MVBIND: Self-Supervised Music Recommendation For Videos Via Embedding Space Binding
2405.09286
0
0

Abstract
Recent years have witnessed the rapid development of short videos, which usually contain both visual and audio modalities. Background music is important to the short videos, which can significantly influence the emotions of the viewers. However, at present, the background music of short videos is generally chosen by the video producer, and there is a lack of automatic music recommendation methods for short videos. This paper introduces MVBind, an innovative Music-Video embedding space Binding model for cross-modal retrieval. MVBind operates as a self-supervised approach, acquiring inherent knowledge of intermodal relationships directly from data, without the need of manual annotations. Additionally, to compensate the lack of a corresponding musical-visual pair dataset for short videos, we construct a dataset, SVM-10K(Short Video with Music-10K), which mainly consists of meticulously selected short videos. On this dataset, MVBind manifests significantly improved performance compared to other baseline methods. The constructed dataset and code will be released to facilitate future research.
Create account to get full access
Overview
- This paper presents MVBIND, a self-supervised learning approach for cross-modal music recommendation in short videos.
- The key idea is to jointly learn music and video embeddings by "binding" them in a shared latent space, allowing the model to recommend music that matches the semantics of a given video.
- The authors leverage self-supervised pre-training on large-scale video-music pairs to learn these joint embeddings, without requiring explicit annotations.
- The proposed method outperforms state-of-the-art approaches on several music recommendation benchmarks for short-form video content.
Plain English Explanation
In this paper, the researchers introduce a new way to recommend music that matches the content of short videos. Their approach, called MVBIND, works by linking the video and music embeddings together in a shared latent space. This allows the model to understand the semantic connections between the visual and audio content, so it can suggest music that fits well with a given video.
The key innovation is that MVBIND learns these joint video-music embeddings in a self-supervised manner. This means the model can be trained on large datasets of video-music pairs without requiring any manual annotations. It can discover the relationships between the visual and auditory information on its own, simply by observing many examples.
The researchers show that MVBIND outperforms other state-of-the-art music recommendation approaches when tested on short video content. This suggests the joint embedding space it learns can effectively capture the nuanced connections between videos and the music that complements them.
Technical Explanation
The core of the MVBIND approach is learning a shared latent space that binds together video and music embeddings. This is achieved through a self-supervised pre-training process on large-scale video-music datasets.
Specifically, the authors use a contrastive learning objective to push matching video-music pairs closer together in the embedding space, while separating non-matching pairs. This encourages the model to discover the semantic correspondences between the visual and auditory modalities.
During inference, the trained MVBIND model can then be used to generate music recommendations for a given video by finding the nearest music embeddings in the shared space. The authors demonstrate the effectiveness of this approach on several benchmark datasets for short-form video music recommendation.
Critical Analysis
The MVBIND paper makes a compelling case for the benefits of self-supervised cross-modal learning for music recommendation in short video content. However, the authors acknowledge that their approach has some limitations:
- The pre-training process assumes access to large video-music datasets, which may not be available in all real-world scenarios.
- The learned embeddings may not generalize well to video-music pairs that are very different from the training distribution.
- The recommendation performance could potentially be improved by incorporating additional signals, such as user preferences or contextual information.
Additionally, while the paper demonstrates strong empirical results, it would be valuable to gain a deeper understanding of the specific mechanisms by which the joint embedding space captures the connections between videos and music. Further analysis in this direction could lead to more interpretable and robust models.
Conclusion
Overall, the MVBIND paper presents a promising self-supervised approach for cross-modal music recommendation in short videos. By learning a shared latent space that binds together video and music embeddings, the model can effectively capture the semantic relationships between the visual and auditory content. This allows for music recommendations that are well-aligned with the context and meaning of a given video, which could have valuable applications in various multimedia and entertainment scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
VidMuse: A Simple Video-to-Music Generation Framework with Long-Short-Term Modeling
Zeyue Tian, Zhaoyang Liu, Ruibin Yuan, Jiahao Pan, Xiaoqiang Huang, Qifeng Liu, Xu Tan, Qifeng Chen, Wei Xue, Yike Guo
0
0
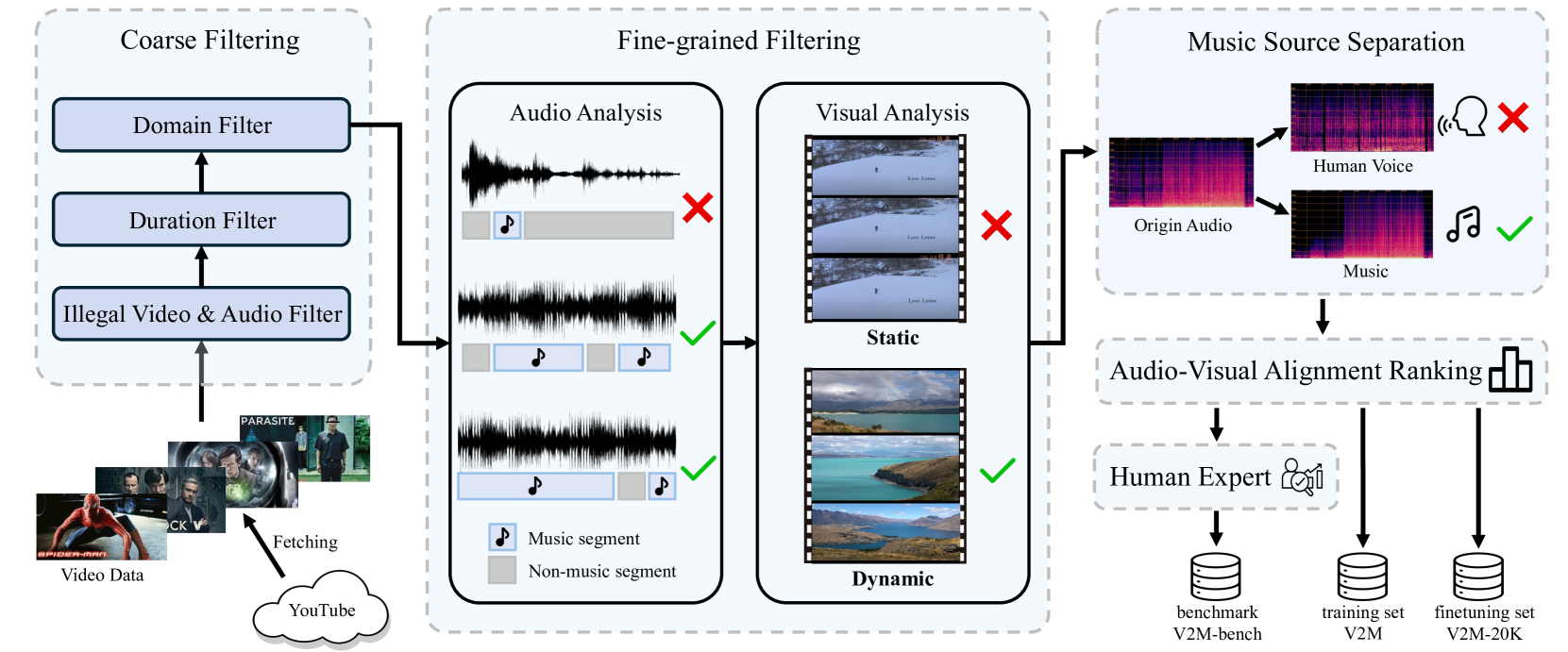
In this work, we systematically study music generation conditioned solely on the video. First, we present a large-scale dataset comprising 190K video-music pairs, including various genres such as movie trailers, advertisements, and documentaries. Furthermore, we propose VidMuse, a simple framework for generating music aligned with video inputs. VidMuse stands out by producing high-fidelity music that is both acoustically and semantically aligned with the video. By incorporating local and global visual cues, VidMuse enables the creation of musically coherent audio tracks that consistently match the video content through Long-Short-Term modeling. Through extensive experiments, VidMuse outperforms existing models in terms of audio quality, diversity, and audio-visual alignment. The code and datasets will be available at https://github.com/ZeyueT/VidMuse/.
6/7/2024

Improving Interpretable Embeddings for Ad-hoc Video Search with Generative Captions and Multi-word Concept Bank
Jiaxin Wu, Chong-Wah Ngo, Wing-Kwong Chan
0
0
Aligning a user query and video clips in cross-modal latent space and that with semantic concepts are two mainstream approaches for ad-hoc video search (AVS). However, the effectiveness of existing approaches is bottlenecked by the small sizes of available video-text datasets and the low quality of concept banks, which results in the failures of unseen queries and the out-of-vocabulary problem. This paper addresses these two problems by constructing a new dataset and developing a multi-word concept bank. Specifically, capitalizing on a generative model, we construct a new dataset consisting of 7 million generated text and video pairs for pre-training. To tackle the out-of-vocabulary problem, we develop a multi-word concept bank based on syntax analysis to enhance the capability of a state-of-the-art interpretable AVS method in modeling relationships between query words. We also study the impact of current advanced features on the method. Experimental results show that the integration of the above-proposed elements doubles the R@1 performance of the AVS method on the MSRVTT dataset and improves the xinfAP on the TRECVid AVS query sets for 2016-2023 (eight years) by a margin from 2% to 77%, with an average about 20%.
4/10/2024
Advancing Cultural Inclusivity: Optimizing Embedding Spaces for Balanced Music Recommendations
Armin Moradi, Nicola Neophytou, Golnoosh Farnadi
0
0
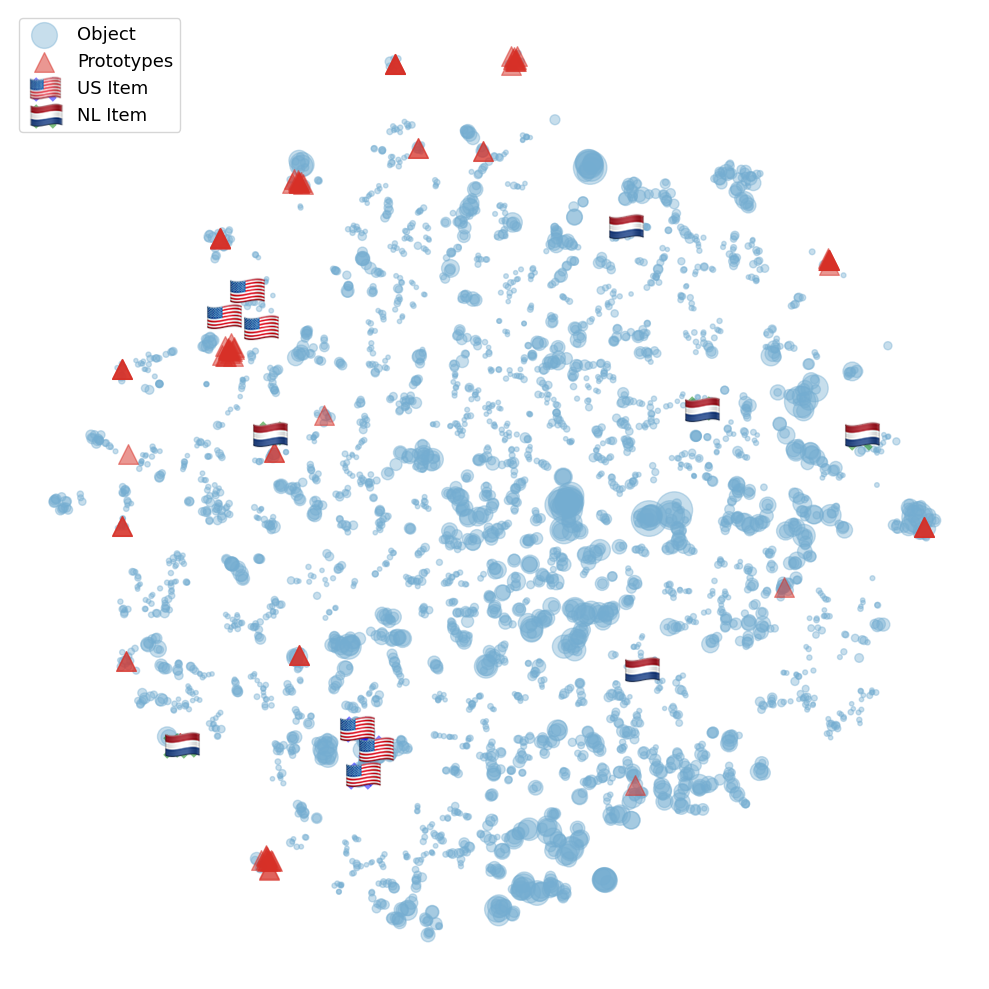
Popularity bias in music recommendation systems -- where artists and tracks with the highest listen counts are recommended more often -- can also propagate biases along demographic and cultural axes. In this work, we identify these biases in recommendations for artists from underrepresented cultural groups in prototype-based matrix factorization methods. Unlike traditional matrix factorization methods, prototype-based approaches are interpretable. This allows us to directly link the observed bias in recommendations for minority artists (the effect) to specific properties of the embedding space (the cause). We mitigate popularity bias in music recommendation through capturing both users' and songs' cultural nuances in the embedding space. To address these challenges while maintaining recommendation quality, we propose two novel enhancements to the embedding space: i) we propose an approach to filter-out the irrelevant prototypes used to represent each user and item to improve generalizability, and ii) we introduce regularization techniques to reinforce a more uniform distribution of prototypes within the embedding space. Our results demonstrate significant improvements in reducing popularity bias and enhancing demographic and cultural fairness in music recommendations while achieving competitive -- if not better -- overall performance.
5/29/2024
MVBench: A Comprehensive Multi-modal Video Understanding Benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, Limin Wang, Yu Qiao
0
0
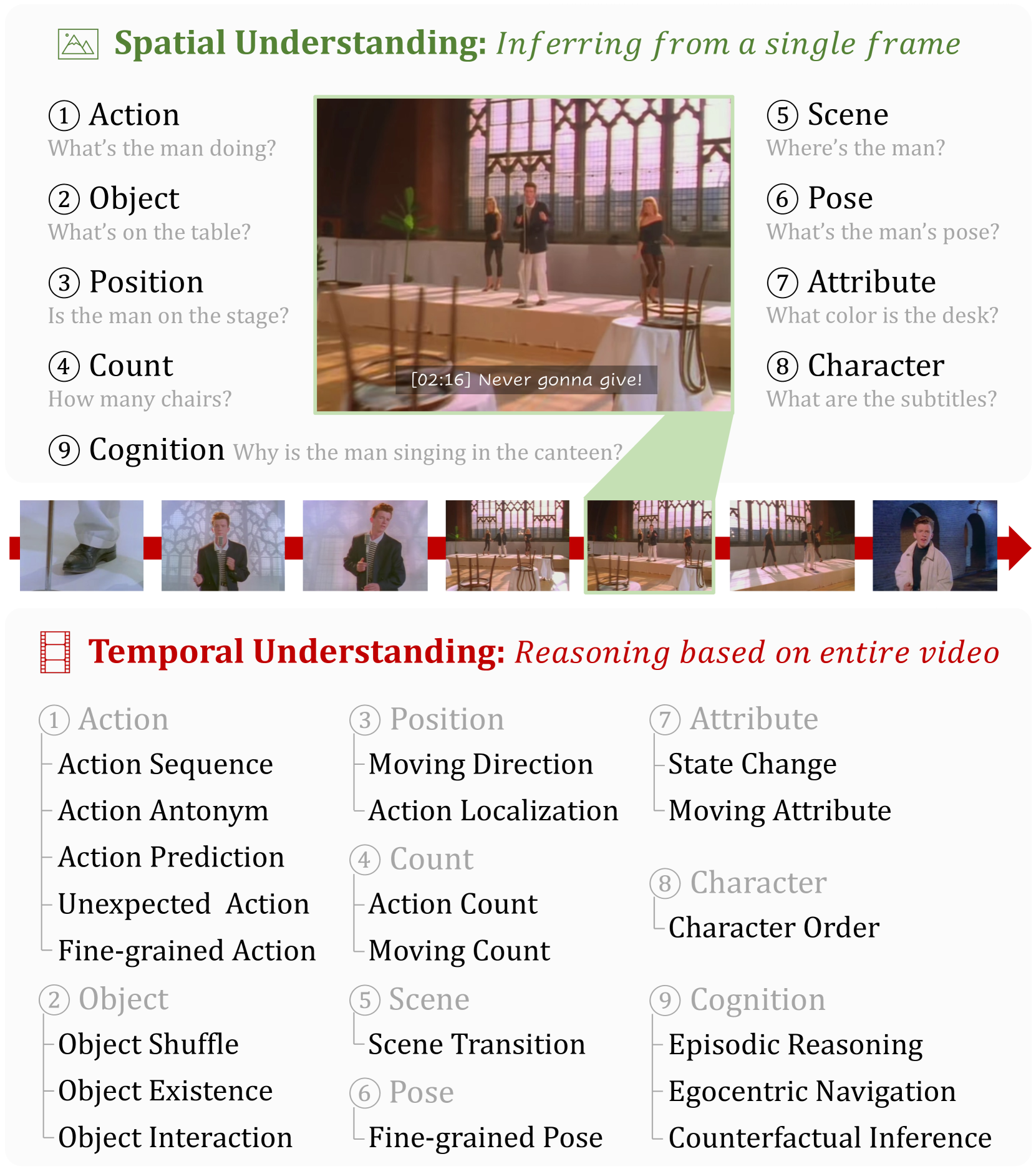
With the rapid development of Multi-modal Large Language Models (MLLMs), a number of diagnostic benchmarks have recently emerged to evaluate the comprehension capabilities of these models. However, most benchmarks predominantly assess spatial understanding in the static image tasks, while overlooking temporal understanding in the dynamic video tasks. To alleviate this issue, we introduce a comprehensive Multi-modal Video understanding Benchmark, namely MVBench, which covers 20 challenging video tasks that cannot be effectively solved with a single frame. Specifically, we first introduce a novel static-to-dynamic method to define these temporal-related tasks. By transforming various static tasks into dynamic ones, we enable the systematic generation of video tasks that require a broad spectrum of temporal skills, ranging from perception to cognition. Then, guided by the task definition, we automatically convert public video annotations into multiple-choice QA to evaluate each task. On one hand, such a distinct paradigm allows us to build MVBench efficiently, without much manual intervention. On the other hand, it guarantees evaluation fairness with ground-truth video annotations, avoiding the biased scoring of LLMs. Moreover, we further develop a robust video MLLM baseline, i.e., VideoChat2, by progressive multi-modal training with diverse instruction-tuning data. The extensive results on our MVBench reveal that, the existing MLLMs are far from satisfactory in temporal understanding, while our VideoChat2 largely surpasses these leading models by over 15% on MVBench. All models and data are available at https://github.com/OpenGVLab/Ask-Anything.
5/24/2024