VeriSplit: Secure and Practical Offloading of Machine Learning Inferences across IoT Devices

0

Sign in to get full access
Overview
- This paper presents VeriSplit, a secure and practical system for offloading machine learning (ML) inferences across Internet of Things (IoT) devices.
- VeriSplit aims to address the challenge of running computationally-intensive ML models on resource-constrained IoT devices by enabling secure offloading of inference tasks to more powerful edge devices.
- The system incorporates techniques to ensure the integrity and confidentiality of the offloaded inferences, protecting against potential attacks and preserving the privacy of sensitive data.
Plain English Explanation
The paper introduces VeriSplit, a solution that allows IoT devices to securely offload their machine learning (ML) inference tasks to more powerful edge devices. This is important because many IoT devices, like sensors or smart home gadgets, have limited computing resources and struggle to run complex ML models locally.
With VeriSplit, the IoT device can send its data to a nearby edge device, which then performs the ML inference on the device's behalf. This offloading approach helps overcome the resource constraints of IoT devices while ensuring the security and privacy of the process. The system includes techniques to verify the integrity of the offloaded inference results and protect the confidentiality of the data being processed.
By enabling secure offloading of ML tasks, VeriSplit aims to make it practical for IoT devices to leverage advanced AI capabilities without requiring them to have the most powerful hardware. This could unlock new applications and services for IoT systems, while maintaining strong security guarantees.
Technical Explanation
The VeriSplit system consists of several key components:
-
Secure Offloading Protocol: This protocol allows IoT devices to securely transmit their data to edge devices for inference processing, ensuring the integrity and confidentiality of the offloaded tasks.
-
Verification Mechanism: VeriSplit incorporates a verification mechanism that enables the IoT device to validate the correctness of the inference results returned by the edge device, protecting against potential tampering.
-
Secure Computation Framework: The system leverages a secure computation framework, such as [Optimization-Lightweight-Malware-Detection-Models-AioT-Devices], to perform the ML inference tasks on the edge device in a privacy-preserving manner.
-
Adaptive Offloading Strategy: VeriSplit employs an [Adaptive-Parallel-Split-Federated-Learning-Vehicular-Edge] approach to dynamically determine the optimal offloading strategy based on factors like device capabilities, network conditions, and the complexity of the ML model.
The paper evaluates the performance of VeriSplit through a series of experiments, demonstrating its ability to securely offload ML inferences while maintaining low latency and preserving the privacy of the processed data. The results show that VeriSplit can achieve significant performance improvements compared to local execution on resource-constrained IoT devices.
Critical Analysis
The paper provides a comprehensive solution to the challenge of running complex ML models on IoT devices, which is an important problem as the demand for advanced AI capabilities in IoT systems continues to grow. The authors have carefully considered the security and privacy implications of offloading inference tasks and have designed VeriSplit to address these concerns.
However, the paper does not delve into the potential limitations or caveats of the proposed system. For example, the [Make-Split-Not-Hijack-Preventing-Feature-Space] approach used in VeriSplit may introduce additional computational overhead or have specific requirements that could limit its applicability in certain IoT environments.
Additionally, the paper does not discuss the potential impact of the [Optimization-Malware-Detection-IoT-Networks-Leveraging-Resource] techniques used in the secure computation framework on the overall system performance or energy consumption of the IoT devices.
Further research could explore the scalability of VeriSplit in scenarios with a large number of IoT devices and edge devices, as well as its compatibility with different types of ML models and IoT applications.
Conclusion
The VeriSplit system presents a promising approach to enabling secure and practical offloading of machine learning inferences across IoT devices. By leveraging edge computing resources and incorporating robust security measures, VeriSplit aims to unlock the potential of advanced AI capabilities in resource-constrained IoT environments.
The key contributions of this work include the secure offloading protocol, the verification mechanism, and the adaptive offloading strategy, which together provide a comprehensive solution to the challenges of running complex ML models on IoT devices. The experimental results demonstrate the performance benefits and security guarantees of the VeriSplit system, paving the way for more widespread adoption of AI-powered IoT applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
VeriSplit: Secure and Practical Offloading of Machine Learning Inferences across IoT Devices
Han Zhang, Zifan Wang, Mihir Dhamankar, Matt Fredrikson, Yuvraj Agarwal
Many Internet-of-Things (IoT) devices rely on cloud computation resources to perform machine learning inferences. This is expensive and may raise privacy concerns for users. Consumers of these devices often have hardware such as gaming consoles and PCs with graphics accelerators that are capable of performing these computations, which may be left idle for significant periods of time. While this presents a compelling potential alternative to cloud offloading, concerns about the integrity of inferences, the confidentiality of model parameters, and the privacy of users' data mean that device vendors may be hesitant to offload their inferences to a platform managed by another manufacturer. We propose VeriSplit, a framework for offloading machine learning inferences to locally-available devices that address these concerns. We introduce masking techniques to protect data privacy and model confidentiality, and a commitment-based verification protocol to address integrity. Unlike much prior work aimed at addressing these issues, our approach does not rely on computation over finite field elements, which may interfere with floating-point computation supports on hardware accelerators and require modification to existing models. We implemented a prototype of VeriSplit and our evaluation results show that, compared to performing computation locally, our secure and private offloading solution can reduce inference latency by 28%--83%.
Read more6/4/2024
0
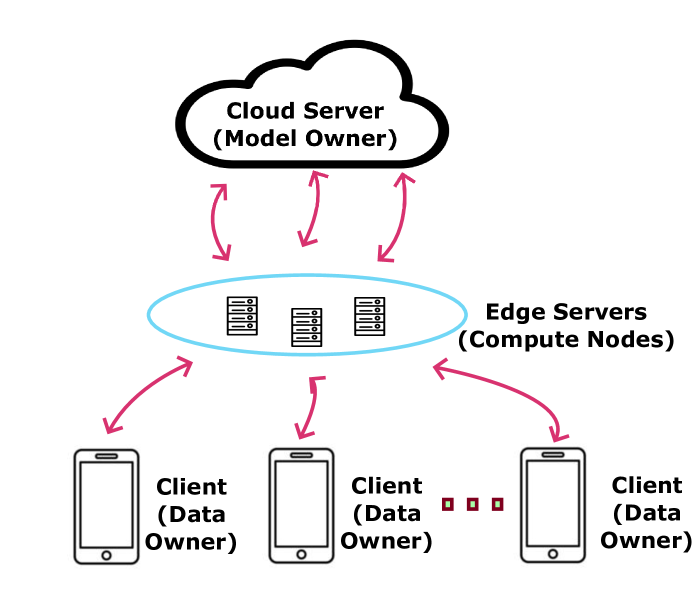
Privacy-Preserving Model-Distributed Inference at the Edge
Fatemeh Jafarian Dehkordi, Yasaman Keshtkarjahromi, Hulya Seferoglu
This paper focuses on designing a privacy-preserving Machine Learning (ML) inference protocol for a hierarchical setup, where clients own/generate data, model owners (cloud servers) have a pre-trained ML model, and edge servers perform ML inference on clients' data using the cloud server's ML model. Our goal is to speed up ML inference while providing privacy to both data and the ML model. Our approach (i) uses model-distributed inference (model parallelization) at the edge servers and (ii) reduces the amount of communication to/from the cloud server. Our privacy-preserving hierarchical model-distributed inference, privateMDI design uses additive secret sharing and linearly homomorphic encryption to handle linear calculations in the ML inference, and garbled circuit and a novel three-party oblivious transfer are used to handle non-linear functions. privateMDI consists of offline and online phases. We designed these phases in a way that most of the data exchange is done in the offline phase while the communication overhead of the online phase is reduced. In particular, there is no communication to/from the cloud server in the online phase, and the amount of communication between the client and edge servers is minimized. The experimental results demonstrate that privateMDI significantly reduces the ML inference time as compared to the baselines.
Read more9/17/2024
🌀
0
MTL-Split: Multi-Task Learning for Edge Devices using Split Computing
Luigi Capogrosso, Enrico Fraccaroli, Samarjit Chakraborty, Franco Fummi, Marco Cristani
Split Computing (SC), where a Deep Neural Network (DNN) is intelligently split with a part of it deployed on an edge device and the rest on a remote server is emerging as a promising approach. It allows the power of DNNs to be leveraged for latency-sensitive applications that do not allow the entire DNN to be deployed remotely, while not having sufficient computation bandwidth available locally. In many such embedded systems scenarios, such as those in the automotive domain, computational resource constraints also necessitate Multi-Task Learning (MTL), where the same DNN is used for multiple inference tasks instead of having dedicated DNNs for each task, which would need more computing bandwidth. However, how to partition such a multi-tasking DNN to be deployed within a SC framework has not been sufficiently studied. This paper studies this problem, and MTL-Split, our novel proposed architecture, shows encouraging results on both synthetic and real-world data. The source code is available at https://github.com/intelligolabs/MTL-Split.
Read more7/9/2024

0
Complete Security and Privacy for AI Inference in Decentralized Systems
Hongyang Zhang, Yue Zhao, Claudio Angione, Harry Yang, James Buban, Ahmad Farhan, Fielding Johnston, Patrick Colangelo
The need for data security and model integrity has been accentuated by the rapid adoption of AI and ML in data-driven domains including healthcare, finance, and security. Large models are crucial for tasks like diagnosing diseases and forecasting finances but tend to be delicate and not very scalable. Decentralized systems solve this issue by distributing the workload and reducing central points of failure. Yet, data and processes spread across different nodes can be at risk of unauthorized access, especially when they involve sensitive information. Nesa solves these challenges with a comprehensive framework using multiple techniques to protect data and model outputs. This includes zero-knowledge proofs for secure model verification. The framework also introduces consensus-based verification checks for consistent outputs across nodes and confirms model integrity. Split Learning divides models into segments processed by different nodes for data privacy by preventing full data access at any single point. For hardware-based security, trusted execution environments are used to protect data and computations within secure zones. Nesa's state-of-the-art proofs and principles demonstrate the framework's effectiveness, making it a promising approach for securely democratizing artificial intelligence.
Read more7/30/2024