Versatile Navigation under Partial Observability via Value-guided Diffusion Policy
2404.02176
0
0
Abstract
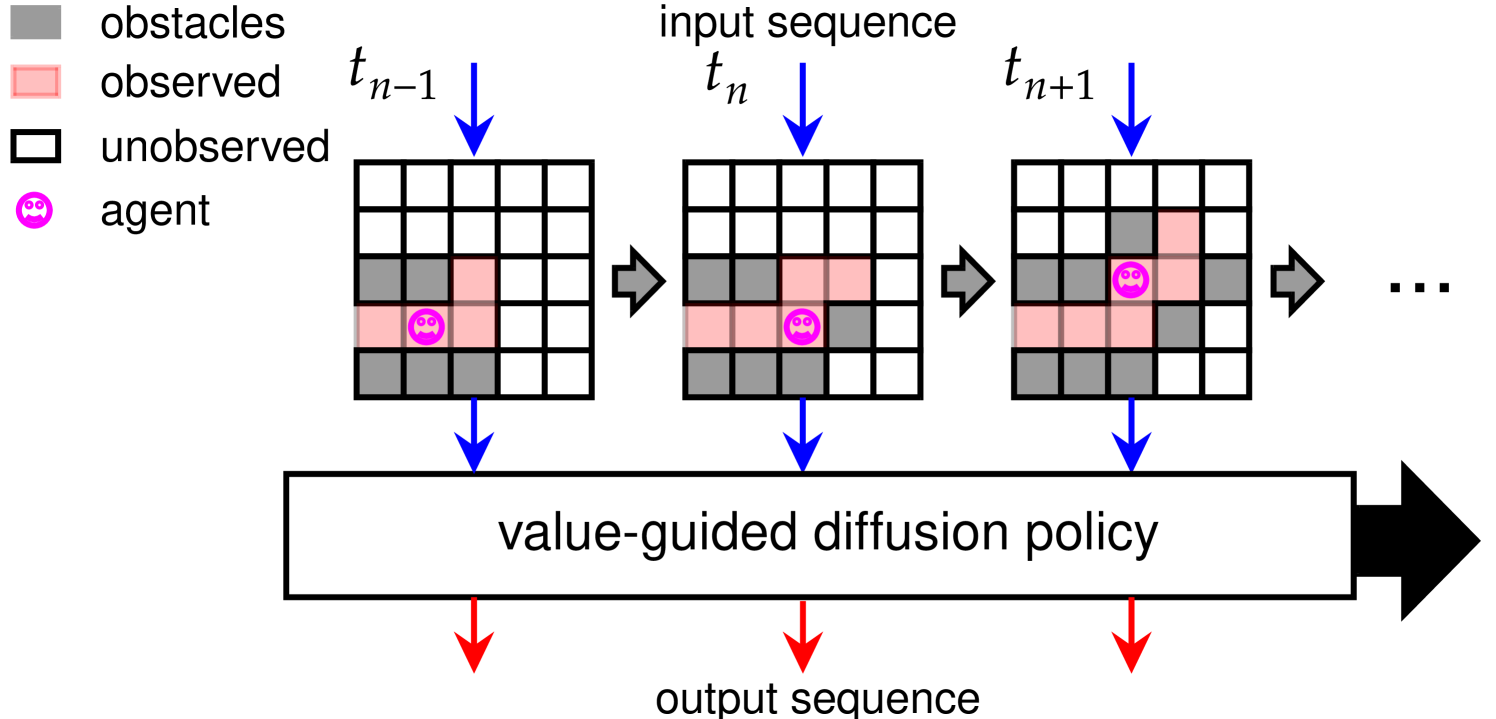
Route planning for navigation under partial observability plays a crucial role in modern robotics and autonomous driving. Existing route planning approaches can be categorized into two main classes: traditional autoregressive and diffusion-based methods. The former often fails due to its myopic nature, while the latter either assumes full observability or struggles to adapt to unfamiliar scenarios, due to strong couplings with behavior cloning from experts. To address these deficiencies, we propose a versatile diffusion-based approach for both 2D and 3D route planning under partial observability. Specifically, our value-guided diffusion policy first generates plans to predict actions across various timesteps, providing ample foresight to the planning. It then employs a differentiable planner with state estimations to derive a value function, directing the agent's exploration and goal-seeking behaviors without seeking experts while explicitly addressing partial observability. During inference, our policy is further enhanced by a best-plan-selection strategy, substantially boosting the planning success rate. Moreover, we propose projecting point clouds, derived from RGB-D inputs, onto 2D grid-based bird-eye-view maps via semantic segmentation, generalizing to 3D environments. This simple yet effective adaption enables zero-shot transfer from 2D-trained policy to 3D, cutting across the laborious training for 3D policy, and thus certifying our versatility. Experimental results demonstrate our superior performance, particularly in navigating situations beyond expert demonstrations, surpassing state-of-the-art autoregressive and diffusion-based baselines for both 2D and 3D scenarios.
Create account to get full access
Overview
- This paper proposes a new approach for navigation in partially observable environments using a technique called "value-guided diffusion policy".
- The method aims to enable versatile navigation, where an agent can effectively navigate and complete various tasks in complex environments with limited information.
- The authors demonstrate the effectiveness of their approach through simulated experiments in challenging environments.
Plain English Explanation
The research paper describes a new way for autonomous agents, like robots or virtual characters, to navigate and explore their surroundings when they don't have complete information about the environment.
Imagine you're trying to find your way through a maze, but you can only see a small area around you at any given time. This is the kind of partially observable environment the paper is addressing. The proposed technique allows the agent to efficiently explore the maze and find its way to the goal, even when it can't see the full layout upfront.
The key idea is to guide the agent's exploration using a "value-guided diffusion policy". This means the agent doesn't just randomly wander, but instead uses an internal evaluation of the potential value or usefulness of different areas to decide where to go next. It "diffuses" or spreads out in the most promising directions, focusing its search on the most rewarding paths.
By incorporating this value-guided exploration, the agent can navigate versatilely - it can handle a variety of tasks and environments, not just a single predetermined route. This makes the approach more flexible and practical for real-world applications like autonomous robots or video game characters.
Technical Explanation
The paper introduces a novel framework called "Value-Guided Diffusion Policy" (VGDP) for navigation in partially observable environments. The key components are:
-
Belief State Representation: The agent maintains a probabilistic belief state about the unobserved parts of the environment, which is updated as new observations are made.
-
Value Network: A deep neural network is trained to estimate the expected future reward (value) of being in different belief states. This value function guides the agent's exploration.
-
Diffusion Policy: Based on the value estimates, the agent "diffuses" its exploration by sampling actions that spread out in promising directions, rather than just greedily following the maximum value.
The authors evaluate VGDP in simulated environments with varying degrees of partial observability. The results show VGDP outperforms alternative approaches in terms of navigation efficiency and task completion rates, demonstrating its versatility in handling diverse challenges.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the VGDP approach, exploring its performance across a range of partially observable environments. The authors acknowledge limitations, such as the sensitivity of the method to the accuracy of the value network, and suggest directions for future work to address these issues.
One potential concern is the reliance on simulated environments, which may not fully capture the complexities of real-world navigation challenges. Evaluating the approach on physical robotic platforms or in more realistic virtual environments could provide further insights into its practical applicability.
Additionally, the paper does not deeply discuss the interpretability or explainability of the VGDP framework. As autonomous systems become more prevalent, there is a growing emphasis on understanding the decision-making processes of these agents, which could be an interesting area for future research.
Conclusion
The "Value-Guided Diffusion Policy" proposed in this paper represents a promising approach for enabling versatile navigation in partially observable environments. By combining a probabilistic belief state representation, a value-based exploration strategy, and a diffusion-based policy, the method allows agents to efficiently explore and complete tasks in complex settings with limited information.
The demonstrated performance improvements over alternative techniques suggest that this framework could have significant implications for the development of autonomous systems, such as robots or virtual characters, that need to navigate and interact with their surroundings in a flexible and adaptive manner. Further research to address the identified limitations and explore real-world applications could help unlock the full potential of this innovative approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔍
CGD: Constraint-Guided Diffusion Policies for UAV Trajectory Planning
Kota Kondo, Andrea Tagliabue, Xiaoyi Cai, Claudius Tewari, Olivia Garcia, Marcos Espitia-Alvarez, Jonathan P. How
0
0
Traditional optimization-based planners, while effective, suffer from high computational costs, resulting in slow trajectory generation. A successful strategy to reduce computation time involves using Imitation Learning (IL) to develop fast neural network (NN) policies from those planners, which are treated as expert demonstrators. Although the resulting NN policies are effective at quickly generating trajectories similar to those from the expert, (1) their output does not explicitly account for dynamic feasibility, and (2) the policies do not accommodate changes in the constraints different from those used during training. To overcome these limitations, we propose Constraint-Guided Diffusion (CGD), a novel IL-based approach to trajectory planning. CGD leverages a hybrid learning/online optimization scheme that combines diffusion policies with a surrogate efficient optimization problem, enabling the generation of collision-free, dynamically feasible trajectories. The key ideas of CGD include dividing the original challenging optimization problem solved by the expert into two more manageable sub-problems: (a) efficiently finding collision-free paths, and (b) determining a dynamically-feasible time-parametrization for those paths to obtain a trajectory. Compared to conventional neural network architectures, we demonstrate through numerical evaluations significant improvements in performance and dynamic feasibility under scenarios with new constraints never encountered during training.
5/6/2024
3D Diffusion Policy: Generalizable Visuomotor Policy Learning via Simple 3D Representations
Yanjie Ze, Gu Zhang, Kangning Zhang, Chenyuan Hu, Muhan Wang, Huazhe Xu
0
0
Imitation learning provides an efficient way to teach robots dexterous skills; however, learning complex skills robustly and generalizablely usually consumes large amounts of human demonstrations. To tackle this challenging problem, we present 3D Diffusion Policy (DP3), a novel visual imitation learning approach that incorporates the power of 3D visual representations into diffusion policies, a class of conditional action generative models. The core design of DP3 is the utilization of a compact 3D visual representation, extracted from sparse point clouds with an efficient point encoder. In our experiments involving 72 simulation tasks, DP3 successfully handles most tasks with just 10 demonstrations and surpasses baselines with a 24.2% relative improvement. In 4 real robot tasks, DP3 demonstrates precise control with a high success rate of 85%, given only 40 demonstrations of each task, and shows excellent generalization abilities in diverse aspects, including space, viewpoint, appearance, and instance. Interestingly, in real robot experiments, DP3 rarely violates safety requirements, in contrast to baseline methods which frequently do, necessitating human intervention. Our extensive evaluation highlights the critical importance of 3D representations in real-world robot learning. Videos, code, and data are available on https://3d-diffusion-policy.github.io .
5/29/2024
Policy-Guided Diffusion
Matthew Thomas Jackson, Michael Tryfan Matthews, Cong Lu, Benjamin Ellis, Shimon Whiteson, Jakob Foerster
0
0
In many real-world settings, agents must learn from an offline dataset gathered by some prior behavior policy. Such a setting naturally leads to distribution shift between the behavior policy and the target policy being trained - requiring policy conservatism to avoid instability and overestimation bias. Autoregressive world models offer a different solution to this by generating synthetic, on-policy experience. However, in practice, model rollouts must be severely truncated to avoid compounding error. As an alternative, we propose policy-guided diffusion. Our method uses diffusion models to generate entire trajectories under the behavior distribution, applying guidance from the target policy to move synthetic experience further on-policy. We show that policy-guided diffusion models a regularized form of the target distribution that balances action likelihood under both the target and behavior policies, leading to plausible trajectories with high target policy probability, while retaining a lower dynamics error than an offline world model baseline. Using synthetic experience from policy-guided diffusion as a drop-in substitute for real data, we demonstrate significant improvements in performance across a range of standard offline reinforcement learning algorithms and environments. Our approach provides an effective alternative to autoregressive offline world models, opening the door to the controllable generation of synthetic training data.
4/10/2024

Versatile Scene-Consistent Traffic Scenario Generation as Optimization with Diffusion
Zhiyu Huang, Zixu Zhang, Ameya Vaidya, Yuxiao Chen, Chen Lv, Jaime Fern'andez Fisac
0
0
Generating realistic and controllable agent behaviors in traffic simulation is crucial for the development of autonomous vehicles. This problem is often formulated as imitation learning (IL) from real-world driving data by either directly predicting future trajectories or inferring cost functions with inverse optimal control. In this paper, we draw a conceptual connection between IL and diffusion-based generative modeling and introduce a novel framework Versatile Behavior Diffusion (VBD) to simulate interactive scenarios with multiple traffic participants. Our model not only generates scene-consistent multi-agent interactions but also enables scenario editing through multi-step guidance and refinement. Experimental evaluations show that VBD achieves state-of-the-art performance on the Waymo Sim Agents benchmark. In addition, we illustrate the versatility of our model by adapting it to various applications. VBD is capable of producing scenarios conditioning on priors, integrating with model-based optimization, sampling multi-modal scene-consistent scenarios by fusing marginal predictions, and generating safety-critical scenarios when combined with a game-theoretic solver.
4/4/2024