VidMuse: A Simple Video-to-Music Generation Framework with Long-Short-Term Modeling
2406.04321
0
0
Abstract
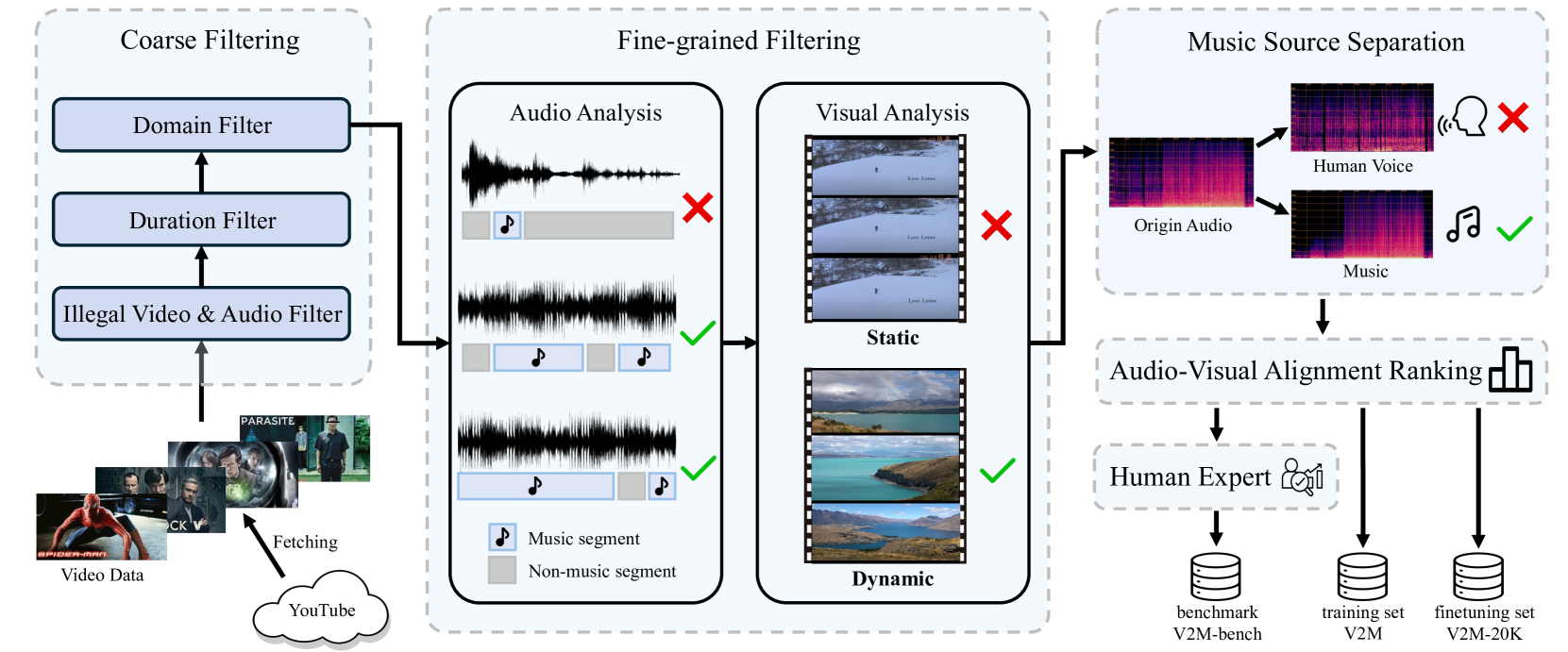
In this work, we systematically study music generation conditioned solely on the video. First, we present a large-scale dataset comprising 190K video-music pairs, including various genres such as movie trailers, advertisements, and documentaries. Furthermore, we propose VidMuse, a simple framework for generating music aligned with video inputs. VidMuse stands out by producing high-fidelity music that is both acoustically and semantically aligned with the video. By incorporating local and global visual cues, VidMuse enables the creation of musically coherent audio tracks that consistently match the video content through Long-Short-Term modeling. Through extensive experiments, VidMuse outperforms existing models in terms of audio quality, diversity, and audio-visual alignment. The code and datasets will be available at https://github.com/ZeyueT/VidMuse/.
Create account to get full access
Overview
• The paper presents "VidMuse", a framework for generating music from video input using long-short-term modeling. • The framework aims to create music that is semantically consistent with the video content. • It builds upon previous work on semantically-consistent video-to-audio generation and music recommendation from videos.
Plain English Explanation
The paper describes a new system called "VidMuse" that can automatically generate music to go along with a video. The key idea is to use long-term and short-term patterns in the video to create music that fits the content. For example, if the video shows a person walking through a forest, the system would try to generate music that sounds "forest-like" and matches the pace of the person's movements.
This builds on previous research that has looked at generating audio from video or recommending music to go with a video. The authors argue that their approach, which models both short-term and long-term dependencies in the video, can produce music that is more semantically consistent with the video content compared to prior methods.
Technical Explanation
The VidMuse framework uses a multi-stage architecture to generate music from video input. First, it extracts visual and audio features from the video using pre-trained neural networks. These features are then fed into a long-short-term memory (LSTM) model, which is trained to learn the temporal dependencies in the video.
The LSTM model outputs a sequence of latent representations that capture both the short-term and long-term structure of the video. These latent representations are then passed to a music generation module, which uses a conditional variational autoencoder to produce the final music output.
The authors evaluate VidMuse on the NES Video-Music Database, a dataset of videos and corresponding music, as well as on a new dataset of user-created video-music pairs. They show that VidMuse outperforms previous approaches in terms of semantic consistency between the generated music and the video content.
Critical Analysis
The VidMuse framework represents a promising step forward in the field of video-to-music generation. By explicitly modeling both short-term and long-term dependencies in the video, the system is able to generate music that is more closely aligned with the semantic content of the video compared to prior methods.
However, the paper does not address some potential limitations of the approach. For example, the authors do not discuss how well VidMuse would perform on a diverse range of video genres and styles, or how it might handle videos with complex or ambiguous semantic content.
Additionally, the paper only evaluates the system on relatively short video clips, and it is unclear how well the approach would scale to longer, more complex video sequences. Further research may be needed to explore the robustness and scalability of the VidMuse framework.
Conclusion
The VidMuse paper presents a novel framework for generating music that is semantically consistent with video content. By modeling both short-term and long-term patterns in the video, the system is able to produce music that better aligns with the visual and narrative elements of the input.
While the approach shows promising results, there are still open questions and areas for further research, such as the system's performance on diverse video genres and its ability to handle longer, more complex video sequences. Overall, the VidMuse framework represents an interesting step forward in the field of video-to-music generation and could have applications in areas like video production, interactive entertainment, and multimedia art.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Semantically consistent Video-to-Audio Generation using Multimodal Language Large Model
Gehui Chen, Guan'an Wang, Xiaowen Huang, Jitao Sang
0
0
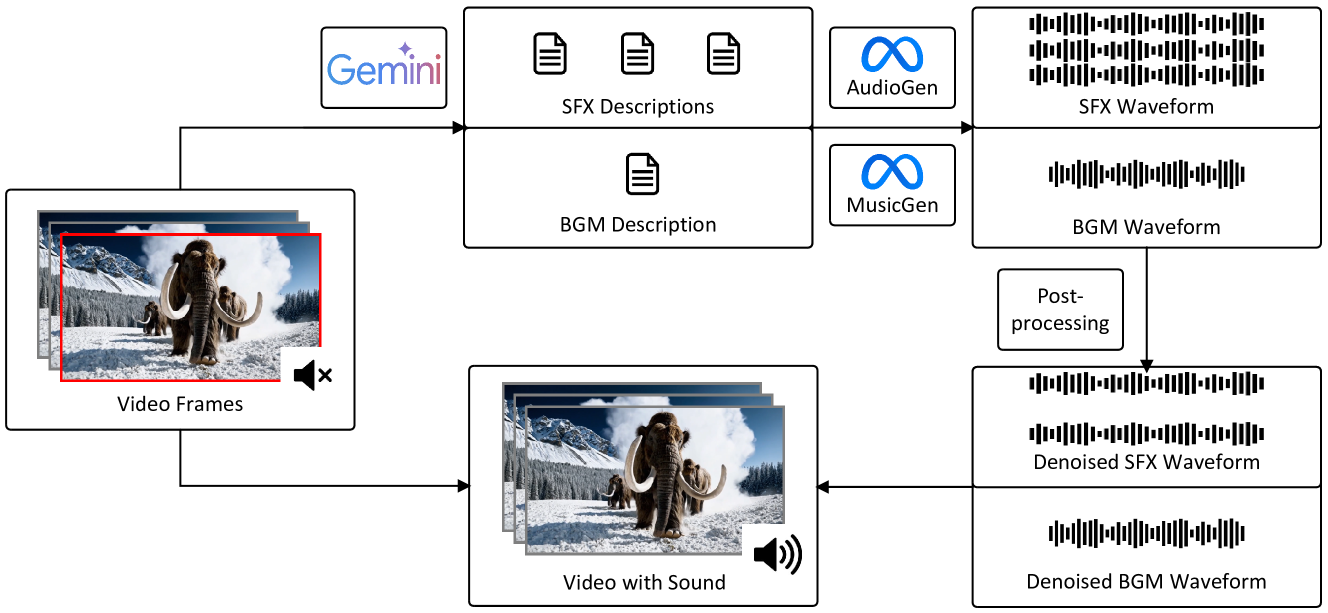
Existing works have made strides in video generation, but the lack of sound effects (SFX) and background music (BGM) hinders a complete and immersive viewer experience. We introduce a novel semantically consistent v ideo-to-audio generation framework, namely SVA, which automatically generates audio semantically consistent with the given video content. The framework harnesses the power of multimodal large language model (MLLM) to understand video semantics from a key frame and generate creative audio schemes, which are then utilized as prompts for text-to-audio models, resulting in video-to-audio generation with natural language as an interface. We show the satisfactory performance of SVA through case study and discuss the limitations along with the future research direction. The project page is available at https://huiz-a.github.io/audio4video.github.io/.
4/29/2024

MeLFusion: Synthesizing Music from Image and Language Cues using Diffusion Models
Sanjoy Chowdhury, Sayan Nag, K J Joseph, Balaji Vasan Srinivasan, Dinesh Manocha
0
0
Music is a universal language that can communicate emotions and feelings. It forms an essential part of the whole spectrum of creative media, ranging from movies to social media posts. Machine learning models that can synthesize music are predominantly conditioned on textual descriptions of it. Inspired by how musicians compose music not just from a movie script, but also through visualizations, we propose MeLFusion, a model that can effectively use cues from a textual description and the corresponding image to synthesize music. MeLFusion is a text-to-music diffusion model with a novel visual synapse, which effectively infuses the semantics from the visual modality into the generated music. To facilitate research in this area, we introduce a new dataset MeLBench, and propose a new evaluation metric IMSM. Our exhaustive experimental evaluation suggests that adding visual information to the music synthesis pipeline significantly improves the quality of generated music, measured both objectively and subjectively, with a relative gain of up to 67.98% on the FAD score. We hope that our work will gather attention to this pragmatic, yet relatively under-explored research area.
6/10/2024

MVBIND: Self-Supervised Music Recommendation For Videos Via Embedding Space Binding
Jiajie Teng, Huiyu Duan, Yucheng Zhu, Sijing Wu, Guangtao Zhai
0
0
Recent years have witnessed the rapid development of short videos, which usually contain both visual and audio modalities. Background music is important to the short videos, which can significantly influence the emotions of the viewers. However, at present, the background music of short videos is generally chosen by the video producer, and there is a lack of automatic music recommendation methods for short videos. This paper introduces MVBind, an innovative Music-Video embedding space Binding model for cross-modal retrieval. MVBind operates as a self-supervised approach, acquiring inherent knowledge of intermodal relationships directly from data, without the need of manual annotations. Additionally, to compensate the lack of a corresponding musical-visual pair dataset for short videos, we construct a dataset, SVM-10K(Short Video with Music-10K), which mainly consists of meticulously selected short videos. On this dataset, MVBind manifests significantly improved performance compared to other baseline methods. The constructed dataset and code will be released to facilitate future research.
5/16/2024
The NES Video-Music Database: A Dataset of Symbolic Video Game Music Paired with Gameplay Videos
Igor Cardoso, Rubens O. Moraes, Lucas N. Ferreira
0
0
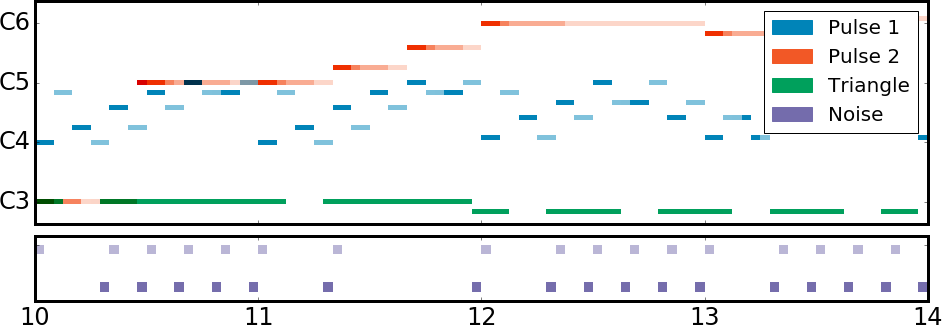
Neural models are one of the most popular approaches for music generation, yet there aren't standard large datasets tailored for learning music directly from game data. To address this research gap, we introduce a novel dataset named NES-VMDB, containing 98,940 gameplay videos from 389 NES games, each paired with its original soundtrack in symbolic format (MIDI). NES-VMDB is built upon the Nintendo Entertainment System Music Database (NES-MDB), encompassing 5,278 music pieces from 397 NES games. Our approach involves collecting long-play videos for 389 games of the original dataset, slicing them into 15-second-long clips, and extracting the audio from each clip. Subsequently, we apply an audio fingerprinting algorithm (similar to Shazam) to automatically identify the corresponding piece in the NES-MDB dataset. Additionally, we introduce a baseline method based on the Controllable Music Transformer to generate NES music conditioned on gameplay clips. We evaluated this approach with objective metrics, and the results showed that the conditional CMT improves musical structural quality when compared to its unconditional counterpart. Moreover, we used a neural classifier to predict the game genre of the generated pieces. Results showed that the CMT generator can learn correlations between gameplay videos and game genres, but further research has to be conducted to achieve human-level performance.
4/9/2024