Video Object Segmentation via SAM 2: The 4th Solution for LSVOS Challenge VOS Track

0

Sign in to get full access
Overview
- The paper presents a video object segmentation method using the Segment Anything Model (SAM) 2, which was the 4th place solution in the LSVOS Challenge VOS track.
- It explains the key components of the proposed approach, including frame-level segmentation, temporal propagation, and post-processing.
- The method demonstrates strong performance on the LSVOS benchmark, highlighting the potential of the SAM 2 model for video object segmentation tasks.
Plain English Explanation
The research paper describes a new way to automatically identify and outline objects in video footage. It uses a powerful AI model called the Segment Anything Model (SAM) 2, which was the 4th best performing approach in a recent video object segmentation competition.
The key steps of the method are:
- Applying the SAM 2 model to each individual video frame to generate initial object segmentations.
- Propagating those segmentations across frames over time to maintain object tracking.
- Performing some additional post-processing to refine the final video object segmentation results.
By leveraging the advanced capabilities of the SAM 2 model, the researchers were able to achieve strong performance on the LSVOS benchmark, which is a widely used dataset for evaluating video object segmentation algorithms. This suggests the SAM 2 model could be a powerful tool for various video analysis and editing applications.
Technical Explanation
The paper presents a video object segmentation pipeline that uses the Segment Anything Model (SAM) 2 as the core component. The key steps of the method are:
-
Frame-Level Segmentation: The SAM 2 model is applied to each individual video frame to generate initial object segmentations. This provides a per-frame set of object masks.
-
Temporal Propagation: The per-frame object segmentations are then propagated across the video sequence using a temporal tracking algorithm. This maintains object identities over time and generates a sequence of segmentation masks for each detected object.
-
Post-Processing: Finally, some additional post-processing steps are performed, such as mask refinement and removal of small/noisy object detections, to produce the final video object segmentation results.
The authors evaluate their method on the LSVOS benchmark, which is a challenging video object segmentation dataset. Their approach achieved the 4th best performance among all submitted solutions, demonstrating the strong capabilities of the SAM 2 model for this task.
Critical Analysis
The paper provides a solid technical explanation of the proposed video object segmentation method and its strong performance on the LSVOS benchmark. However, a few potential limitations or areas for further research are worth noting:
-
The reliance on the SAM 2 model means the method's performance is inherently tied to the capabilities of that underlying model. As the SAM 2 model is further improved, the video segmentation approach could potentially see even better results.
-
The paper does not provide a detailed analysis of the computational efficiency or real-time performance of the proposed pipeline. For many video applications, such as autonomous driving or augmented reality, low-latency processing is crucial.
-
The evaluation is limited to the LSVOS dataset, which, while challenging, may not capture the full diversity of real-world video object segmentation scenarios. Assessing the method's generalization to a broader range of video content could be an area for future research.
-
The authors do not discuss potential biases or failure modes of the SAM 2 model, and how those might impact the overall video segmentation results. Understanding the robustness and limitations of the underlying model is important for real-world deployments.
Despite these potential areas for further investigation, the paper presents a compelling approach that leverages the impressive capabilities of the Segment Anything Model for video object segmentation, with promising results on a widely used benchmark.
Conclusion
The research paper introduces a video object segmentation method that utilizes the Segment Anything Model (SAM) 2 as its core component. By applying the SAM 2 model to individual video frames, propagating the segmentations over time, and performing targeted post-processing, the authors were able to achieve the 4th best performance on the LSVOS benchmark.
This work highlights the potential of the SAM 2 model for various video analysis and editing tasks, beyond just static image segmentation. As the SAM 2 model and related techniques continue to evolve, we may see increasingly powerful and versatile video object segmentation solutions emerge, with applications in areas like autonomous driving, video surveillance, and creative media production.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Video Object Segmentation via SAM 2: The 4th Solution for LSVOS Challenge VOS Track
Feiyu Pan, Hao Fang, Runmin Cong, Wei Zhang, Xiankai Lu
Video Object Segmentation (VOS) task aims to segmenting a particular object instance throughout the entire video sequence given only the object mask of the first frame. Recently, Segment Anything Model 2 (SAM 2) is proposed, which is a foundation model towards solving promptable visual segmentation in images and videos. SAM 2 builds a data engine, which improves model and data via user interaction, to collect the largest video segmentation dataset to date. SAM 2 is a simple transformer architecture with streaming memory for real-time video processing, which trained on the date provides strong performance across a wide range of tasks. In this work, we evaluate the zero-shot performance of SAM 2 on the more challenging VOS datasets MOSE and LVOS. Without fine-tuning on the training set, SAM 2 achieved 75.79 J&F on the test set and ranked 4th place for 6th LSVOS Challenge VOS Track.
Read more8/27/2024

0
LSVOS Challenge 3rd Place Report: SAM2 and Cutie based VOS
Xinyu Liu, Jing Zhang, Kexin Zhang, Xu Liu, Lingling Li
Video Object Segmentation (VOS) presents several challenges, including object occlusion and fragmentation, the dis-appearance and re-appearance of objects, and tracking specific objects within crowded scenes. In this work, we combine the strengths of the state-of-the-art (SOTA) models SAM2 and Cutie to address these challenges. Additionally, we explore the impact of various hyperparameters on video instance segmentation performance. Our approach achieves a J&F score of 0.7952 in the testing phase of LSVOS challenge VOS track, ranking third overall.
Read more8/22/2024
📈
0
Zero-Shot Surgical Tool Segmentation in Monocular Video Using Segment Anything Model 2
Ange Lou, Yamin Li, Yike Zhang, Robert F. Labadie, Jack Noble
The Segment Anything Model 2 (SAM 2) is the latest generation foundation model for image and video segmentation. Trained on the expansive Segment Anything Video (SA-V) dataset, which comprises 35.5 million masks across 50.9K videos, SAM 2 advances its predecessor's capabilities by supporting zero-shot segmentation through various prompts (e.g., points, boxes, and masks). Its robust zero-shot performance and efficient memory usage make SAM 2 particularly appealing for surgical tool segmentation in videos, especially given the scarcity of labeled data and the diversity of surgical procedures. In this study, we evaluate the zero-shot video segmentation performance of the SAM 2 model across different types of surgeries, including endoscopy and microscopy. We also assess its performance on videos featuring single and multiple tools of varying lengths to demonstrate SAM 2's applicability and effectiveness in the surgical domain. We found that: 1) SAM 2 demonstrates a strong capability for segmenting various surgical videos; 2) When new tools enter the scene, additional prompts are necessary to maintain segmentation accuracy; and 3) Specific challenges inherent to surgical videos can impact the robustness of SAM 2.
Read more8/6/2024
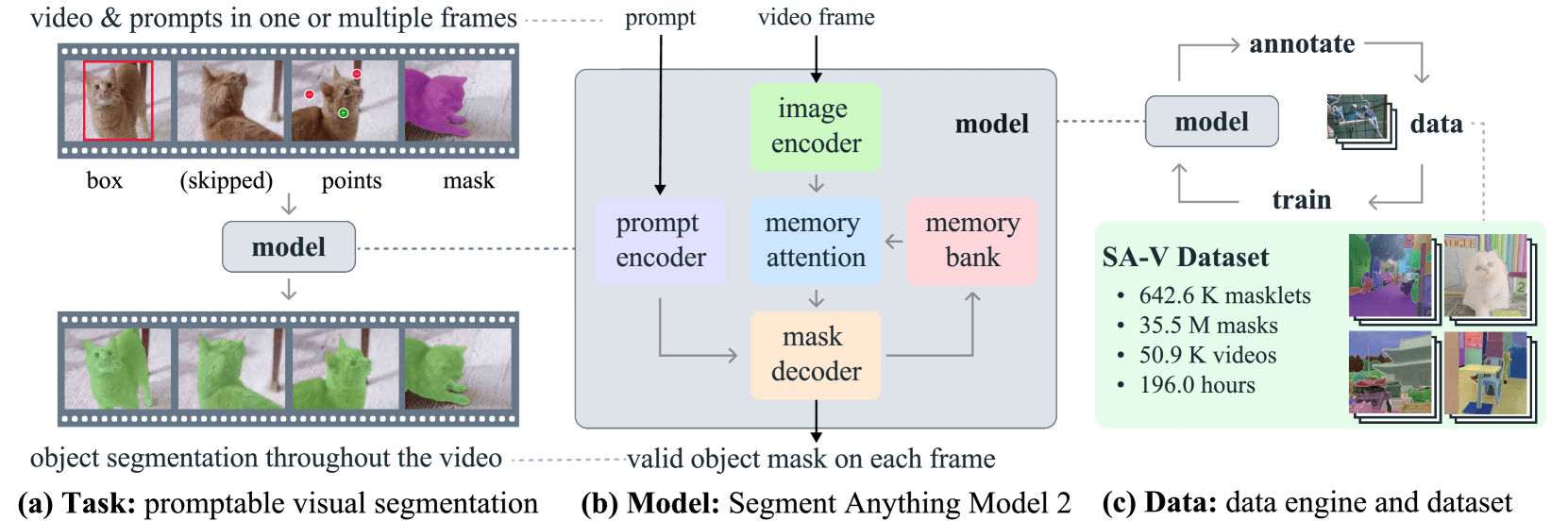
0
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Radle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Doll'ar, Christoph Feichtenhofer
We present Segment Anything Model 2 (SAM 2), a foundation model towards solving promptable visual segmentation in images and videos. We build a data engine, which improves model and data via user interaction, to collect the largest video segmentation dataset to date. Our model is a simple transformer architecture with streaming memory for real-time video processing. SAM 2 trained on our data provides strong performance across a wide range of tasks. In video segmentation, we observe better accuracy, using 3x fewer interactions than prior approaches. In image segmentation, our model is more accurate and 6x faster than the Segment Anything Model (SAM). We believe that our data, model, and insights will serve as a significant milestone for video segmentation and related perception tasks. We are releasing a version of our model, the dataset and an interactive demo.
Read more8/2/2024