MTL-Split: Multi-Task Learning for Edge Devices using Split Computing

0
🌀
Sign in to get full access
Overview
- This paper explores a technique called "Split Computing (SC)" where a Deep Neural Network (DNN) is intelligently divided between an edge device and a remote server.
- This allows powerful DNN models to be used for latency-sensitive applications, while working within the computation constraints of the edge device.
- The paper also examines how to partition a DNN that is being used for multiple tasks (Multi-Task Learning or MTL) within a Split Computing framework.
Plain English Explanation
Split Computing is a way to use powerful Deep Neural Networks (DNNs) for applications that need fast response times, but don't have enough computing power locally. In this approach, part of the DNN runs on the local device, and the rest runs on a more powerful remote server. This lets the application take advantage of the full DNN model, without overloading the local device.
Many embedded systems, like those in cars, also need to do multiple tasks with the same DNN, instead of having separate models for each task. This is called Multi-Task Learning (MTL). However, it's not clear how to best divide up an MTL DNN for Split Computing.
This paper proposes a new architecture called "MTL-Split" that shows promising results for splitting multi-task DNNs between edge and cloud. By intelligently partitioning the DNN, they can leverage the power of MTL while still meeting the constraints of the edge device.
Technical Explanation
The key contribution of this paper is the proposed "MTL-Split" architecture, which extends the idea of Split Computing to DNNs that are trained for multiple inference tasks (Multi-Task Learning).
The authors first provide an overview of related work in Split Computing and Collaborative Edge-Cloud Learning. They then describe the MTL-Split approach:
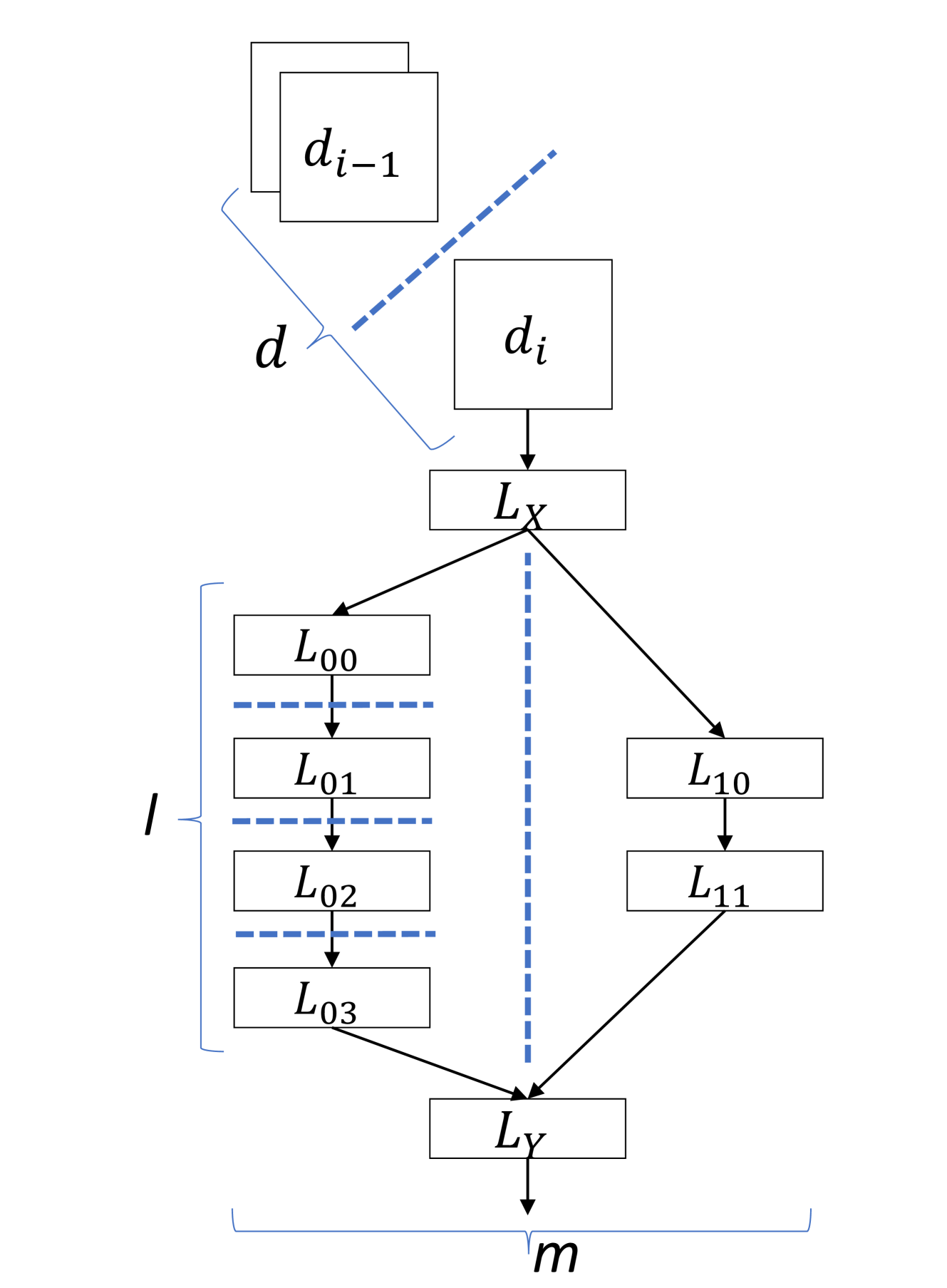
- The DNN is partitioned into two parts - one that runs on the edge device, and one that runs on the remote server.
- The edge part handles the initial layers of the DNN, while the server part handles the later, more computationally expensive layers.
- The authors propose different strategies for partitioning the DNN, such as evenly splitting the layers or adaptively allocating layers based on resource constraints, as explored in AdaptSFL.
- Experiments are conducted on both synthetic and real-world datasets, demonstrating the effectiveness of MTL-Split compared to baselines.
The results show that MTL-Split can maintain high accuracy while significantly reducing the computational burden on the edge device, making it a promising approach for Non-Federated Multi-Task Split Learning in resource-constrained settings like automotive applications.
Critical Analysis
The paper provides a well-designed and thorough exploration of the MTL-Split approach. The authors have considered important factors such as adaptive layer allocation and resource constraints, as seen in related work like AdaptSFL.
However, the paper does not address some potential limitations of the approach. For example, the communication overhead between the edge and server, and the impact of network latency on the overall performance, are not discussed in depth. Additionally, the experiments are limited to specific datasets and tasks, so the generalizability of the results may need further investigation.
It would also be interesting to see how MTL-Split compares to alternative approaches, such as Adaptive Layer Splitting for wireless inference or other distributed learning techniques, in terms of both performance and practical implementation.
Overall, the MTL-Split architecture is a promising step towards enabling powerful DNNs in resource-constrained edge computing environments, and the paper provides a solid foundation for further research in this area.
Conclusion
This paper presents a novel approach called "MTL-Split" that extends the idea of Split Computing to Deep Neural Networks trained for multiple inference tasks (Multi-Task Learning). By intelligently partitioning the DNN between an edge device and a remote server, MTL-Split can leverage the power of DNNs while meeting the computational constraints of the edge.
The results demonstrate the effectiveness of MTL-Split, making it a compelling solution for latency-sensitive, resource-constrained applications like those found in the automotive domain. As edge computing continues to grow in importance, techniques like MTL-Split will be crucial for bringing advanced AI capabilities to the edge in a practical and efficient manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌀
0
MTL-Split: Multi-Task Learning for Edge Devices using Split Computing
Luigi Capogrosso, Enrico Fraccaroli, Samarjit Chakraborty, Franco Fummi, Marco Cristani
Split Computing (SC), where a Deep Neural Network (DNN) is intelligently split with a part of it deployed on an edge device and the rest on a remote server is emerging as a promising approach. It allows the power of DNNs to be leveraged for latency-sensitive applications that do not allow the entire DNN to be deployed remotely, while not having sufficient computation bandwidth available locally. In many such embedded systems scenarios, such as those in the automotive domain, computational resource constraints also necessitate Multi-Task Learning (MTL), where the same DNN is used for multiple inference tasks instead of having dedicated DNNs for each task, which would need more computing bandwidth. However, how to partition such a multi-tasking DNN to be deployed within a SC framework has not been sufficiently studied. This paper studies this problem, and MTL-Split, our novel proposed architecture, shows encouraging results on both synthetic and real-world data. The source code is available at https://github.com/intelligolabs/MTL-Split.
Read more7/9/2024

0
Non-Federated Multi-Task Split Learning for Heterogeneous Sources
Yilin Zheng, Atilla Eryilmaz
With the development of edge networks and mobile computing, the need to serve heterogeneous data sources at the network edge requires the design of new distributed machine learning mechanisms. As a prevalent approach, Federated Learning (FL) employs parameter-sharing and gradient-averaging between clients and a server. Despite its many favorable qualities, such as convergence and data-privacy guarantees, it is well-known that classic FL fails to address the challenge of data heterogeneity and computation heterogeneity across clients. Most existing works that aim to accommodate such sources of heterogeneity stay within the FL operation paradigm, with modifications to overcome the negative effect of heterogeneous data. In this work, as an alternative paradigm, we propose a Multi-Task Split Learning (MTSL) framework, which combines the advantages of Split Learning (SL) with the flexibility of distributed network architectures. In contrast to the FL counterpart, in this paradigm, heterogeneity is not an obstacle to overcome, but a useful property to take advantage of. As such, this work aims to introduce a new architecture and methodology to perform multi-task learning for heterogeneous data sources efficiently, with the hope of encouraging the community to further explore the potential advantages we reveal. To support this promise, we first show through theoretical analysis that MTSL can achieve fast convergence by tuning the learning rate of the server and clients. Then, we compare the performance of MTSL with existing multi-task FL methods numerically on several image classification datasets to show that MTSL has advantages over FL in training speed, communication cost, and robustness to heterogeneous data.
Read more6/4/2024
0
A Survey of Distributed Learning in Cloud, Mobile, and Edge Settings
Madison Threadgill, Andreas Gerstlauer
In the era of deep learning (DL), convolutional neural networks (CNNs), and large language models (LLMs), machine learning (ML) models are becoming increasingly complex, demanding significant computational resources for both inference and training stages. To address this challenge, distributed learning has emerged as a crucial approach, employing parallelization across various devices and environments. This survey explores the landscape of distributed learning, encompassing cloud and edge settings. We delve into the core concepts of data and model parallelism, examining how models are partitioned across different dimensions and layers to optimize resource utilization and performance. We analyze various partitioning schemes for different layer types, including fully connected, convolutional, and recurrent layers, highlighting the trade-offs between computational efficiency, communication overhead, and memory constraints. This survey provides valuable insights for future research and development in this rapidly evolving field by comparing and contrasting distributed learning approaches across diverse contexts.
Read more5/27/2024

0
Enhancing Split Computing and Early Exit Applications through Predefined Sparsity
Luigi Capogrosso, Enrico Fraccaroli, Giulio Petrozziello, Francesco Setti, Samarjit Chakraborty, Franco Fummi, Marco Cristani
In the past decade, Deep Neural Networks (DNNs) achieved state-of-the-art performance in a broad range of problems, spanning from object classification and action recognition to smart building and healthcare. The flexibility that makes DNNs such a pervasive technology comes at a price: the computational requirements preclude their deployment on most of the resource-constrained edge devices available today to solve real-time and real-world tasks. This paper introduces a novel approach to address this challenge by combining the concept of predefined sparsity with Split Computing (SC) and Early Exit (EE). In particular, SC aims at splitting a DNN with a part of it deployed on an edge device and the rest on a remote server. Instead, EE allows the system to stop using the remote server and rely solely on the edge device's computation if the answer is already good enough. Specifically, how to apply such a predefined sparsity to a SC and EE paradigm has never been studied. This paper studies this problem and shows how predefined sparsity significantly reduces the computational, storage, and energy burdens during the training and inference phases, regardless of the hardware platform. This makes it a valuable approach for enhancing the performance of SC and EE applications. Experimental results showcase reductions exceeding 4x in storage and computational complexity without compromising performance. The source code is available at https://github.com/intelligolabs/sparsity_sc_ee.
Read more7/17/2024