vec2wav 2.0: Advancing Voice Conversion via Discrete Token Vocoders

0

Sign in to get full access
Overview
- This paper introduces vec2wav 2.0, a new approach to voice conversion that leverages discrete speech tokens and a vocoder.
- The key ideas include:
- Using a self-supervised speech model to extract discrete speech tokens.
- Designing a vocoder that can convert these discrete tokens back into high-quality audio.
- Applying this approach to voice conversion, allowing one speaker's voice to be converted to another's.
Plain English Explanation
The paper presents a new system called vec2wav 2.0 that can convert one person's voice to sound like another person's voice. This is called voice conversion, and it has applications in things like text-to-speech, dubbing, and assistive technology.
The core idea is to first use a machine learning model to analyze the original voice and break it down into a sequence of discrete speech tokens. These tokens represent the basic building blocks of speech, like phonemes or syllables. The vocoder (a type of audio synthesis model) then takes these tokens and uses them to generate a new audio recording that sounds like the target speaker.
This approach has several advantages over previous voice conversion methods. By using discrete speech tokens instead of continuous acoustic features, the system can more accurately capture the unique voice characteristics of each speaker. And the vocoder design allows for high-quality, natural-sounding audio to be generated from these tokens.
The end result is a voice conversion system that can take one person's voice and transform it to sound like another person, while preserving important details like emotion, rhythm, and pronunciation.
Technical Explanation
The key technical innovations in vec2wav 2.0 are:
-
Discrete Speech Token Extraction: The system uses a self-supervised speech model (link) to convert the input audio into a sequence of discrete speech tokens. These tokens capture the fundamental units of speech in a compact, interpretable format.
-
Prompted Token Vocoder: The vocoder component (link) is designed to take the discrete speech tokens and generate high-quality, natural-sounding audio. It uses a diffusion-based generative model that can accurately reconstruct the target speaker's voice.
-
Residual Enhancement: The authors also introduce a "residual enhancement" technique that further improves the quality of the generated audio by modeling the subtle differences between the source and target speakers.
Through extensive experiments, the authors demonstrate that vec2wav 2.0 outperforms previous state-of-the-art voice conversion systems on a range of objective and subjective metrics. The use of discrete speech tokens and the prompted vocoder architecture are key to achieving these strong results.
Critical Analysis
The paper provides a thorough evaluation of vec2wav 2.0, including comparisons to several baseline methods. The authors acknowledge some limitations, such as the potential for the system to struggle with niche or uncommon voices, and they suggest future research directions to address these challenges.
One area that could be explored further is the interpretability and controllability of the discrete speech tokens. Understanding how these tokens relate to specific speech attributes could enable more fine-grained control over the voice conversion process.
Additionally, the authors mention that their system currently requires parallel training data (i.e., recordings of the same content from both the source and target speakers). Developing techniques to perform zero-shot or few-shot voice conversion without this requirement could significantly expand the practical applications of the technology.
Overall, vec2wav 2.0 represents an impressive advance in voice conversion capabilities, with a well-designed architecture and thorough evaluation. The use of discrete speech tokens and the prompted vocoder are promising directions for continued research in this field.
Conclusion
The vec2wav 2.0 paper presents a novel approach to voice conversion that leverages discrete speech tokens and a prompted vocoder to achieve high-quality, natural-sounding voice transformation. By breaking down speech into interpretable units and using a specialized audio generation model, the system can accurately capture and reproduce the unique characteristics of a speaker's voice.
This research has important implications for a wide range of applications, from text-to-speech systems and dubbing to assistive technologies for individuals with speech impairments. The authors have made a significant contribution to the field of voice conversion, and their work may inspire further advancements in the use of discrete representations and generative models for audio processing and synthesis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
vec2wav 2.0: Advancing Voice Conversion via Discrete Token Vocoders
Yiwei Guo, Zhihan Li, Junjie Li, Chenpeng Du, Hankun Wang, Shuai Wang, Xie Chen, Kai Yu
We propose a new speech discrete token vocoder, vec2wav 2.0, which advances voice conversion (VC). We use discrete tokens from speech self-supervised models as the content features of source speech, and treat VC as a prompted vocoding task. To amend the loss of speaker timbre in the content tokens, vec2wav 2.0 utilizes the WavLM features to provide strong timbre-dependent information. A novel adaptive Snake activation function is proposed to better incorporate timbre into the waveform reconstruction process. In this way, vec2wav 2.0 learns to alter the speaker timbre appropriately given different reference prompts. Also, no supervised data is required for vec2wav 2.0 to be effectively trained. Experimental results demonstrate that vec2wav 2.0 outperforms all other baselines to a considerable margin in terms of audio quality and speaker similarity in any-to-any VC. Ablation studies verify the effects made by the proposed techniques. Moreover, vec2wav 2.0 achieves competitive cross-lingual VC even only trained on monolingual corpus. Thus, vec2wav 2.0 shows timbre can potentially be manipulated only by speech token vocoders, pushing the frontiers of VC and speech synthesis.
Read more9/12/2024

1
WavTokenizer: an Efficient Acoustic Discrete Codec Tokenizer for Audio Language Modeling
Shengpeng Ji, Ziyue Jiang, Xize Cheng, Yifu Chen, Minghui Fang, Jialong Zuo, Qian Yang, Ruiqi Li, Ziang Zhang, Xiaoda Yang, Rongjie Huang, Yidi Jiang, Qian Chen, Siqi Zheng, Wen Wang, Zhou Zhao
Language models have been effectively applied to modeling natural signals, such as images, video, speech, and audio. A crucial component of these models is the codec tokenizer, which compresses high-dimensional natural signals into lower-dimensional discrete tokens. In this paper, we introduce WavTokenizer, which offers several advantages over previous SOTA acoustic codec models in the audio domain: 1)extreme compression. By compressing the layers of quantizers and the temporal dimension of the discrete codec, one-second audio of 24kHz sampling rate requires only a single quantizer with 40 or 75 tokens. 2)improved subjective quality. Despite the reduced number of tokens, WavTokenizer achieves state-of-the-art reconstruction quality with outstanding UTMOS scores and inherently contains richer semantic information. Specifically, we achieve these results by designing a broader VQ space, extended contextual windows, and improved attention networks, as well as introducing a powerful multi-scale discriminator and an inverse Fourier transform structure. We conducted extensive reconstruction experiments in the domains of speech, audio, and music. WavTokenizer exhibited strong performance across various objective and subjective metrics compared to state-of-the-art models. We also tested semantic information, VQ utilization, and adaptability to generative models. Comprehensive ablation studies confirm the necessity of each module in WavTokenizer. The related code, demos, and pre-trained models are available at https://github.com/jishengpeng/WavTokenizer.
Read more8/30/2024
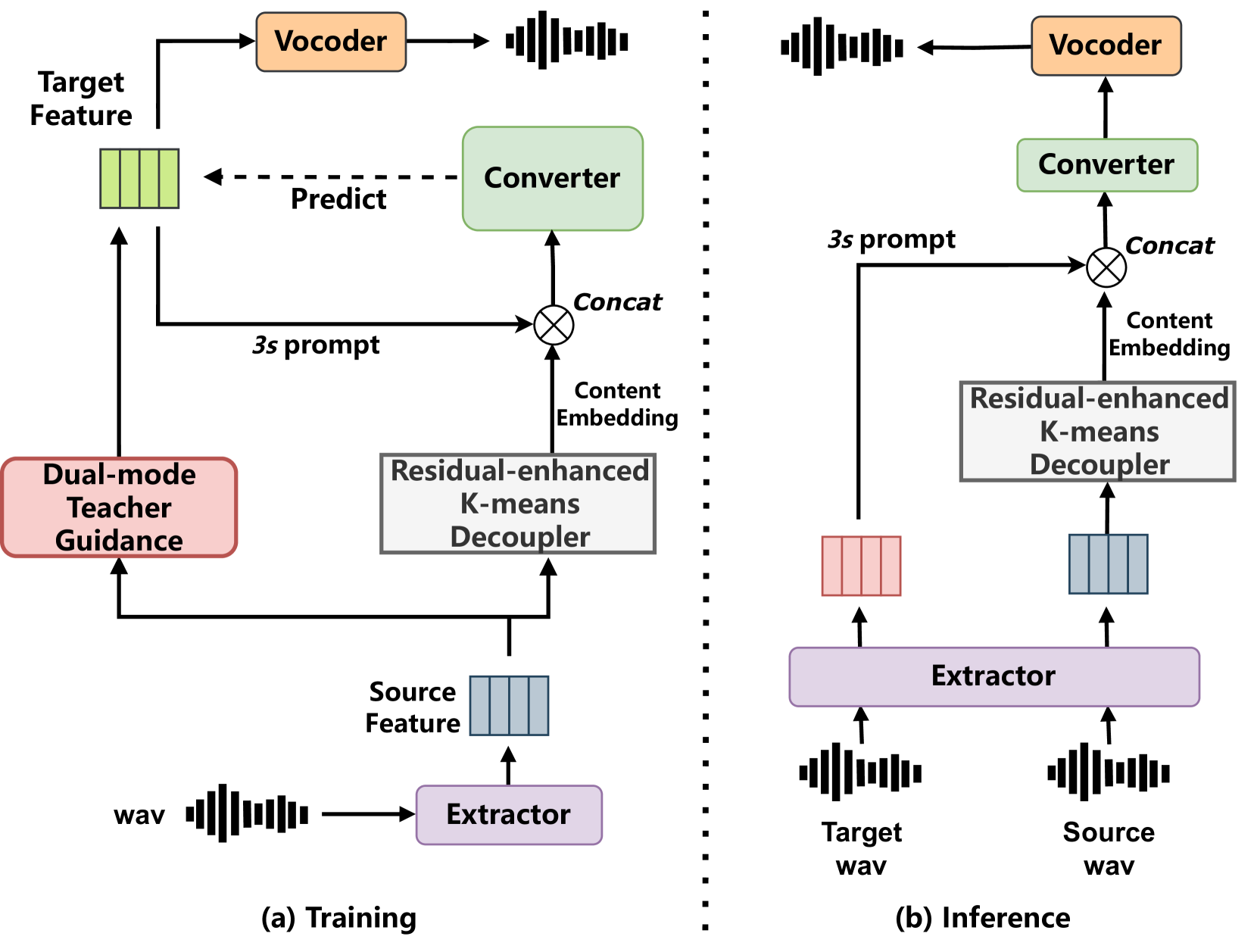
0
Vec-Tok-VC+: Residual-enhanced Robust Zero-shot Voice Conversion with Progressive Constraints in a Dual-mode Training Strategy
Linhan Ma, Xinfa Zhu, Yuanjun Lv, Zhichao Wang, Ziqian Wang, Wendi He, Hongbin Zhou, Lei Xie
Zero-shot voice conversion (VC) aims to transform source speech into arbitrary unseen target voice while keeping the linguistic content unchanged. Recent VC methods have made significant progress, but semantic losses in the decoupling process as well as training-inference mismatch still hinder conversion performance. In this paper, we propose Vec-Tok-VC+, a novel prompt-based zero-shot VC model improved from Vec-Tok Codec, achieving voice conversion given only a 3s target speaker prompt. We design a residual-enhanced K-Means decoupler to enhance the semantic content extraction with a two-layer clustering process. Besides, we employ teacher-guided refinement to simulate the conversion process to eliminate the training-inference mismatch, forming a dual-mode training strategy. Furthermore, we design a multi-codebook progressive loss function to constrain the layer-wise output of the model from coarse to fine to improve speaker similarity and content accuracy. Objective and subjective evaluations demonstrate that Vec-Tok-VC+ outperforms the strong baselines in naturalness, intelligibility, and speaker similarity.
Read more6/17/2024

0
Wav2Small: Distilling Wav2Vec2 to 72K parameters for Low-Resource Speech emotion recognition
Dionyssos Kounadis-Bastian, Oliver Schrufer, Anna Derington, Hagen Wierstorf, Florian Eyben, Felix Burkhardt, Bjorn Schuller
Speech Emotion Recognition (SER) needs high computational resources to overcome the challenge of substantial annotator disagreement. Today SER is shifting towards dimensional annotations of arousal, dominance, and valence (A/D/V). Universal metrics as the L2 distance prove unsuitable for evaluating A/D/V accuracy due to non converging consensus of annotator opinions. However, Concordance Correlation Coefficient (CCC) arose as an alternative metric for A/D/V where a model's output is evaluated to match a whole dataset's CCC rather than L2 distances of individual audios. Recent studies have shown that wav2vec2 / wavLM architectures outputing a float value for each A/D/V dimension achieve today's State-of-the-art (Sota) CCC on A/D/V. The Wav2Vec2.0 / WavLM family has a high computational footprint, but training small models using human annotations has been unsuccessful. In this paper we use a large Transformer Sota A/D/V model as Teacher/Annotator to train 5 student models: 4 MobileNets and our proposed Wav2Small, using only the Teacher's A/D/V outputs instead of human annotations. The Teacher model we propose also sets a new Sota on the MSP Podcast dataset of valence CCC=0.676. We choose MobileNetV4 / MobileNet-V3 as students, as MobileNet has been designed for fast execution times. We also propose Wav2Small - an architecture designed for minimal parameters and RAM consumption. Wav2Small with an .onnx (quantised) of only 120KB is a potential solution for A/D/V on hardware with low resources, having only 72K parameters vs 3.12M parameters for MobileNet-V4-Small.
Read more9/6/2024