Ning Wang, Guangming Zhu, HS Li, Liang Zhang, Syed Afaq Ali Shah, Mohammed Bennamoun
0
0
While neural networks have excelled in video action recognition tasks, their black-box nature often obscures the understanding of their decision-making processes. Recent approaches used inherently interpretable models to analyze video actions in a manner akin to human reasoning. These models, however, usually fall short in performance compared to their black-box counterparts. In this work, we present a new framework named Language-guided Interpretable Action Recognition framework (LaIAR). LaIAR leverages knowledge from language models to enhance both the recognition capabilities and the interpretability of video models. In essence, we redefine the problem of understanding video model decisions as a task of aligning video and language models. Using the logical reasoning captured by the language model, we steer the training of the video model. This integrated approach not only improves the video model's adaptability to different domains but also boosts its overall performance. Extensive experiments on two complex video action datasets, Charades & CAD-120, validates the improved performance and interpretability of our LaIAR framework. The code of LaIAR is available at https://github.com/NingWang2049/LaIAR.
4/3/2024

VideoVista: A Versatile Benchmark for Video Understanding and Reasoning
Yunxin Li, Xinyu Chen, Baotian Hu, Longyue Wang, Haoyuan Shi, Min Zhang
0
0
Despite significant breakthroughs in video analysis driven by the rapid development of large multimodal models (LMMs), there remains a lack of a versatile evaluation benchmark to comprehensively assess these models' performance in video understanding and reasoning. To address this, we present VideoVista, a video QA benchmark that integrates challenges across diverse content categories, durations, and abilities. Specifically, VideoVista comprises 25,000 questions derived from 3,400 videos spanning 14 categories (e.g., Howto, Film, and Entertainment) with durations ranging from a few seconds to over 10 minutes. Besides, it encompasses 19 types of understanding tasks (e.g., anomaly detection, interaction understanding) and 8 reasoning tasks (e.g., logical reasoning, causal reasoning). To achieve this, we present an automatic data construction framework, leveraging powerful GPT-4o alongside advanced analysis tools (e.g., video splitting, object segmenting, and tracking). We also utilize this framework to construct training data to enhance the capabilities of video-related LMMs (Video-LMMs). Through a comprehensive and quantitative evaluation of cutting-edge models, we reveal that: 1) Video-LMMs face difficulties in fine-grained video tasks involving temporal location, object tracking, and anomaly detection; 2) Video-LMMs present inferior logical and relation reasoning abilities; 3) Open-source Video-LMMs' performance is significantly lower than GPT-4o and Gemini-1.5, lagging by 20 points. This highlights the crucial role VideoVista will play in advancing LMMs that can accurately understand videos and perform precise reasoning.
6/18/2024