Vision Augmentation Prediction Autoencoder with Attention Design (VAPAAD)
2404.10096
0
0

Abstract
Despite significant advancements in sequence prediction, current methods lack attention-based mechanisms for next-frame prediction. Our work introduces VAPAAD or Vision Augmentation Prediction Autoencoder with Attention Design, an innovative model that enhances predictive performance by integrating attention designs, allowing for nuanced understanding and handling of temporal dynamics in video sequences. We demonstrate using the famous Moving MNIST dataset the robust performance of the proposed model and potential applicability of such design in the literature.
Create account to get full access
Overview
- Proposed a novel "Vision Augmentation Prediction Autoencoder with Attention Design" (VAPAAD) model for visual representation learning
- Leverages prediction tasks to learn more effective representations that can be used for downstream computer vision applications
- Incorporates an attention mechanism to selectively focus on relevant features during the prediction process
Plain English Explanation
The VAPAAD model is designed to learn effective visual representations that can be used for various computer vision tasks, such as object detection or image classification. Rather than just looking at the input image, the model also tries to predict certain aspects of the image, such as what objects might be present or how the image might change over time.
By incorporating this prediction task, the model is encouraged to learn representations that capture more meaningful and informative features of the input. The attention mechanism helps the model focus on the most relevant parts of the image when making these predictions, further enhancing the quality of the learned representations.
The key idea is that learning to predict future or hidden aspects of the input can lead to better feature extraction, which in turn can improve the model's performance on downstream computer vision applications. This approach aims to go beyond simply memorizing the training data and instead learn more generalizable and powerful visual representations.
Technical Explanation
The VAPAAD model consists of an encoder-decoder architecture with an attention module. The encoder takes in an input image and produces a latent representation, which is then used by the decoder to reconstruct the input image and predict certain target outputs, such as the presence of objects or the future state of the image.
The attention module is used to selectively focus on the most relevant regions of the input image when making these predictions. By dynamically weighting the different parts of the image, the model can better capture the most informative features for the task at hand.
The key innovation of VAPAAD is the use of these prediction tasks, which force the model to learn representations that are not only good at reconstructing the input, but also capture the underlying structure and dynamics of the visual data. This is in contrast to more traditional approaches that rely solely on supervised learning or unsupervised reconstruction.
The authors demonstrate the effectiveness of VAPAAD through experiments on several computer vision benchmarks, showing that the learned representations outperform those obtained from other state-of-the-art methods. The attention mechanism is also shown to be a crucial component, allowing the model to focus on the most relevant features during the prediction process.
Critical Analysis
The VAPAAD model presents an interesting approach to learning visual representations, but there are a few potential limitations and areas for further research:
-
The specific prediction tasks used in the paper may not be the most optimal or generalizable to all types of visual data. Exploring alternative prediction objectives or combining multiple tasks could potentially lead to even more effective representations.
-
The attention mechanism, while shown to be beneficial, could be further refined or extended to capture more complex dependencies in the input. Exploring different attention architectures or incorporating additional contextual information may yield improvements.
-
The paper focuses primarily on evaluating the learned representations on downstream tasks, but does not provide a detailed analysis of the internal workings or learned features of the VAPAAD model. A more in-depth examination of the model's internal representations could provide additional insights.
-
The performance of VAPAAD is demonstrated on a limited set of benchmarks, and its generalization to more diverse and challenging computer vision problems remains to be explored.
Overall, the VAPAAD model presents a promising direction for learning effective visual representations, but further research and refinement may be needed to fully realize its potential.
Conclusion
The VAPAAD model introduces a novel approach to visual representation learning by incorporating prediction tasks and attention mechanisms. By forcing the model to not only reconstruct the input, but also predict certain aspects of the visual data, the learned representations capture more meaningful and informative features that can be leveraged for a variety of computer vision applications.
The attention module allows the model to selectively focus on the most relevant regions of the input, further enhancing the quality of the learned representations. The authors demonstrate the effectiveness of this approach through experiments on several benchmarks, showing that VAPAAD outperforms other state-of-the-art methods.
While the VAPAAD model presents an interesting and promising direction, there are still opportunities for further research and refinement, such as exploring alternative prediction tasks, improving the attention mechanism, and evaluating the model's performance on a wider range of computer vision problems. Nonetheless, the core ideas behind VAPAAD highlight the potential of leveraging prediction-based learning for more effective visual representation learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

An Exploratory Study on Human-Centric Video Anomaly Detection through Variational Autoencoders and Trajectory Prediction
Ghazal Alinezhad Noghre, Armin Danesh Pazho, Hamed Tabkhi
0
0
Video Anomaly Detection (VAD) represents a challenging and prominent research task within computer vision. In recent years, Pose-based Video Anomaly Detection (PAD) has drawn considerable attention from the research community due to several inherent advantages over pixel-based approaches despite the occasional suboptimal performance. Specifically, PAD is characterized by reduced computational complexity, intrinsic privacy preservation, and the mitigation of concerns related to discrimination and bias against specific demographic groups. This paper introduces TSGAD, a novel human-centric Two-Stream Graph-Improved Anomaly Detection leveraging Variational Autoencoders (VAEs) and trajectory prediction. TSGAD aims to explore the possibility of utilizing VAEs as a new approach for pose-based human-centric VAD alongside the benefits of trajectory prediction. We demonstrate TSGAD's effectiveness through comprehensive experimentation on benchmark datasets. TSGAD demonstrates comparable results with state-of-the-art methods showcasing the potential of adopting variational autoencoders. This suggests a promising direction for future research endeavors. The code base for this work is available at https://github.com/TeCSAR-UNCC/TSGAD.
6/26/2024
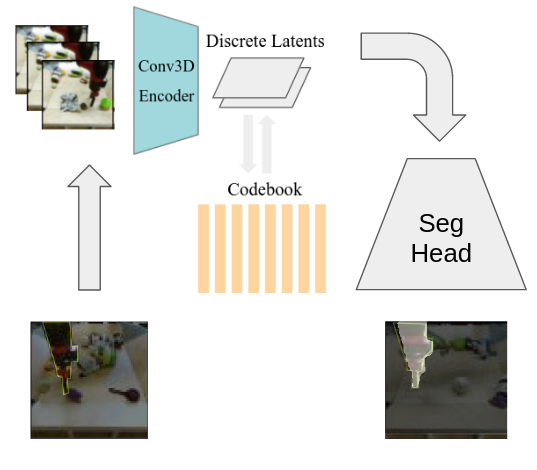
Video Prediction Models as General Visual Encoders
James Maier, Nishanth Mohankumar
0
0
This study explores the potential of open-source video conditional generation models as encoders for downstream tasks, focusing on instance segmentation using the BAIR Robot Pushing Dataset. The researchers propose using video prediction models as general visual encoders, leveraging their ability to capture critical spatial and temporal information which is essential for tasks such as instance segmentation. Inspired by human vision studies, particularly Gestalts principle of common fate, the approach aims to develop a latent space representative of motion from images to effectively discern foreground from background information. The researchers utilize a 3D Vector-Quantized Variational Autoencoder 3D VQVAE video generative encoder model conditioned on an input frame, coupled with downstream segmentation tasks. Experiments involve adapting pre-trained video generative models, analyzing their latent spaces, and training custom decoders for foreground-background segmentation. The findings demonstrate promising results in leveraging generative pretext learning for downstream tasks, working towards enhanced scene analysis and segmentation in computer vision applications.
5/28/2024

Ada-VE: Training-Free Consistent Video Editing Using Adaptive Motion Prior
Tanvir Mahmud, Mustafa Munir, Radu Marculescu, Diana Marculescu
0
0
Video-to-video synthesis models face significant challenges, such as ensuring consistent character generation across frames, maintaining smooth temporal transitions, and preserving quality during fast motion. The introduction of joint fully cross-frame self-attention mechanisms has improved character consistency, but this comes at the cost of increased computational complexity. This full cross-frame self-attention mechanism also incorporates redundant details and limits the number of frames that can be jointly edited due to its computational cost. Moreover, the lack of frames in cross-frame attention adversely affects temporal consistency and visual quality. To address these limitations, we propose a new adaptive motion-guided cross-frame attention mechanism that drastically reduces complexity while preserving semantic details and temporal consistency. Specifically, we selectively incorporate the moving regions of successive frames in cross-frame attention and sparsely include stationary regions based on optical flow sampling. This technique allows for an increased number of jointly edited frames without additional computational overhead. For longer duration of video editing, existing methods primarily focus on frame interpolation or flow-warping from jointly edited keyframes, which often results in blurry frames or reduced temporal consistency. To improve this, we introduce KV-caching of jointly edited frames and reuse the same KV across all intermediate frames, significantly enhancing both intermediate frame quality and temporal consistency. Overall, our motion-sampling method enables the use of around three times more keyframes than existing joint editing methods while maintaining superior prediction quality. Ada-VE achieves up to 4x speed-up when using fully-extended self-attention across 40 frames for joint editing, without compromising visual quality or temporal consistency.
6/10/2024

HAAP: Vision-context Hierarchical Attention Autoregressive with Adaptive Permutation for Scene Text Recognition
Honghui Chen, Yuhang Qiu, Jiabao Wang, Pingping Chen, Nam Ling
0
0
Internal Language Model (LM)-based methods use permutation language modeling (PLM) to solve the error correction caused by conditional independence in external LM-based methods. However, random permutations of human interference cause fit oscillations in the model training, and Iterative Refinement (IR) operation to improve multimodal information decoupling also introduces additional overhead. To address these issues, this paper proposes the Hierarchical Attention autoregressive Model with Adaptive Permutation (HAAP) to enhance the location-context-image interaction capability, improving autoregressive generalization with internal LM. First, we propose Implicit Permutation Neurons (IPN) to generate adaptive attention masks to dynamically exploit token dependencies. The adaptive masks increase the diversity of training data and prevent model dependency on a specific order. It reduces the training overhead of PLM while avoiding training fit oscillations. Second, we develop Cross-modal Hierarchical Attention mechanism (CHA) to couple context and image features. This processing establishes rich positional semantic dependencies between context and image while avoiding IR. Extensive experimental results show the proposed HAAP achieves state-of-the-art (SOTA) performance in terms of accuracy, complexity, and latency on several datasets.
5/16/2024