Learning to Fly in Seconds
2311.13081
0
0
🗣️
Abstract
Learning-based methods, particularly Reinforcement Learning (RL), hold great promise for streamlining deployment, enhancing performance, and achieving generalization in the control of autonomous multirotor aerial vehicles. Deep RL has been able to control complex systems with impressive fidelity and agility in simulation but the simulation-to-reality transfer often brings a hard-to-bridge reality gap. Moreover, RL is commonly plagued by prohibitively long training times. In this work, we propose a novel asymmetric actor-critic-based architecture coupled with a highly reliable RL-based training paradigm for end-to-end quadrotor control. We show how curriculum learning and a highly optimized simulator enhance sample complexity and lead to fast training times. To precisely discuss the challenges related to low-level/end-to-end multirotor control, we also introduce a taxonomy that classifies the existing levels of control abstractions as well as non-linearities and domain parameters. Our framework enables Simulation-to-Reality (Sim2Real) transfer for direct RPM control after only 18 seconds of training on a consumer-grade laptop as well as its deployment on microcontrollers to control a multirotor under real-time guarantees. Finally, our solution exhibits competitive performance in trajectory tracking, as demonstrated through various experimental comparisons with existing state-of-the-art control solutions using a real Crazyflie nano quadrotor. We open source the code including a very fast multirotor dynamics simulator that can simulate about 5 months of flight per second on a laptop GPU. The fast training times and deployment to a cheap, off-the-shelf quadrotor lower the barriers to entry and help democratize the research and development of these systems.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper proposes a novel deep reinforcement learning (RL) framework for end-to-end control of autonomous multirotor aerial vehicles.
- It addresses key challenges in RL, such as the simulation-to-reality gap and long training times, using techniques like curriculum learning and a highly optimized simulator.
- The framework enables rapid Simulation-to-Reality (Sim2Real) transfer and real-time deployment on microcontrollers, with competitive performance in trajectory tracking.
- The authors open-source the code, including a fast multirotor dynamics simulator, to democratize research and development in this area.
Plain English Explanation
The paper explores how deep reinforcement learning (RL) can be used to control autonomous multirotor drones. RL is a powerful technique that allows drones to learn how to fly on their own, but it often has some challenges.
One big challenge is the "simulation-to-reality gap" - what works well in computer simulations doesn't always work as well in the real world. Another challenge is that RL can take a very long time to train the drones to fly properly.
To address these issues, the researchers developed a new RL-based framework that uses a few key techniques:
- Curriculum learning: This means they start the training process with simpler tasks and gradually increase the difficulty, which helps the drones learn more efficiently.
- Highly optimized simulator: They built a very fast simulator that can simulate months of flight in just seconds on a laptop. This allows them to train the drones much more quickly.
Using this framework, the researchers were able to train a drone to directly control its propeller speeds (a low-level control task) in just 18 seconds on a regular laptop. They were also able to deploy the trained drone to control a real-world, off-the-shelf quadrotor in real-time.
The researchers open-sourced their code, including the fast simulator, to help make it easier for other researchers and developers to work on autonomous drone control using RL. This could help democratize the research and development of these systems.
Technical Explanation
The paper presents a novel deep reinforcement learning (RL) framework for end-to-end control of autonomous multirotor aerial vehicles. To address key challenges in RL, such as the simulation-to-reality gap and long training times, the authors employ several techniques:
Asymmetric Actor-Critic Architecture: The framework uses an asymmetric actor-critic architecture, where the actor and critic networks have different structures and input spaces. This allows the actor network to focus on low-level control while the critic network handles higher-level reasoning.
Curriculum Learning: The authors use curriculum learning, where the training process starts with simpler tasks and gradually increases the difficulty. This helps the RL agent learn more efficiently and achieve better performance.
Optimized Simulator: The researchers developed a highly optimized multirotor dynamics simulator that can simulate about 5 months of flight per second on a laptop GPU. This allows for rapid training of the RL agent.
The paper also introduces a taxonomy to precisely discuss the challenges related to low-level/end-to-end multirotor control, covering aspects like non-linearities and domain parameters.
The proposed framework enables Simulation-to-Reality (Sim2Real) transfer for direct propeller speed control after only 18 seconds of training on a consumer-grade laptop. It can also be deployed on microcontrollers to control a real multirotor under real-time guarantees.
The framework exhibits competitive performance in trajectory tracking, as demonstrated through various experimental comparisons with existing state-of-the-art control solutions using a real Crazyflie nano quadrotor.
Critical Analysis
The paper presents a promising approach to addressing key challenges in applying deep reinforcement learning for multirotor control. The use of an asymmetric actor-critic architecture, curriculum learning, and a highly optimized simulator are innovative techniques that help bridge the simulation-to-reality gap and reduce training time.
However, the paper does not fully explore the limitations and potential issues of the proposed framework. For example, it is unclear how the framework would perform in more complex real-world scenarios, such as navigating cluttered environments or handling unexpected disturbances.
Additionally, the authors do not provide a detailed analysis of the safety and reliability of the real-time deployment on microcontrollers. Ensuring the safety and robustness of such systems is crucial for their practical deployment in real-world applications.
Further research is needed to thoroughly evaluate the framework's scalability, generalization capabilities, and long-term reliability, especially in more challenging and dynamic environments. Exploring the transferability of the learned policies to different multirotor platforms could also be an area for future investigation.
Conclusion
This paper presents a novel deep reinforcement learning framework for end-to-end control of autonomous multirotor aerial vehicles. By addressing key challenges in RL, such as the simulation-to-reality gap and long training times, the framework enables rapid Simulation-to-Reality (Sim2Real) transfer and real-time deployment on microcontrollers.
The open-sourcing of the code, including a fast multirotor dynamics simulator, has the potential to democratize the research and development of these systems. This could significantly lower the barriers to entry and accelerate progress in the field of autonomous drone control.
While the framework shows promising results, further research is needed to fully explore its limitations and potential issues, as well as to evaluate its scalability and long-term reliability in more complex real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
Reinforcement Learning based Autonomous Multi-Rotor Landing on Moving Platforms
Pascal Goldschmid, Aamir Ahmad
0
0
Multi-rotor UAVs suffer from a restricted range and flight duration due to limited battery capacity. Autonomous landing on a 2D moving platform offers the possibility to replenish batteries and offload data, thus increasing the utility of the vehicle. Classical approaches rely on accurate, complex and difficult-to-derive models of the vehicle and the environment. Reinforcement learning (RL) provides an attractive alternative due to its ability to learn a suitable control policy exclusively from data during a training procedure. However, current methods require several hours to train, have limited success rates and depend on hyperparameters that need to be tuned by trial-and-error. We address all these issues in this work. First, we decompose the landing procedure into a sequence of simpler, but similar learning tasks. This is enabled by applying two instances of the same RL based controller trained for 1D motion for controlling the multi-rotor's movement in both the longitudinal and the lateral directions. Second, we introduce a powerful state space discretization technique that is based on i) kinematic modeling of the moving platform to derive information about the state space topology and ii) structuring the training as a sequential curriculum using transfer learning. Third, we leverage the kinematics model of the moving platform to also derive interpretable hyperparameters for the training process that ensure sufficient maneuverability of the multi-rotor vehicle. The training is performed using the tabular RL method Double Q-Learning. Through extensive simulations we show that the presented method significantly increases the rate of successful landings, while requiring less training time compared to other deep RL approaches. Finally, we deploy and demonstrate our algorithm on real hardware. For all evaluation scenarios we provide statistics on the agent's performance.
5/17/2024
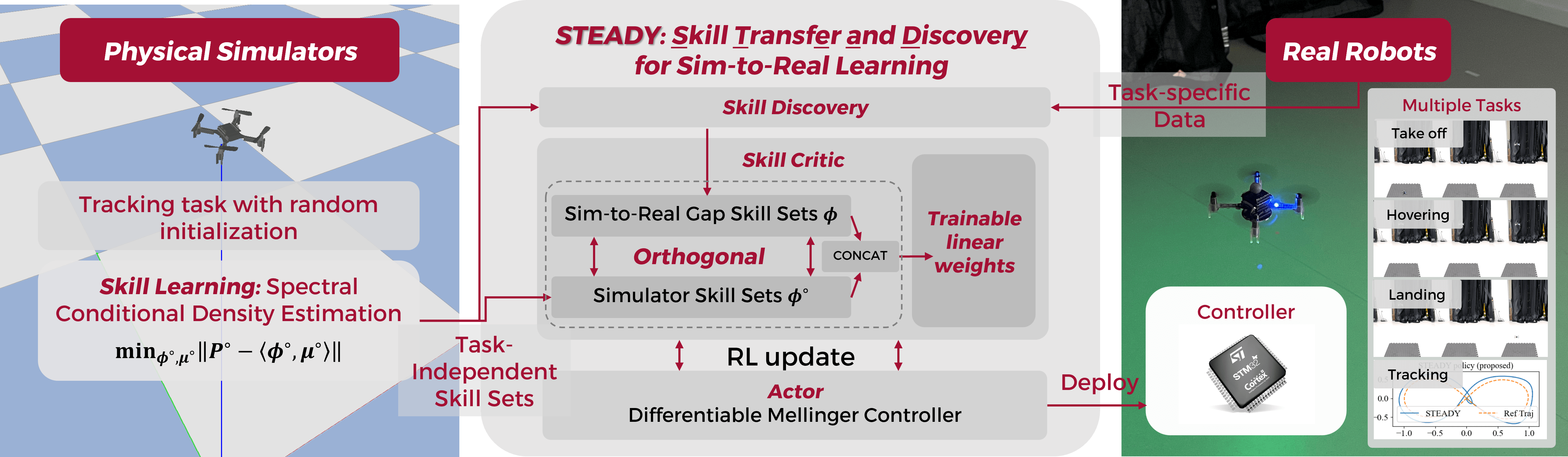
Skill Transfer and Discovery for Sim-to-Real Learning: A Representation-Based Viewpoint
Haitong Ma, Zhaolin Ren, Bo Dai, Na Li
0
0
We study sim-to-real skill transfer and discovery in the context of robotics control using representation learning. We draw inspiration from spectral decomposition of Markov decision processes. The spectral decomposition brings about representation that can linearly represent the state-action value function induced by any policies, thus can be regarded as skills. The skill representations are transferable across arbitrary tasks with the same transition dynamics. Moreover, to handle the sim-to-real gap in the dynamics, we propose a skill discovery algorithm that learns new skills caused by the sim-to-real gap from real-world data. We promote the discovery of new skills by enforcing orthogonal constraints between the skills to learn and the skills from simulators, and then synthesize the policy using the enlarged skill sets. We demonstrate our methodology by transferring quadrotor controllers from simulators to Crazyflie 2.1 quadrotors. We show that we can learn the skill representations from a single simulator task and transfer these to multiple different real-world tasks including hovering, taking off, landing and trajectory tracking. Our skill discovery approach helps narrow the sim-to-real gap and improve the real-world controller performance by up to 30.2%.
4/9/2024
❗
Neural-Fly Enables Rapid Learning for Agile Flight in Strong Winds
Michael O'Connell, Guanya Shi, Xichen Shi, Kamyar Azizzadenesheli, Anima Anandkumar, Yisong Yue, Soon-Jo Chung
0
0
Executing safe and precise flight maneuvers in dynamic high-speed winds is important for the ongoing commoditization of uninhabited aerial vehicles (UAVs). However, because the relationship between various wind conditions and its effect on aircraft maneuverability is not well understood, it is challenging to design effective robot controllers using traditional control design methods. We present Neural-Fly, a learning-based approach that allows rapid online adaptation by incorporating pretrained representations through deep learning. Neural-Fly builds on two key observations that aerodynamics in different wind conditions share a common representation and that the wind-specific part lies in a low-dimensional space. To that end, Neural-Fly uses a proposed learning algorithm, domain adversarially invariant meta-learning (DAIML), to learn the shared representation, only using 12 minutes of flight data. With the learned representation as a basis, Neural-Fly then uses a composite adaptation law to update a set of linear coefficients for mixing the basis elements. When evaluated under challenging wind conditions generated with the Caltech Real Weather Wind Tunnel, with wind speeds up to 43.6 kilometers/hour (12.1 meters/second), Neural-Fly achieves precise flight control with substantially smaller tracking error than state-of-the-art nonlinear and adaptive controllers. In addition to strong empirical performance, the exponential stability of Neural-Fly results in robustness guarantees. Last, our control design extrapolates to unseen wind conditions, is shown to be effective for outdoor flights with only onboard sensors, and can transfer across drones with minimal performance degradation.
4/15/2024
Adaptive Reinforcement Learning for Robot Control
Yu Tang Liu, Nilaksh Singh, Aamir Ahmad
0
0
Deep reinforcement learning (DRL) has shown remarkable success in simulation domains, yet its application in designing robot controllers remains limited, due to its single-task orientation and insufficient adaptability to environmental changes. To overcome these limitations, we present a novel adaptive agent that leverages transfer learning techniques to dynamically adapt policy in response to different tasks and environmental conditions. The approach is validated through the blimp control challenge, where multitasking capabilities and environmental adaptability are essential. The agent is trained using a custom, highly parallelized simulator built on IsaacGym. We perform zero-shot transfer to fly the blimp in the real world to solve various tasks. We share our code at url{https://github.com/robot-perception-group/adaptive_agent/}.
4/30/2024