VisFly: An Efficient and Versatile Simulator for Training Vision-based Flight

0
Sign in to get full access
Overview
- VisFly is a high-performance simulator for training vision-based flight control algorithms.
- It aims to bridge the gap between simulation and real-world deployment of autonomous drone systems.
- VisFly provides a flexible and efficient environment for developing and testing vision-based flight control models.
Plain English Explanation
VisFly: An Efficient and Versatile Simulator for Training Vision-based Flight presents a new simulator designed to help researchers and developers create autonomous drone systems that can fly based on visual input alone. This is an important capability, as it allows drones to navigate and perform tasks without relying on GPS or other external sensors, which can be unreliable or unavailable in certain environments.
The key idea behind VisFly is to provide a realistic and flexible simulation environment that can accurately model the visual and physical aspects of drone flight. This allows researchers to train and test their vision-based flight control algorithms in a safe, controlled setting before deploying them in the real world. VisFly aims to bridge the gap between simulation and real-world deployment, enabling faster iteration and more robust autonomous drone systems.
Technical Explanation
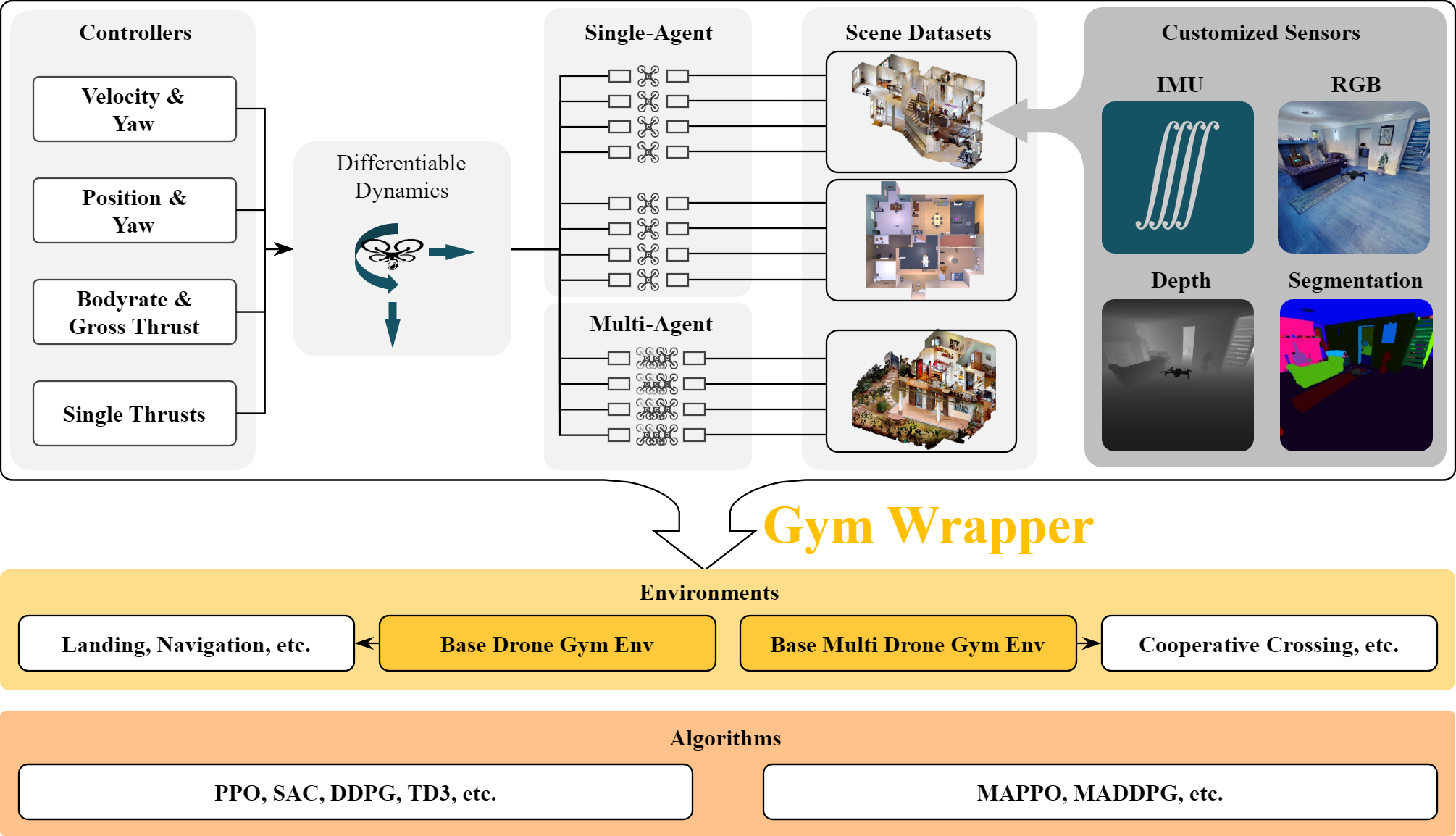
VisFly is designed to be an efficient and versatile simulator for training vision-based flight control algorithms. It leverages recent advancements in computer graphics and physics simulation to provide a highly realistic and customizable environment for drone flight.
One of the key features of VisFly is its ability to generate high-fidelity visual data, including detailed 3D models of environments and realistic lighting and weather effects. This allows it to accurately simulate the visual inputs that a drone's camera would receive during flight. Additionally, VisFly models the physical dynamics of drone flight, including thrust, aerodynamics, and environmental forces, ensuring that the simulated behavior closely matches reality.
The simulator's architecture is designed for efficiency, with a modular design that allows for easy customization and integration with various machine learning frameworks. This enables researchers to quickly iterate on their vision-based flight control algorithms and test them in a wide range of scenarios.
Critical Analysis
The paper presents a thorough evaluation of VisFly's capabilities, demonstrating its ability to accurately simulate real-world drone flight and the effectiveness of vision-based control algorithms trained using the simulator. However, the authors acknowledge that there are some limitations to the current implementation, such as the need for further improvements in the accuracy of physical modeling and the representation of complex environments.
Additionally, while VisFly aims to bridge the gap between simulation and real-world deployment, the authors note that there may still be some challenges in fully transferring the learned behaviors from the simulator to actual drone platforms. Further research and experimentation may be needed to address these issues and ensure the seamless deployment of vision-based autonomous drone systems.
Conclusion
VisFly represents a significant advancement in the field of autonomous drone flight, providing a powerful and versatile simulator for training and testing vision-based control algorithms. By accurately modeling the visual and physical aspects of drone flight, VisFly enables researchers to develop more robust and capable autonomous drone systems that can operate reliably in a wide range of environments. The potential applications of this technology are vast, from search and rescue operations to infrastructure inspection and environmental monitoring, and the continued development of VisFly and similar simulation platforms is likely to play a crucial role in the advancement of autonomous drone technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
VisFly: An Efficient and Versatile Simulator for Training Vision-based Flight
Fanxing Li, Fangyu Sun, Tianbao Zhang, Danping Zou
We present VisFly, a quadrotor simulator designed to efficiently train vision-based flight policies using reinforcement learning algorithms. VisFly offers a user-friendly framework and interfaces, leveraging Habitat-Sim's rendering engines to achieve frame rates exceeding 10,000 frames per second for rendering motion and sensor data. The simulator incorporates differentiable physics and is seamlessly wrapped with the Gym environment, facilitating the straightforward implementation of various learning algorithms. It supports the directly importing open-source scene datasets compatible with Habitat-Sim, enabling training on diverse real-world environments simultaneously. To validate our simulator, we also make three reinforcement learning examples for typical flight tasks relying on visual observations. The simulator is now available at [https://github.com/SJTU-ViSYS-team/VisFly].
Read more9/10/2024
🗣️
0
Learning to Fly in Seconds
Jonas Eschmann, Dario Albani, Giuseppe Loianno
Learning-based methods, particularly Reinforcement Learning (RL), hold great promise for streamlining deployment, enhancing performance, and achieving generalization in the control of autonomous multirotor aerial vehicles. Deep RL has been able to control complex systems with impressive fidelity and agility in simulation but the simulation-to-reality transfer often brings a hard-to-bridge reality gap. Moreover, RL is commonly plagued by prohibitively long training times. In this work, we propose a novel asymmetric actor-critic-based architecture coupled with a highly reliable RL-based training paradigm for end-to-end quadrotor control. We show how curriculum learning and a highly optimized simulator enhance sample complexity and lead to fast training times. To precisely discuss the challenges related to low-level/end-to-end multirotor control, we also introduce a taxonomy that classifies the existing levels of control abstractions as well as non-linearities and domain parameters. Our framework enables Simulation-to-Reality (Sim2Real) transfer for direct RPM control after only 18 seconds of training on a consumer-grade laptop as well as its deployment on microcontrollers to control a multirotor under real-time guarantees. Finally, our solution exhibits competitive performance in trajectory tracking, as demonstrated through various experimental comparisons with existing state-of-the-art control solutions using a real Crazyflie nano quadrotor. We open source the code including a very fast multirotor dynamics simulator that can simulate about 5 months of flight per second on a laptop GPU. The fast training times and deployment to a cheap, off-the-shelf quadrotor lower the barriers to entry and help democratize the research and development of these systems.
Read more4/10/2024

0
Back to Newton's Laws: Learning Vision-based Agile Flight via Differentiable Physics
Yuang Zhang, Yu Hu, Yunlong Song, Danping Zou, Weiyao Lin
Swarm navigation in cluttered environments is a grand challenge in robotics. This work combines deep learning with first-principle physics through differentiable simulation to enable autonomous navigation of multiple aerial robots through complex environments at high speed. Our approach optimizes a neural network control policy directly by backpropagating loss gradients through the robot simulation using a simple point-mass physics model and a depth rendering engine. Despite this simplicity, our method excels in challenging tasks for both multi-agent and single-agent applications with zero-shot sim-to-real transfer. In multi-agent scenarios, our system demonstrates self-organized behavior, enabling autonomous coordination without communication or centralized planning - an achievement not seen in existing traditional or learning-based methods. In single-agent scenarios, our system achieves a 90% success rate in navigating through complex environments, significantly surpassing the 60% success rate of the previous state-of-the-art approach. Our system can operate without state estimation and adapt to dynamic obstacles. In real-world forest environments, it navigates at speeds up to 20 m/s, doubling the speed of previous imitation learning-based solutions. Notably, all these capabilities are deployed on a budget-friendly $21 computer, costing less than 5% of a GPU-equipped board used in existing systems. Video demonstrations are available at https://youtu.be/LKg9hJqc2cc.
Read more7/17/2024

0
Demonstrating Agile Flight from Pixels without State Estimation
Ismail Geles, Leonard Bauersfeld, Angel Romero, Jiaxu Xing, Davide Scaramuzza
Quadrotors are among the most agile flying robots. Despite recent advances in learning-based control and computer vision, autonomous drones still rely on explicit state estimation. On the other hand, human pilots only rely on a first-person-view video stream from the drone onboard camera to push the platform to its limits and fly robustly in unseen environments. To the best of our knowledge, we present the first vision-based quadrotor system that autonomously navigates through a sequence of gates at high speeds while directly mapping pixels to control commands. Like professional drone-racing pilots, our system does not use explicit state estimation and leverages the same control commands humans use (collective thrust and body rates). We demonstrate agile flight at speeds up to 40km/h with accelerations up to 2g. This is achieved by training vision-based policies with reinforcement learning (RL). The training is facilitated using an asymmetric actor-critic with access to privileged information. To overcome the computational complexity during image-based RL training, we use the inner edges of the gates as a sensor abstraction. This simple yet robust, task-relevant representation can be simulated during training without rendering images. During deployment, a Swin-transformer-based gate detector is used. Our approach enables autonomous agile flight with standard, off-the-shelf hardware. Although our demonstration focuses on drone racing, we believe that our method has an impact beyond drone racing and can serve as a foundation for future research into real-world applications in structured environments.
Read more6/19/2024