Neural Networks Make Approximately Independent Errors Over Repeated Training
2304.01910
1
0
🧠
Abstract
Typical neural network trainings have substantial variance in test-set performance between repeated runs, impeding hyperparameter comparison and training reproducibility. In this work we present the following results towards understanding this variation. (1) Despite having significant variance on their test-sets, we demonstrate that standard CIFAR-10 and ImageNet trainings have little variance in performance on the underlying test-distributions from which their test-sets are sampled. (2) We show that these trainings make approximately independent errors on their test-sets. That is, the event that a trained network makes an error on one particular example does not affect its chances of making errors on other examples, relative to their average rates over repeated runs of training with the same hyperparameters. (3) We prove that the variance of neural network trainings on their test-sets is a downstream consequence of the class-calibration property discovered by Jiang et al. (2021). Our analysis yields a simple formula which accurately predicts variance for the binary classification case. (4) We conduct preliminary studies of data augmentation, learning rate, finetuning instability and distribution-shift through the lens of variance between runs.
Create account to get full access
Overview
- Typical neural network trainings have significant variation in their test-set performance across repeated runs, which can make it difficult to compare hyperparameters and ensure reproducibility.
- This paper presents several key findings that help explain this variation:
- Despite the variance in test-set performance, there is little variance in performance on the underlying test distributions.
- Neural networks make approximately independent errors on their test-sets.
- The variance in test-set performance is a consequence of the "class-calibration" property discovered in prior research.
- The paper also explores the impact of factors like data augmentation, learning rate, and distribution shift on this variance.
Plain English Explanation
When training neural networks, researchers often find that the performance on the test-set can vary a lot between repeated runs, even when using the same hyperparameters. This makes it challenging to fairly compare different training approaches and to ensure that the results can be consistently reproduced.
The key findings from this paper help explain what's going on under the hood. **[https://aimodels.fyi/papers/arxiv/can-biases-imagenet-models-explain-generalization]**Despite the high variance in test-set performance, the underlying performance of the trained networks on the full test distribution is actually quite consistent. It seems that the networks are making errors in an approximately random way, without any strong dependencies between the errors on different test examples.
The researchers show that this test-set variance is a consequence of a property called "class-calibration" that was discovered in prior work. [https://aimodels.fyi/papers/arxiv/zero-shot-generalization-across-architectures-visual-classification] Essentially, the networks are well-calibrated to the true class probabilities, but this calibration introduces variance when evaluated on a finite test-set.
The paper also explores how factors like data augmentation, learning rate, and distribution shift impact this variance between training runs. [https://aimodels.fyi/papers/arxiv/machine-learning-network-inference-enhancement-from-noisy], [https://aimodels.fyi/papers/arxiv/adversarial-training-1-nearest-neighbor-classifier] This provides insights into strategies for stabilizing neural network training and improving the consistency of results.
Technical Explanation
The key technical findings from the paper are:
-
Test Distribution Consistency: Despite the substantial variance in test-set performance across repeated neural network trainings, the researchers demonstrate that the underlying performance on the full test distribution is much more consistent. This suggests the test-set variance is not due to fundamental differences in the trained models' capabilities.
-
Independent Errors: The paper shows that the trained networks make approximately independent errors on their test-sets. That is, the fact that a network makes an error on one example does not significantly affect its chances of making an error on other examples, beyond the average error rate.
-
Class-Calibration and Variance: The researchers prove that the test-set variance is a consequence of the "class-calibration" property discovered by prior work. [https://aimodels.fyi/papers/arxiv/machine-learning-network-inference-enhancement-from-noisy] They provide a simple formula that accurately predicts the variance for the binary classification case.
-
Influencing Factors: The paper also presents preliminary studies on how factors like data augmentation, learning rate, finetuning instability, and distribution shift impact the variance between training runs. [https://aimodels.fyi/papers/arxiv/adversarial-training-1-nearest-neighbor-classifier]
Critical Analysis
The paper provides a thorough and insightful analysis of the variation in test-set performance for neural network trainings. The key findings help explain this phenomenon and point to potential strategies for improving training consistency.
One potential limitation is the focus on standard computer vision benchmarks like CIFAR-10 and ImageNet. It would be interesting to see if the same patterns hold for other domains and tasks, such as natural language processing or reinforcement learning.
Additionally, while the class-calibration explanation provides a mathematical foundation for understanding the test-set variance, it would be valuable to have a more intuitive understanding of the underlying mechanisms. Further research exploring the connection between network properties, the training process, and the observed variance could yield additional insights.
Overall, this paper makes a significant contribution to our understanding of neural network training dynamics and sets the stage for future work on improving the reproducibility and stability of deep learning systems.
Conclusion
This paper sheds light on the long-standing issue of substantial variation in test-set performance for neural network trainings. The key findings reveal that despite this observed variance, the underlying performance on the full test distribution is much more consistent, and the errors made by the networks are approximately independent.
The researchers trace this test-set variance back to the "class-calibration" property of the trained models, providing a mathematical explanation and a formula to predict the variance. They also explore how factors like data augmentation, learning rate, and distribution shift impact this variance.
These insights have important implications for the field of deep learning, as they can inform strategies for stabilizing training, improving reproducibility, and more reliably comparing different approaches. By better understanding the sources of variation in neural network performance, researchers and practitioners can work towards building more robust and reliable deep learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Feature Contamination: Neural Networks Learn Uncorrelated Features and Fail to Generalize
Tianren Zhang, Chujie Zhao, Guanyu Chen, Yizhou Jiang, Feng Chen
0
0
Learning representations that generalize under distribution shifts is critical for building robust machine learning models. However, despite significant efforts in recent years, algorithmic advances in this direction have been limited. In this work, we seek to understand the fundamental difficulty of out-of-distribution generalization with deep neural networks. We first empirically show that perhaps surprisingly, even allowing a neural network to explicitly fit the representations obtained from a teacher network that can generalize out-of-distribution is insufficient for the generalization of the student network. Then, by a theoretical study of two-layer ReLU networks optimized by stochastic gradient descent (SGD) under a structured feature model, we identify a fundamental yet unexplored feature learning proclivity of neural networks, feature contamination: neural networks can learn uncorrelated features together with predictive features, resulting in generalization failure under distribution shifts. Notably, this mechanism essentially differs from the prevailing narrative in the literature that attributes the generalization failure to spurious correlations. Overall, our results offer new insights into the non-linear feature learning dynamics of neural networks and highlight the necessity of considering inductive biases in out-of-distribution generalization.
6/7/2024
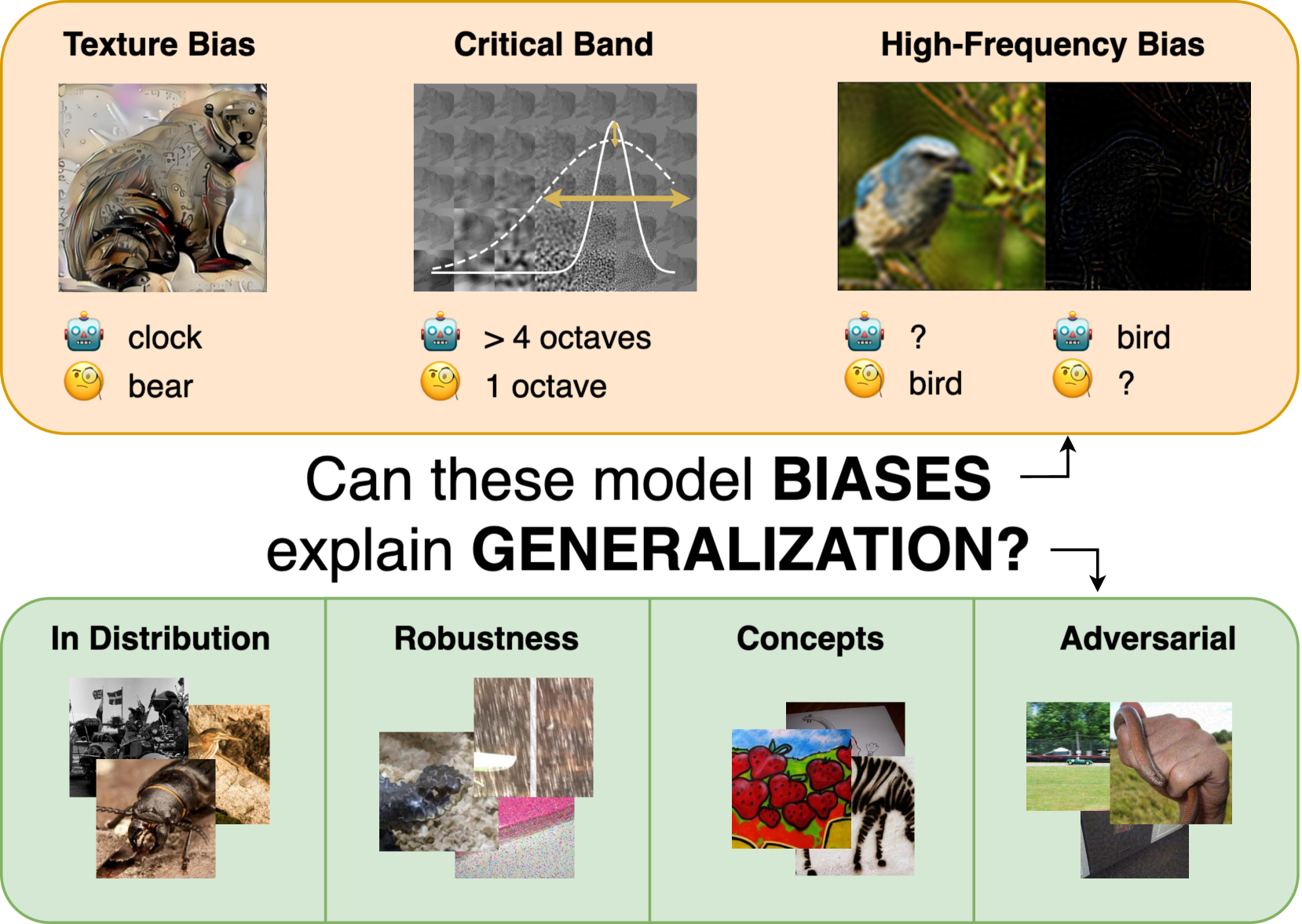
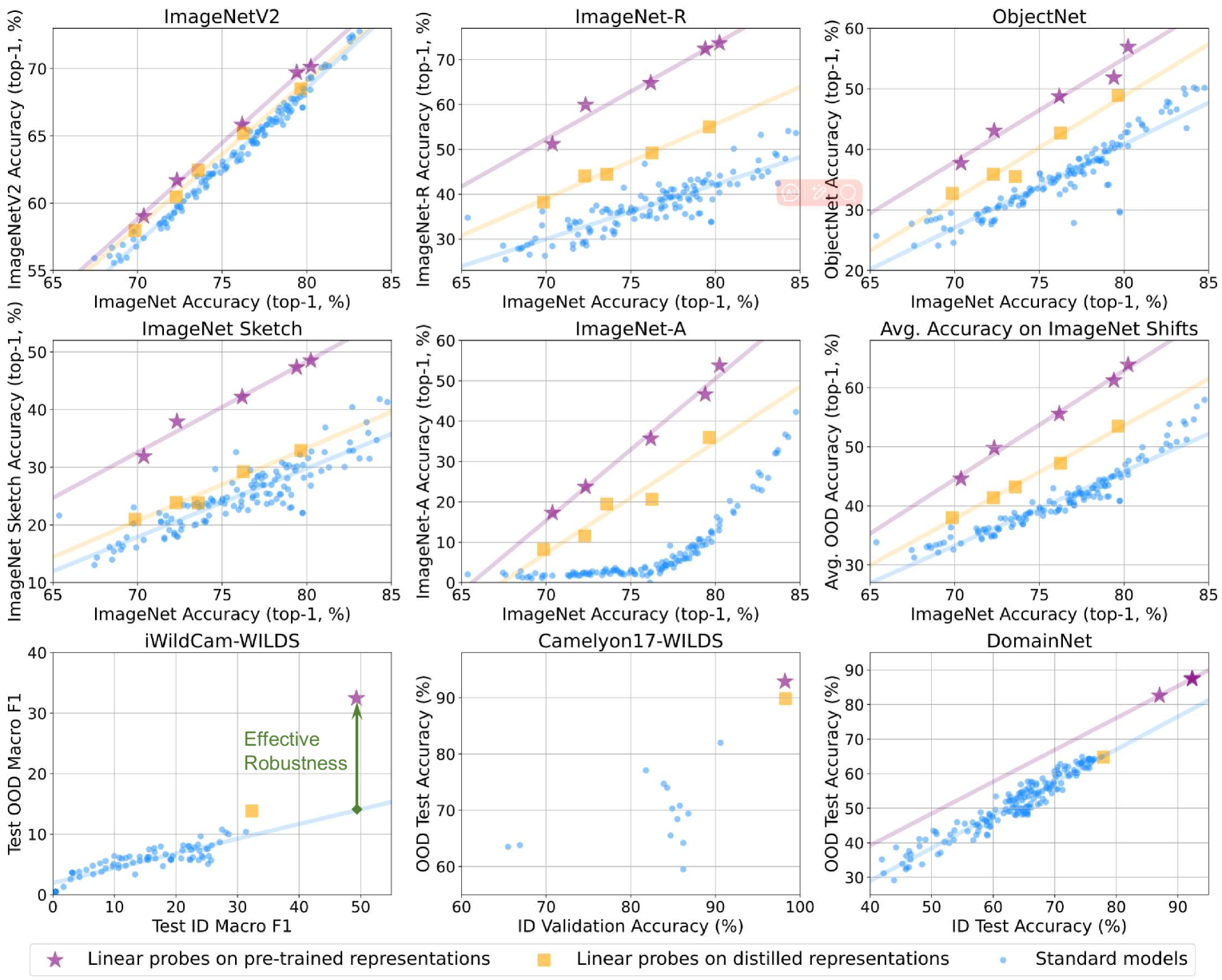
Can Biases in ImageNet Models Explain Generalization?
Paul Gavrikov, Janis Keuper
0
0
The robust generalization of models to rare, in-distribution (ID) samples drawn from the long tail of the training distribution and to out-of-training-distribution (OOD) samples is one of the major challenges of current deep learning methods. For image classification, this manifests in the existence of adversarial attacks, the performance drops on distorted images, and a lack of generalization to concepts such as sketches. The current understanding of generalization in neural networks is very limited, but some biases that differentiate models from human vision have been identified and might be causing these limitations. Consequently, several attempts with varying success have been made to reduce these biases during training to improve generalization. We take a step back and sanity-check these attempts. Fixing the architecture to the well-established ResNet-50, we perform a large-scale study on 48 ImageNet models obtained via different training methods to understand how and if these biases - including shape bias, spectral biases, and critical bands - interact with generalization. Our extensive study results reveal that contrary to previous findings, these biases are insufficient to accurately predict the generalization of a model holistically. We provide access to all checkpoints and evaluation code at https://github.com/paulgavrikov/biases_vs_generalization
4/3/2024
Measuring model variability using robust non-parametric testing
Sinjini Banerjee, Tim Marrinan, Reilly Cannon, Tony Chiang, Anand D. Sarwate
0
0
Training a deep neural network often involves stochastic optimization, meaning each run will produce a different model. The seed used to initialize random elements of the optimization procedure heavily influences the quality of a trained model, which may be obscure from many commonly reported summary statistics, like accuracy. However, random seed is often not included in hyper-parameter optimization, perhaps because the relationship between seed and model quality is hard to describe. This work attempts to describe the relationship between deep net models trained with different random seeds and the behavior of the expected model. We adopt robust hypothesis testing to propose a novel summary statistic for network similarity, referred to as the $alpha$-trimming level. We use the $alpha$-trimming level to show that the empirical cumulative distribution function of an ensemble model created from a collection of trained models with different random seeds approximates the average of these functions as the number of models in the collection grows large. This insight provides guidance for how many random seeds should be sampled to ensure that an ensemble of these trained models is a reliable representative. We also show that the $alpha$-trimming level is more expressive than different performance metrics like validation accuracy, churn, or expected calibration error when taken alone and may help with random seed selection in a more principled fashion. We demonstrate the value of the proposed statistic in real experiments and illustrate the advantage of fine-tuning over random seed with an experiment in transfer learning.
6/13/2024

Certified Robust Accuracy of Neural Networks Are Bounded due to Bayes Errors
Ruihan Zhang, Jun Sun
0
0
Adversarial examples pose a security threat to many critical systems built on neural networks. While certified training improves robustness, it also decreases accuracy noticeably. Despite various proposals for addressing this issue, the significant accuracy drop remains. More importantly, it is not clear whether there is a certain fundamental limit on achieving robustness whilst maintaining accuracy. In this work, we offer a novel perspective based on Bayes errors. By adopting Bayes error to robustness analysis, we investigate the limit of certified robust accuracy, taking into account data distribution uncertainties. We first show that the accuracy inevitably decreases in the pursuit of robustness due to changed Bayes error in the altered data distribution. Subsequently, we establish an upper bound for certified robust accuracy, considering the distribution of individual classes and their boundaries. Our theoretical results are empirically evaluated on real-world datasets and are shown to be consistent with the limited success of existing certified training results, e.g., for CIFAR10, our analysis results in an upper bound (of certified robust accuracy) of 67.49%, meanwhile existing approaches are only able to increase it from 53.89% in 2017 to 62.84% in 2023.
6/21/2024