Feature Contamination: Neural Networks Learn Uncorrelated Features and Fail to Generalize
2406.03345
0
0
Abstract
Learning representations that generalize under distribution shifts is critical for building robust machine learning models. However, despite significant efforts in recent years, algorithmic advances in this direction have been limited. In this work, we seek to understand the fundamental difficulty of out-of-distribution generalization with deep neural networks. We first empirically show that perhaps surprisingly, even allowing a neural network to explicitly fit the representations obtained from a teacher network that can generalize out-of-distribution is insufficient for the generalization of the student network. Then, by a theoretical study of two-layer ReLU networks optimized by stochastic gradient descent (SGD) under a structured feature model, we identify a fundamental yet unexplored feature learning proclivity of neural networks, feature contamination: neural networks can learn uncorrelated features together with predictive features, resulting in generalization failure under distribution shifts. Notably, this mechanism essentially differs from the prevailing narrative in the literature that attributes the generalization failure to spurious correlations. Overall, our results offer new insights into the non-linear feature learning dynamics of neural networks and highlight the necessity of considering inductive biases in out-of-distribution generalization.
Create account to get full access
Overview
- Neural networks can learn features that are uncorrelated with the task at hand, leading to poor generalization to out-of-distribution data.
- This phenomenon, known as "feature contamination", can cause neural networks to fail to learn the true underlying features that are relevant for the task.
- The paper explores how feature contamination arises and proposes strategies to mitigate it, with the aim of improving the robustness and generalization of neural networks.
Plain English Explanation
Neural networks are powerful machine learning models that can learn to perform a wide variety of tasks, from image recognition to language processing. However, a recent paper has found that these models can sometimes learn features that are not actually relevant for the task they are trying to solve.
This phenomenon, known as "feature contamination", occurs when the neural network picks up on spurious correlations in the training data that are not actually indicative of the true underlying features that are important for the task. For example, if a neural network is trained to classify images of dogs and cats, it might learn to rely on the background of the image rather than the actual features of the animal, because the background may happen to be correlated with the class in the training data.
When the neural network is then applied to new, out-of-distribution data (such as images with different backgrounds), it fails to generalize and performs poorly, because it has learned the wrong features. This is a significant problem, as it means that neural networks may not be as robust or reliable as we would like them to be.
The paper explores the causes of feature contamination and proposes strategies to mitigate it, with the goal of improving the generalization and robustness of neural networks. By understanding how feature contamination arises and developing techniques to address it, researchers hope to create neural networks that are more reliable and better able to handle the complexities of the real world.
Technical Explanation
The paper, "Feature Contamination: Neural Networks Learn Uncorrelated Features and Fail to Generalize", investigates a phenomenon called "feature contamination" in which neural networks learn features that are uncorrelated with the task they are trying to solve, leading to poor generalization to out-of-distribution data.
The authors begin by demonstrating that neural networks can indeed learn features that are uncorrelated with the target label, even when these features are clearly irrelevant to the task. They show this through a series of experiments on simple synthetic datasets, where the neural network learns to rely on "junk features" that are randomly generated and have no actual relationship to the target label.
The paper then explores the mechanisms that lead to this feature contamination, drawing on insights from the representation learning and Bayesian optimization literature. The authors argue that the tendency of neural networks to latch onto uncorrelated features is a result of the "simplicity bias" inherent in these models, which leads them to prefer simpler, more easily learnable features over more complex, task-relevant ones.
To address this issue, the paper proposes several strategies for mitigating feature contamination, including explicit regularization techniques and architectural modifications. The authors demonstrate that these approaches can significantly improve the generalization performance of neural networks, especially in the face of distribution shifts and other challenging out-of-distribution scenarios.
The paper also discusses the implications of feature contamination for the broader field of machine learning, highlighting the need for more robust and reliable models that can generalize beyond the confines of the training data.
Critical Analysis
The paper presents a compelling and well-supported argument for the phenomenon of feature contamination in neural networks, and the authors' proposed mitigation strategies appear promising. However, it's important to note that the paper focuses primarily on simple, synthetic datasets, and the extent to which these findings translate to more complex, real-world scenarios remains to be seen.
One potential limitation of the paper is that it does not explore the role of model architecture, training data, and other factors in determining the severity of feature contamination. It's possible that different neural network architectures or training regimes may be less susceptible to this issue, and further research in this area could provide valuable insights.
Additionally, while the authors' proposed mitigation strategies seem effective in the experiments presented, it's unclear how scalable and practical these approaches would be in large-scale, real-world applications. Further research and experimentation would be needed to assess the broader applicability and impact of these techniques.
Despite these caveats, the paper makes a significant contribution to our understanding of the challenges inherent in representation learning and the importance of developing more robust and generalizable neural network models. As the field of machine learning continues to advance, addressing issues like feature contamination will be crucial for ensuring the reliability and trustworthiness of these powerful technologies.
Conclusion
The paper "Feature Contamination: Neural Networks Learn Uncorrelated Features and Fail to Generalize" highlights a critical issue in the field of machine learning, where neural networks can learn features that are uncorrelated with the task they are trying to solve, leading to poor generalization to out-of-distribution data.
By exploring the mechanisms behind feature contamination and proposing strategies to mitigate it, the authors have made an important contribution to the ongoing effort to create more robust and reliable neural network models. As the application of these models continues to expand, addressing challenges like feature contamination will be essential for ensuring their effectiveness and trustworthiness in real-world scenarios.
While the paper focuses primarily on synthetic datasets, the insights it provides have broader implications for the field of machine learning as a whole. Continued research and experimentation in this area will be crucial for advancing the state of the art and paving the way for more reliable and generalizable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Neural Collapse for Cross-entropy Class-Imbalanced Learning with Unconstrained ReLU Feature Model
Hien Dang, Tho Tran, Tan Nguyen, Nhat Ho
0
0
The current paradigm of training deep neural networks for classification tasks includes minimizing the empirical risk that pushes the training loss value towards zero, even after the training error has been vanished. In this terminal phase of training, it has been observed that the last-layer features collapse to their class-means and these class-means converge to the vertices of a simplex Equiangular Tight Frame (ETF). This phenomenon is termed as Neural Collapse (NC). To theoretically understand this phenomenon, recent works employ a simplified unconstrained feature model to prove that NC emerges at the global solutions of the training problem. However, when the training dataset is class-imbalanced, some NC properties will no longer be true. For example, the class-means geometry will skew away from the simplex ETF when the loss converges. In this paper, we generalize NC to imbalanced regime for cross-entropy loss under the unconstrained ReLU feature model. We prove that, while the within-class features collapse property still holds in this setting, the class-means will converge to a structure consisting of orthogonal vectors with different lengths. Furthermore, we find that the classifier weights are aligned to the scaled and centered class-means with scaling factors depend on the number of training samples of each class, which generalizes NC in the class-balanced setting. We empirically prove our results through experiments on practical architectures and dataset.
6/7/2024
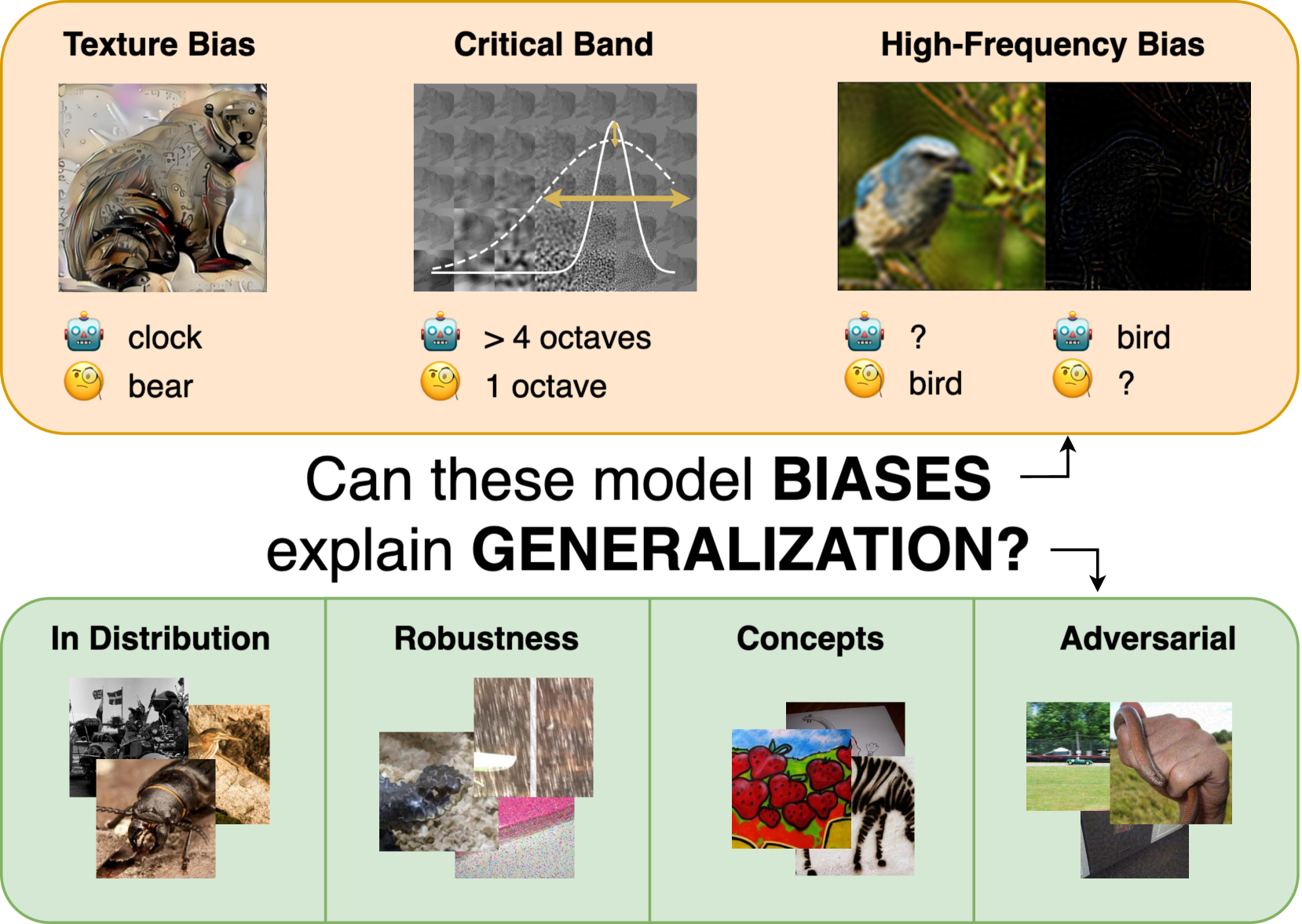
Can Biases in ImageNet Models Explain Generalization?
Paul Gavrikov, Janis Keuper
0
0
The robust generalization of models to rare, in-distribution (ID) samples drawn from the long tail of the training distribution and to out-of-training-distribution (OOD) samples is one of the major challenges of current deep learning methods. For image classification, this manifests in the existence of adversarial attacks, the performance drops on distorted images, and a lack of generalization to concepts such as sketches. The current understanding of generalization in neural networks is very limited, but some biases that differentiate models from human vision have been identified and might be causing these limitations. Consequently, several attempts with varying success have been made to reduce these biases during training to improve generalization. We take a step back and sanity-check these attempts. Fixing the architecture to the well-established ResNet-50, we perform a large-scale study on 48 ImageNet models obtained via different training methods to understand how and if these biases - including shape bias, spectral biases, and critical bands - interact with generalization. Our extensive study results reveal that contrary to previous findings, these biases are insufficient to accurately predict the generalization of a model holistically. We provide access to all checkpoints and evaluation code at https://github.com/paulgavrikov/biases_vs_generalization
4/3/2024
🎯
Generalization in diffusion models arises from geometry-adaptive harmonic representations
Zahra Kadkhodaie, Florentin Guth, Eero P. Simoncelli, St'ephane Mallat
0
0
Deep neural networks (DNNs) trained for image denoising are able to generate high-quality samples with score-based reverse diffusion algorithms. These impressive capabilities seem to imply an escape from the curse of dimensionality, but recent reports of memorization of the training set raise the question of whether these networks are learning the true continuous density of the data. Here, we show that two DNNs trained on non-overlapping subsets of a dataset learn nearly the same score function, and thus the same density, when the number of training images is large enough. In this regime of strong generalization, diffusion-generated images are distinct from the training set, and are of high visual quality, suggesting that the inductive biases of the DNNs are well-aligned with the data density. We analyze the learned denoising functions and show that the inductive biases give rise to a shrinkage operation in a basis adapted to the underlying image. Examination of these bases reveals oscillating harmonic structures along contours and in homogeneous regions. We demonstrate that trained denoisers are inductively biased towards these geometry-adaptive harmonic bases since they arise not only when the network is trained on photographic images, but also when it is trained on image classes supported on low-dimensional manifolds for which the harmonic basis is suboptimal. Finally, we show that when trained on regular image classes for which the optimal basis is known to be geometry-adaptive and harmonic, the denoising performance of the networks is near-optimal.
4/15/2024
📊
Simplicity Bias of Two-Layer Networks beyond Linearly Separable Data
Nikita Tsoy, Nikola Konstantinov
0
0
Simplicity bias, the propensity of deep models to over-rely on simple features, has been identified as a potential reason for limited out-of-distribution generalization of neural networks (Shah et al., 2020). Despite the important implications, this phenomenon has been theoretically confirmed and characterized only under strong dataset assumptions, such as linear separability (Lyu et al., 2021). In this work, we characterize simplicity bias for general datasets in the context of two-layer neural networks initialized with small weights and trained with gradient flow. Specifically, we prove that in the early training phases, network features cluster around a few directions that do not depend on the size of the hidden layer. Furthermore, for datasets with an XOR-like pattern, we precisely identify the learned features and demonstrate that simplicity bias intensifies during later training stages. These results indicate that features learned in the middle stages of training may be more useful for OOD transfer. We support this hypothesis with experiments on image data.
5/28/2024