VFusion3D: Learning Scalable 3D Generative Models from Video Diffusion Models

0

Sign in to get full access
Overview
- This paper presents "VFusion3D", a method for learning scalable 3D generative models from video diffusion models.
- The key idea is to distill 3D information from 2D video diffusion models, enabling the generation of high-quality 3D content.
- The approach combines 2D and 3D representations to achieve high-fidelity 3D generation that scales to complex scenes.
Plain English Explanation
The paper introduces a new technique called VFusion3D that can generate 3D content by learning from 2D video diffusion models. Diffusion models are a type of AI that can create new images by gradually adding and then removing "noise" from an initial image.
The researchers realized that these 2D diffusion models, while powerful for generating 2D images, could also contain useful 3D information hidden within the 2D frames. By distilling this 3D information, they were able to create a system that can generate high-quality 3D content, including complex 3D scenes.
The key insight is that combining the 2D and 3D representations allows the system to leverage the best of both worlds - the scalability and flexibility of 2D diffusion models, and the depth and realism of 3D content. This enables the generation of 3D scenes that are more detailed and realistic than what was possible before.
Technical Explanation
The paper introduces the VFusion3D framework, which learns to generate 3D content by distilling information from 2D video diffusion models. The approach combines 2D and 3D representations to achieve high-fidelity 3D generation that scales to complex scenes.
Specifically, the framework consists of two key components:
-
Video-to-3D Distillation: This module takes a pre-trained 2D video diffusion model and distills the 3D information hidden within the 2D video frames. This allows the system to leverage the scalability and flexibility of the 2D model while extracting the necessary 3D cues.
-
3D Fusion Generator: This module fuses the distilled 3D information with the 2D video representation to generate the final 3D content. By combining these complementary representations, the system can generate high-quality 3D scenes with a level of detail and realism that exceeds previous methods.
The paper demonstrates the effectiveness of VFusion3D through extensive experiments on several 3D generation benchmarks. The results show that the approach outperforms state-of-the-art methods in terms of both visual quality and scalability to complex scenes.
Critical Analysis
The paper makes a compelling case for the VFusion3D approach, but there are a few potential limitations and areas for further research:
-
Dependency on Pre-Trained Models: The framework relies on a pre-trained 2D video diffusion model, which may limit its flexibility and applicability to domains where such models are not readily available.
-
Generalization to Diverse Scenes: While the experiments demonstrate strong performance on the tested benchmarks, it would be valuable to further evaluate the system's ability to generate diverse 3D scenes, including those with complex shapes, textures, and lighting conditions.
-
Real-World Applications: The paper focuses on benchmarks and does not explore the potential real-world applications of the VFusion3D framework, such as in areas like video game development, virtual reality, or 3D printing.
Overall, the VFusion3D approach represents a promising step forward in the field of 3D content generation, and the researchers have identified several avenues for future work to further improve the system's capabilities and explore its practical applications.
Conclusion
The VFusion3D framework presented in this paper demonstrates a novel approach to generating high-quality 3D content by distilling 3D information from pre-trained 2D video diffusion models. By combining 2D and 3D representations, the system is able to leverage the scalability and flexibility of 2D models while producing 3D content with a high level of detail and realism.
The key contribution of this work is the introduction of a novel 3D generation method that has the potential to significantly impact fields such as video game development, virtual reality, and 3D printing, where the ability to create compelling 3D content is of paramount importance. As the researchers continue to refine and expand the VFusion3D framework, it will be exciting to see how it evolves and the new applications it enables.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
VFusion3D: Learning Scalable 3D Generative Models from Video Diffusion Models
Junlin Han, Filippos Kokkinos, Philip Torr
This paper presents a novel method for building scalable 3D generative models utilizing pre-trained video diffusion models. The primary obstacle in developing foundation 3D generative models is the limited availability of 3D data. Unlike images, texts, or videos, 3D data are not readily accessible and are difficult to acquire. This results in a significant disparity in scale compared to the vast quantities of other types of data. To address this issue, we propose using a video diffusion model, trained with extensive volumes of text, images, and videos, as a knowledge source for 3D data. By unlocking its multi-view generative capabilities through fine-tuning, we generate a large-scale synthetic multi-view dataset to train a feed-forward 3D generative model. The proposed model, VFusion3D, trained on nearly 3M synthetic multi-view data, can generate a 3D asset from a single image in seconds and achieves superior performance when compared to current SOTA feed-forward 3D generative models, with users preferring our results over 90% of the time.
Read more7/22/2024

0
Hi3D: Pursuing High-Resolution Image-to-3D Generation with Video Diffusion Models
Haibo Yang, Yang Chen, Yingwei Pan, Ting Yao, Zhineng Chen, Chong-Wah Ngo, Tao Mei
Despite having tremendous progress in image-to-3D generation, existing methods still struggle to produce multi-view consistent images with high-resolution textures in detail, especially in the paradigm of 2D diffusion that lacks 3D awareness. In this work, we present High-resolution Image-to-3D model (Hi3D), a new video diffusion based paradigm that redefines a single image to multi-view images as 3D-aware sequential image generation (i.e., orbital video generation). This methodology delves into the underlying temporal consistency knowledge in video diffusion model that generalizes well to geometry consistency across multiple views in 3D generation. Technically, Hi3D first empowers the pre-trained video diffusion model with 3D-aware prior (camera pose condition), yielding multi-view images with low-resolution texture details. A 3D-aware video-to-video refiner is learnt to further scale up the multi-view images with high-resolution texture details. Such high-resolution multi-view images are further augmented with novel views through 3D Gaussian Splatting, which are finally leveraged to obtain high-fidelity meshes via 3D reconstruction. Extensive experiments on both novel view synthesis and single view reconstruction demonstrate that our Hi3D manages to produce superior multi-view consistency images with highly-detailed textures. Source code and data are available at url{https://github.com/yanghb22-fdu/Hi3D-Official}.
Read more9/12/2024
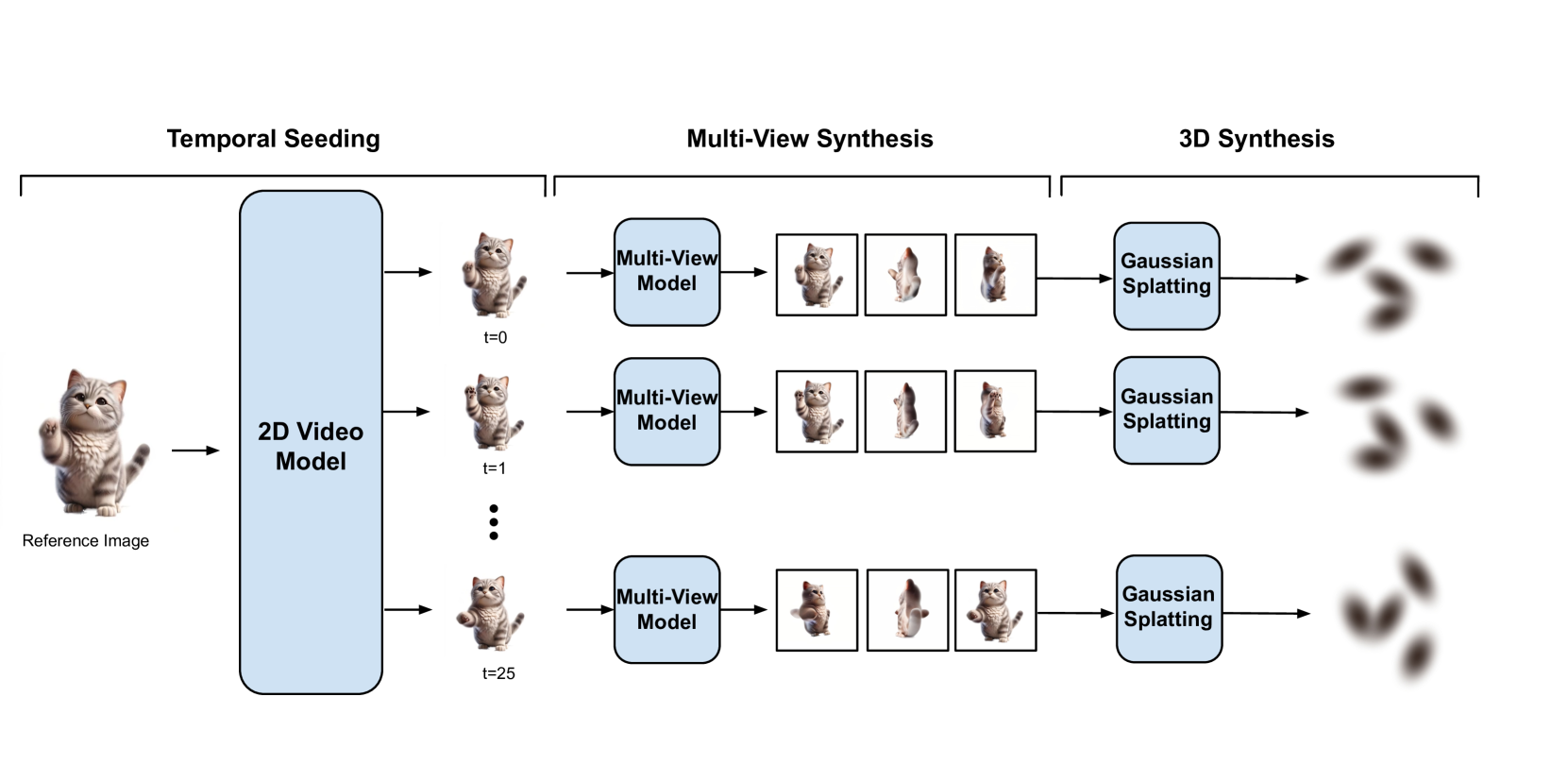
0
Vid3D: Synthesis of Dynamic 3D Scenes using 2D Video Diffusion
Rishab Parthasarathy, Zachary Ankner, Aaron Gokaslan
A recent frontier in computer vision has been the task of 3D video generation, which consists of generating a time-varying 3D representation of a scene. To generate dynamic 3D scenes, current methods explicitly model 3D temporal dynamics by jointly optimizing for consistency across both time and views of the scene. In this paper, we instead investigate whether it is necessary to explicitly enforce multiview consistency over time, as current approaches do, or if it is sufficient for a model to generate 3D representations of each timestep independently. We hence propose a model, Vid3D, that leverages 2D video diffusion to generate 3D videos by first generating a 2D seed of the video's temporal dynamics and then independently generating a 3D representation for each timestep in the seed video. We evaluate Vid3D against two state-of-the-art 3D video generation methods and find that Vid3D is achieves comparable results despite not explicitly modeling 3D temporal dynamics. We further ablate how the quality of Vid3D depends on the number of views generated per frame. While we observe some degradation with fewer views, performance degradation remains minor. Our results thus suggest that 3D temporal knowledge may not be necessary to generate high-quality dynamic 3D scenes, potentially enabling simpler generative algorithms for this task.
Read more8/1/2024

0
3D-VirtFusion: Synthetic 3D Data Augmentation through Generative Diffusion Models and Controllable Editing
Shichao Dong, Ze Yang, Guosheng Lin
Data augmentation plays a crucial role in deep learning, enhancing the generalization and robustness of learning-based models. Standard approaches involve simple transformations like rotations and flips for generating extra data. However, these augmentations are limited by their initial dataset, lacking high-level diversity. Recently, large models such as language models and diffusion models have shown exceptional capabilities in perception and content generation. In this work, we propose a new paradigm to automatically generate 3D labeled training data by harnessing the power of pretrained large foundation models. For each target semantic class, we first generate 2D images of a single object in various structure and appearance via diffusion models and chatGPT generated text prompts. Beyond texture augmentation, we propose a method to automatically alter the shape of objects within 2D images. Subsequently, we transform these augmented images into 3D objects and construct virtual scenes by random composition. This method can automatically produce a substantial amount of 3D scene data without the need of real data, providing significant benefits in addressing few-shot learning challenges and mitigating long-tailed class imbalances. By providing a flexible augmentation approach, our work contributes to enhancing 3D data diversity and advancing model capabilities in scene understanding tasks.
Read more8/27/2024