View-Consistent Hierarchical 3D SegmentationUsing Ultrametric Feature Fields
2405.19678
0
0
Abstract
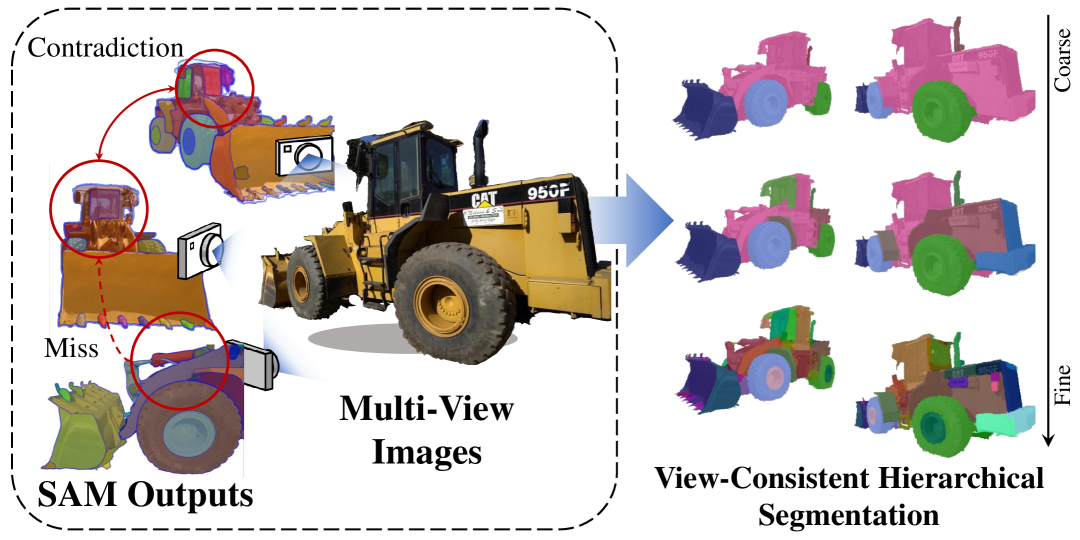
Large-scale vision foundation models such as Segment Anything (SAM) demonstrate impressive performance in zero-shot image segmentation at multiple levels of granularity. However, these zero-shot predictions are rarely 3D-consistent. As the camera viewpoint changes in a scene, so do the segmentation predictions, as well as the characterizations of coarse or fine granularity. In this work, we address the challenging task of lifting multi-granular and view-inconsistent image segmentations into a hierarchical and 3D-consistent representation. We learn a novel feature field within a Neural Radiance Field (NeRF) representing a 3D scene, whose segmentation structure can be revealed at different scales by simply using different thresholds on feature distance. Our key idea is to learn an ultrametric feature space, which unlike a Euclidean space, exhibits transitivity in distance-based grouping, naturally leading to a hierarchical clustering. Put together, our method takes view-inconsistent multi-granularity 2D segmentations as input and produces a hierarchy of 3D-consistent segmentations as output. We evaluate our method and several baselines on synthetic datasets with multi-view images and multi-granular segmentation, showcasing improved accuracy and viewpoint-consistency. We additionally provide qualitative examples of our model's 3D hierarchical segmentations in real world scenes.footnote{The code and dataset are available at:
Create account to get full access
Overview
- This paper presents a novel approach for view-consistent hierarchical 3D segmentation using ultrametric feature fields.
- The method aims to produce hierarchical 3D segmentations that are consistent across different views of the same 3D scene.
- The authors introduce a new concept called ultrametric feature fields, which capture long-range and hierarchical relationships between 3D points.
- The proposed approach leverages these feature fields to generate view-consistent, multi-scale 3D segmentations.
Plain English Explanation
The paper describes a new way to break down 3D scenes into meaningful parts. Imagine you have a 3D model of a room - this method can automatically identify the different objects in the room, like the table, chair, and wall, and organize them into a hierarchy.
The key innovation is the use of "ultrametric feature fields". This is a fancy way of saying the method learns about the relationships between different 3D points in the scene. It can figure out which points belong together as parts of the same object, and how those objects are related to each other in a broader hierarchy.
Importantly, the method ensures that this hierarchical segmentation is consistent across different views of the same 3D scene. So no matter how you rotate or move around the 3D model, the segmentation will stay the same. This view-consistency is important for applications like 3D Gaussian splatting or 3D radiance field segmentation.
The paper demonstrates that this approach outperforms previous methods for hierarchical 3D segmentation, producing more accurate and consistent results. It could be a useful tool for understanding structural similarities in 3D data or segmenting complex 3D scenes.
Technical Explanation
The core of the proposed method is the use of ultrametric feature fields to capture long-range and hierarchical relationships between 3D points. These feature fields are learned from 3D data using a neural network architecture.
The authors then use these feature fields to generate a hierarchical 3D segmentation that is consistent across different views of the same scene. This is achieved by first computing a view-consistent ultrametric distance between 3D points, and then using a clustering algorithm to extract the final segmentation.
Experiments on standard 3D segmentation benchmarks show that the proposed approach outperforms previous state-of-the-art methods in terms of segmentation accuracy and view-consistency. The authors also demonstrate the usefulness of the view-consistent hierarchical segmentations for downstream applications like 3D object detection and part-based shape analysis.
Critical Analysis
The key strength of this work is the introduction of ultrametric feature fields as a powerful representation for capturing long-range and hierarchical relationships in 3D data. This enables the generation of high-quality, view-consistent hierarchical segmentations - a significant advancement over previous methods.
That said, the paper does not provide a detailed analysis of the limitations of the approach. For example, it is unclear how the method would perform on highly cluttered or occluded 3D scenes, or how sensitive it is to changes in object geometry and appearance.
Additionally, the computational complexity of the approach is not discussed. Generating and processing the ultrametric feature fields may be computationally expensive, which could limit its applicability to large-scale 3D datasets or real-time applications.
Further research could investigate ways to make the method more efficient, as well as explore its robustness to challenging 3D scenes and its potential synergies with other 3D understanding tasks, such as object detection or scene understanding.
Conclusion
This paper presents a novel approach for view-consistent hierarchical 3D segmentation using ultrametric feature fields. The key innovation is the use of these feature fields to capture long-range and hierarchical relationships between 3D points, enabling the generation of high-quality, view-consistent segmentations.
The results demonstrate the effectiveness of the proposed method, which outperforms previous state-of-the-art approaches on standard benchmarks. This work could have significant implications for a variety of 3D understanding tasks, such as object detection, part-based shape analysis, and scene understanding.
While the paper does not address all potential limitations of the approach, it represents an important step forward in the field of 3D segmentation and could inspire further research into more efficient and robust methods for understanding the 3D world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✨
Feature 3DGS: Supercharging 3D Gaussian Splatting to Enable Distilled Feature Fields
Shijie Zhou, Haoran Chang, Sicheng Jiang, Zhiwen Fan, Zehao Zhu, Dejia Xu, Pradyumna Chari, Suya You, Zhangyang Wang, Achuta Kadambi
0
0
3D scene representations have gained immense popularity in recent years. Methods that use Neural Radiance fields are versatile for traditional tasks such as novel view synthesis. In recent times, some work has emerged that aims to extend the functionality of NeRF beyond view synthesis, for semantically aware tasks such as editing and segmentation using 3D feature field distillation from 2D foundation models. However, these methods have two major limitations: (a) they are limited by the rendering speed of NeRF pipelines, and (b) implicitly represented feature fields suffer from continuity artifacts reducing feature quality. Recently, 3D Gaussian Splatting has shown state-of-the-art performance on real-time radiance field rendering. In this work, we go one step further: in addition to radiance field rendering, we enable 3D Gaussian splatting on arbitrary-dimension semantic features via 2D foundation model distillation. This translation is not straightforward: naively incorporating feature fields in the 3DGS framework encounters significant challenges, notably the disparities in spatial resolution and channel consistency between RGB images and feature maps. We propose architectural and training changes to efficiently avert this problem. Our proposed method is general, and our experiments showcase novel view semantic segmentation, language-guided editing and segment anything through learning feature fields from state-of-the-art 2D foundation models such as SAM and CLIP-LSeg. Across experiments, our distillation method is able to provide comparable or better results, while being significantly faster to both train and render. Additionally, to the best of our knowledge, we are the first method to enable point and bounding-box prompting for radiance field manipulation, by leveraging the SAM model. Project website at: https://feature-3dgs.github.io/
4/9/2024
🏅
Segment Anything in 3D with Radiance Fields
Jiazhong Cen, Jiemin Fang, Zanwei Zhou, Chen Yang, Lingxi Xie, Xiaopeng Zhang, Wei Shen, Qi Tian
0
0
The Segment Anything Model (SAM) emerges as a powerful vision foundation model to generate high-quality 2D segmentation results. This paper aims to generalize SAM to segment 3D objects. Rather than replicating the data acquisition and annotation procedure which is costly in 3D, we design an efficient solution, leveraging the radiance field as a cheap and off-the-shelf prior that connects multi-view 2D images to the 3D space. We refer to the proposed solution as SA3D, short for Segment Anything in 3D. With SA3D, the user is only required to provide a 2D segmentation prompt (e.g., rough points) for the target object in a single view, which is used to generate its corresponding 2D mask with SAM. Next, SA3D alternately performs mask inverse rendering and cross-view self-prompting across various views to iteratively refine the 3D mask of the target object. For one view, mask inverse rendering projects the 2D mask obtained by SAM into the 3D space with guidance of the density distribution learned by the radiance field for 3D mask refinement; Then, cross-view self-prompting extracts reliable prompts automatically as the input to SAM from the rendered 2D mask of the inaccurate 3D mask for a new view. We show in experiments that SA3D adapts to various scenes and achieves 3D segmentation within seconds. Our research reveals a potential methodology to lift the ability of a 2D segmentation model to 3D. Our code is available at https://github.com/Jumpat/SegmentAnythingin3D.
4/17/2024

Hierarchical Insights: Exploiting Structural Similarities for Reliable 3D Semantic Segmentation
Mariella Dreissig, Florian Piewak, Joschka Boedecker
0
0
Safety-critical applications like autonomous driving call for robust 3D environment perception algorithms which can withstand highly diverse and ambiguous surroundings. The predictive performance of any classification model strongly depends on the underlying dataset and the prior knowledge conveyed by the annotated labels. While the labels provide a basis for the learning process, they usually fail to represent inherent relations between the classes - representations, which are a natural element of the human perception system. We propose a training strategy which enables a 3D LiDAR semantic segmentation model to learn structural relationships between the different classes through abstraction. We achieve this by implicitly modeling those relationships through a learning rule for hierarchical multi-label classification (HMC). With a detailed analysis we show, how this training strategy not only improves the model's confidence calibration, but also preserves additional information for downstream tasks like fusion, prediction and planning.
4/10/2024
SANeRF-HQ: Segment Anything for NeRF in High Quality
Yichen Liu, Benran Hu, Chi-Keung Tang, Yu-Wing Tai
0
0
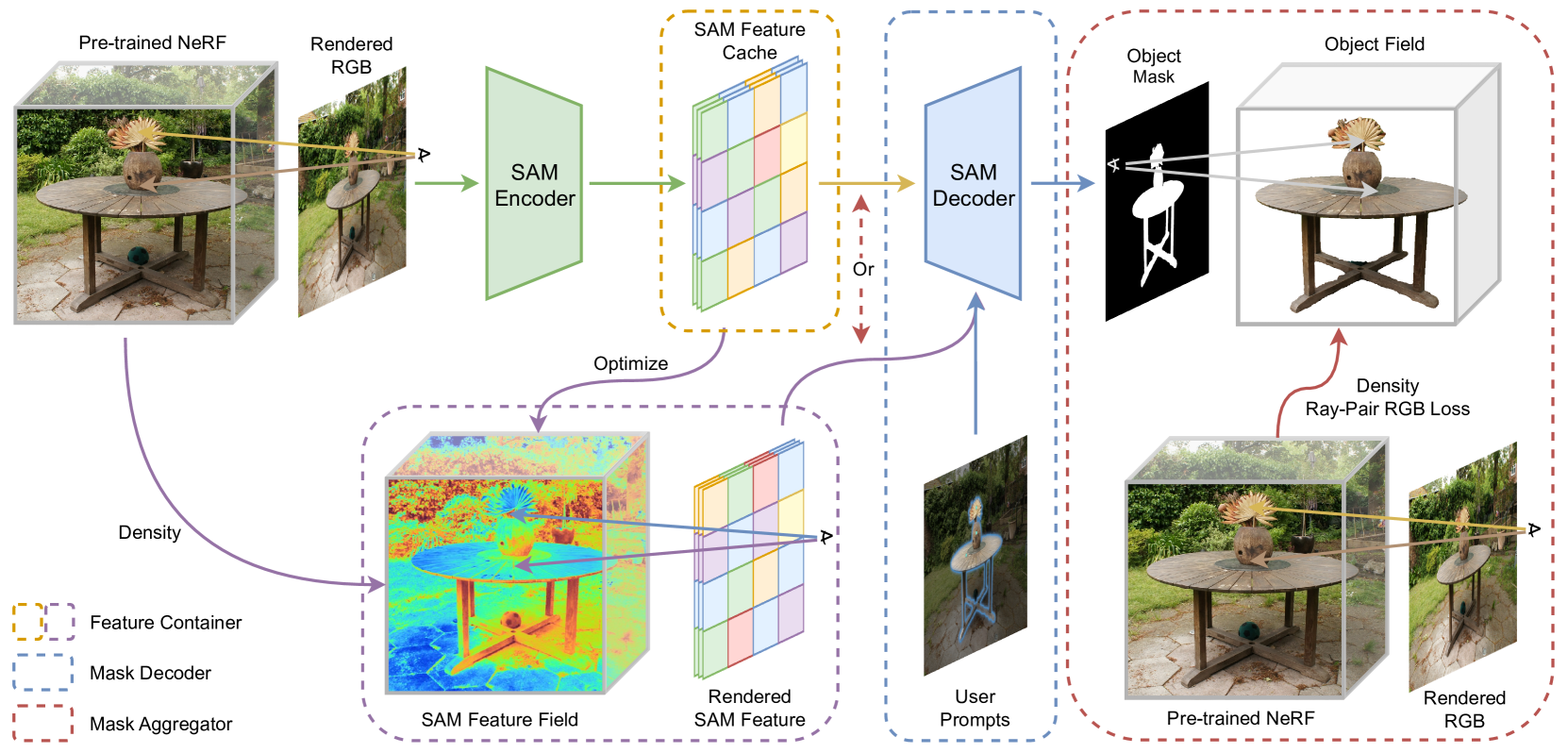
Recently, the Segment Anything Model (SAM) has showcased remarkable capabilities of zero-shot segmentation, while NeRF (Neural Radiance Fields) has gained popularity as a method for various 3D problems beyond novel view synthesis. Though there exist initial attempts to incorporate these two methods into 3D segmentation, they face the challenge of accurately and consistently segmenting objects in complex scenarios. In this paper, we introduce the Segment Anything for NeRF in High Quality (SANeRF-HQ) to achieve high-quality 3D segmentation of any target object in a given scene. SANeRF-HQ utilizes SAM for open-world object segmentation guided by user-supplied prompts, while leveraging NeRF to aggregate information from different viewpoints. To overcome the aforementioned challenges, we employ density field and RGB similarity to enhance the accuracy of segmentation boundary during the aggregation. Emphasizing on segmentation accuracy, we evaluate our method on multiple NeRF datasets where high-quality ground-truths are available or manually annotated. SANeRF-HQ shows a significant quality improvement over state-of-the-art methods in NeRF object segmentation, provides higher flexibility for object localization, and enables more consistent object segmentation across multiple views. Results and code are available at the project site: https://lyclyc52.github.io/SANeRF-HQ/.
4/9/2024