ViG-Bias: Visually Grounded Bias Discovery and Mitigation

0

Sign in to get full access
Overview
- Unsupervised bias discovery
- Bias mitigation
- Visual explanations
Plain English Explanation
This paper introduces a new method called ViG-Bias that can automatically discover and mitigate biases in machine learning models, particularly those related to visual data. The key innovation is the use of visual explanations to help identify and address these biases.
Traditionally, bias in AI systems has been challenging to detect and fix, as the biases can be deeply embedded in the training data or model architecture. ViG-Bias aims to provide a more robust and interpretable approach to this problem.
The paper discusses related work on bias mitigation techniques, including methods that use language guidance and visual understanding to address biases.
The ViG-Bias approach involves using visual explanations to identify biases, and then leveraging this information to mitigate those biases during model training. This can help ensure that the final model makes more fair and unbiased predictions, even on complex visual tasks.
Technical Explanation
The ViG-Bias method first uses an unsupervised approach to discover biases in the training data and model predictions. It does this by analyzing the visual explanations generated by the model, which show which parts of the input image are most influential for a given prediction.
By comparing the visual explanations across different input samples, ViG-Bias can identify patterns that suggest the model is relying on biased visual cues to make its predictions. For example, the model may be overly focused on certain visual attributes that are correlated with specific demographic groups.
Once the biases have been identified, ViG-Bias then uses this information to modify the model training process in order to mitigate those biases. This can involve techniques like adversarial training or calibrated loss functions that encourage the model to focus on more relevant and unbiased visual features.
The experiments in the paper demonstrate the effectiveness of ViG-Bias on a range of visual tasks and datasets, showing that it can successfully identify and reduce biases compared to other bias mitigation approaches.
Critical Analysis
The ViG-Bias method provides a promising new approach to the challenge of bias in machine learning, particularly for visual applications. By leveraging visual explanations, it offers a more interpretable and targeted way to address biases compared to some previous techniques.
However, the paper also acknowledges several limitations and areas for further research. For example, the current implementation of ViG-Bias relies on specific visual explanation models, which may not generalize well to other architectures or tasks. Additionally, the paper notes that the bias mitigation strategies used in ViG-Bias, while effective, may have some unintended consequences that require further investigation.
Overall, the ViG-Bias paper represents an important step forward in addressing the challenging problem of bias in machine learning. While more research is needed, the visual grounding approach offers a promising direction for creating more fair and equitable AI systems.
Conclusion
The ViG-Bias paper introduces a novel method for discovering and mitigating biases in machine learning models, particularly those related to visual data. By using visual explanations to identify biased patterns, ViG-Bias can then leverage this information to improve the fairness and robustness of the model during training.
This work highlights the value of interpretability and visual understanding in addressing the complex challenge of bias in AI. While further research is needed, the ViG-Bias approach represents an important step forward in creating more equitable and trustworthy machine learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ViG-Bias: Visually Grounded Bias Discovery and Mitigation
Badr-Eddine Marani, Mohamed Hanini, Nihitha Malayarukil, Stergios Christodoulidis, Maria Vakalopoulou, Enzo Ferrante
The proliferation of machine learning models in critical decision making processes has underscored the need for bias discovery and mitigation strategies. Identifying the reasons behind a biased system is not straightforward, since in many occasions they are associated with hidden spurious correlations which are not easy to spot. Standard approaches rely on bias audits performed by analyzing model performance in pre-defined subgroups of data samples, usually characterized by common attributes like gender or ethnicity when it comes to people, or other specific attributes defining semantically coherent groups of images. However, it is not always possible to know a-priori the specific attributes defining the failure modes of visual recognition systems. Recent approaches propose to discover these groups by leveraging large vision language models, which enable the extraction of cross-modal embeddings and the generation of textual descriptions to characterize the subgroups where a certain model is underperforming. In this work, we argue that incorporating visual explanations (e.g. heatmaps generated via GradCAM or other approaches) can boost the performance of such bias discovery and mitigation frameworks. To this end, we introduce Visually Grounded Bias Discovery and Mitigation (ViG-Bias), a simple yet effective technique which can be integrated to a variety of existing frameworks to improve both, discovery and mitigation performance. Our comprehensive evaluation shows that incorporating visual explanations enhances existing techniques like DOMINO, FACTS and Bias-to-Text, across several challenging datasets, including CelebA, Waterbirds, and NICO++.
Read more7/4/2024
0
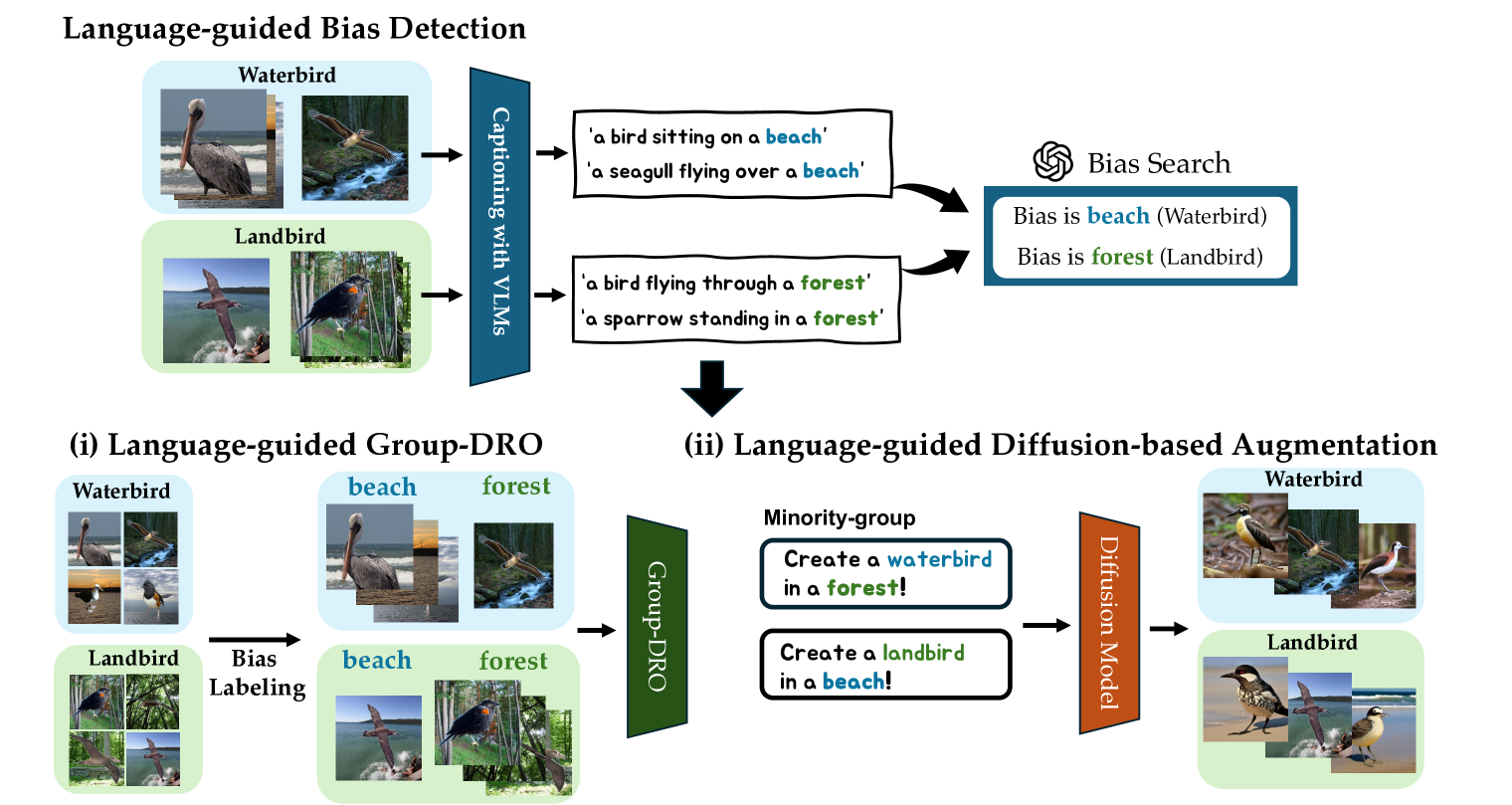
Language-guided Detection and Mitigation of Unknown Dataset Bias
Zaiying Zhao, Soichiro Kumano, Toshihiko Yamasaki
Dataset bias is a significant problem in training fair classifiers. When attributes unrelated to classification exhibit strong biases towards certain classes, classifiers trained on such dataset may overfit to these bias attributes, substantially reducing the accuracy for minority groups. Mitigation techniques can be categorized according to the availability of bias information (ie, prior knowledge). Although scenarios with unknown biases are better suited for real-world settings, previous work in this field often suffers from a lack of interpretability regarding biases and lower performance. In this study, we propose a framework to identify potential biases as keywords without prior knowledge based on the partial occurrence in the captions. We further propose two debiasing methods: (a) handing over to an existing debiasing approach which requires prior knowledge by assigning pseudo-labels, and (b) employing data augmentation via text-to-image generative models, using acquired bias keywords as prompts. Despite its simplicity, experimental results show that our framework not only outperforms existing methods without prior knowledge, but also is even comparable with a method that assumes prior knowledge.
Read more6/6/2024

0
Images Speak Louder than Words: Understanding and Mitigating Bias in Vision-Language Model from a Causal Mediation Perspective
Zhaotian Weng, Zijun Gao, Jerone Andrews, Jieyu Zhao
Vision-language models (VLMs) pre-trained on extensive datasets can inadvertently learn biases by correlating gender information with specific objects or scenarios. Current methods, which focus on modifying inputs and monitoring changes in the model's output probability scores, often struggle to comprehensively understand bias from the perspective of model components. We propose a framework that incorporates causal mediation analysis to measure and map the pathways of bias generation and propagation within VLMs. This approach allows us to identify the direct effects of interventions on model bias and the indirect effects of interventions on bias mediated through different model components. Our results show that image features are the primary contributors to bias, with significantly higher impacts than text features, specifically accounting for 32.57% and 12.63% of the bias in the MSCOCO and PASCAL-SENTENCE datasets, respectively. Notably, the image encoder's contribution surpasses that of the text encoder and the deep fusion encoder. Further experimentation confirms that contributions from both language and vision modalities are aligned and non-conflicting. Consequently, focusing on blurring gender representations within the image encoder, which contributes most to the model bias, reduces bias efficiently by 22.03% and 9.04% in the MSCOCO and PASCAL-SENTENCE datasets, respectively, with minimal performance loss or increased computational demands.
Read more7/4/2024
🤿
0
Are Bias Mitigation Techniques for Deep Learning Effective?
Robik Shrestha, Kushal Kafle, Christopher Kanan
A critical problem in deep learning is that systems learn inappropriate biases, resulting in their inability to perform well on minority groups. This has led to the creation of multiple algorithms that endeavor to mitigate bias. However, it is not clear how effective these methods are. This is because study protocols differ among papers, systems are tested on datasets that fail to test many forms of bias, and systems have access to hidden knowledge or are tuned specifically to the test set. To address this, we introduce an improved evaluation protocol, sensible metrics, and a new dataset, which enables us to ask and answer critical questions about bias mitigation algorithms. We evaluate seven state-of-the-art algorithms using the same network architecture and hyperparameter selection policy across three benchmark datasets. We introduce a new dataset called Biased MNIST that enables assessment of robustness to multiple bias sources. We use Biased MNIST and a visual question answering (VQA) benchmark to assess robustness to hidden biases. Rather than only tuning to the test set distribution, we study robustness across different tuning distributions, which is critical because for many applications the test distribution may not be known during development. We find that algorithms exploit hidden biases, are unable to scale to multiple forms of bias, and are highly sensitive to the choice of tuning set. Based on our findings, we implore the community to adopt more rigorous assessment of future bias mitigation methods. All data, code, and results are publicly available at: https://github.com/erobic/bias-mitigators.
Read more4/24/2024