Ada-VE: Training-Free Consistent Video Editing Using Adaptive Motion Prior
2406.04873
0
0

Abstract
Video-to-video synthesis models face significant challenges, such as ensuring consistent character generation across frames, maintaining smooth temporal transitions, and preserving quality during fast motion. The introduction of joint fully cross-frame self-attention mechanisms has improved character consistency, but this comes at the cost of increased computational complexity. This full cross-frame self-attention mechanism also incorporates redundant details and limits the number of frames that can be jointly edited due to its computational cost. Moreover, the lack of frames in cross-frame attention adversely affects temporal consistency and visual quality. To address these limitations, we propose a new adaptive motion-guided cross-frame attention mechanism that drastically reduces complexity while preserving semantic details and temporal consistency. Specifically, we selectively incorporate the moving regions of successive frames in cross-frame attention and sparsely include stationary regions based on optical flow sampling. This technique allows for an increased number of jointly edited frames without additional computational overhead. For longer duration of video editing, existing methods primarily focus on frame interpolation or flow-warping from jointly edited keyframes, which often results in blurry frames or reduced temporal consistency. To improve this, we introduce KV-caching of jointly edited frames and reuse the same KV across all intermediate frames, significantly enhancing both intermediate frame quality and temporal consistency. Overall, our motion-sampling method enables the use of around three times more keyframes than existing joint editing methods while maintaining superior prediction quality. Ada-VE achieves up to 4x speed-up when using fully-extended self-attention across 40 frames for joint editing, without compromising visual quality or temporal consistency.
Create account to get full access
Overview
- This paper presents a method called "Ada-VE" for training-free and temporally consistent video editing.
- The key idea is to use an adaptive motion prior to propagate edits across video frames, ensuring smooth and coherent results without requiring any training.
- The method is demonstrated on various video editing tasks, such as object removal, object insertion, and style transfer.
Plain English Explanation
The Ada-VE method allows you to make edits to a video without having to train a complex machine learning model first. Instead, it uses an "adaptive motion prior" to understand how objects in the video are moving and propagate your edits across the different frames. This ensures that the edits look natural and consistent, without any jarring changes from one frame to the next.
For example, let's say you want to remove an object from a video. With Ada-VE, you can simply select the object in one frame, and the system will automatically remove it from the rest of the video, making sure that the surrounding scene looks seamless and coherent. Or if you want to insert a new object, Ada-VE will make sure it blends in with the rest of the video in a realistic way.
The key advantage of this approach is that it doesn't require any lengthy training process. You can just start editing the video right away, without having to prepare a dataset or fine-tune a model. This makes it much more accessible and practical for everyday video editing tasks.
Technical Explanation
The Ada-VE method works by leveraging an adaptive motion prior to propagate edits across video frames. This motion prior is learned directly from the input video, without requiring any additional training data or models.
The system first estimates the optical flow between adjacent frames, which captures the movement of objects and camera. It then uses this flow information to "warp" the edited content from one frame to the next, ensuring that the edits are temporally consistent.
This approach is in contrast to previous video editing methods that relied on complex neural network architectures and training regimes. Ada-VE avoids this overhead by working directly with the input video, making it more efficient and accessible.
The authors also demonstrate how Ada-VE can be combined with other video processing techniques to enable a variety of editing tasks, such as object removal, object insertion, and style transfer.
Critical Analysis
The Ada-VE method represents a promising approach to video editing that avoids the need for complex machine learning models and training. By leveraging the motion information inherent in the input video, it is able to achieve temporally consistent edits without any additional overhead.
However, the paper does note some limitations of the current approach. For example, it may struggle with handling occlusions or dealing with large camera movements. Additionally, the quality of the edits is still dependent on the accuracy of the underlying optical flow estimation.
Further research could explore ways to improve the robustness of the motion prior, perhaps by incorporating additional cues or using more advanced computer vision techniques. It would also be interesting to see how Ada-VE could be extended to handle more advanced editing tasks, such as manipulating the behavior of dynamic objects or enabling interactive editing workflows.
Overall, the Ada-VE method represents an important step forward in making video editing more accessible and practical, and the authors have laid the groundwork for exciting future developments in this area.
Conclusion
The Ada-VE method presented in this paper offers a novel approach to video editing that is training-free and temporally consistent. By leveraging an adaptive motion prior, the system is able to propagate edits across video frames in a seamless and coherent way, without requiring any complex machine learning models or lengthy training processes.
This makes the Ada-VE method a highly practical and accessible tool for a wide range of video editing tasks, from object removal and insertion to style transfer. While the current approach has some limitations, the authors have demonstrated the potential for this technique to transform the way we interact with and manipulate video content.
As the field of video editing continues to evolve, methods like Ada-VE that prioritize efficiency, accessibility, and temporal consistency are likely to become increasingly important. This paper represents an important contribution to this ongoing research and development effort.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
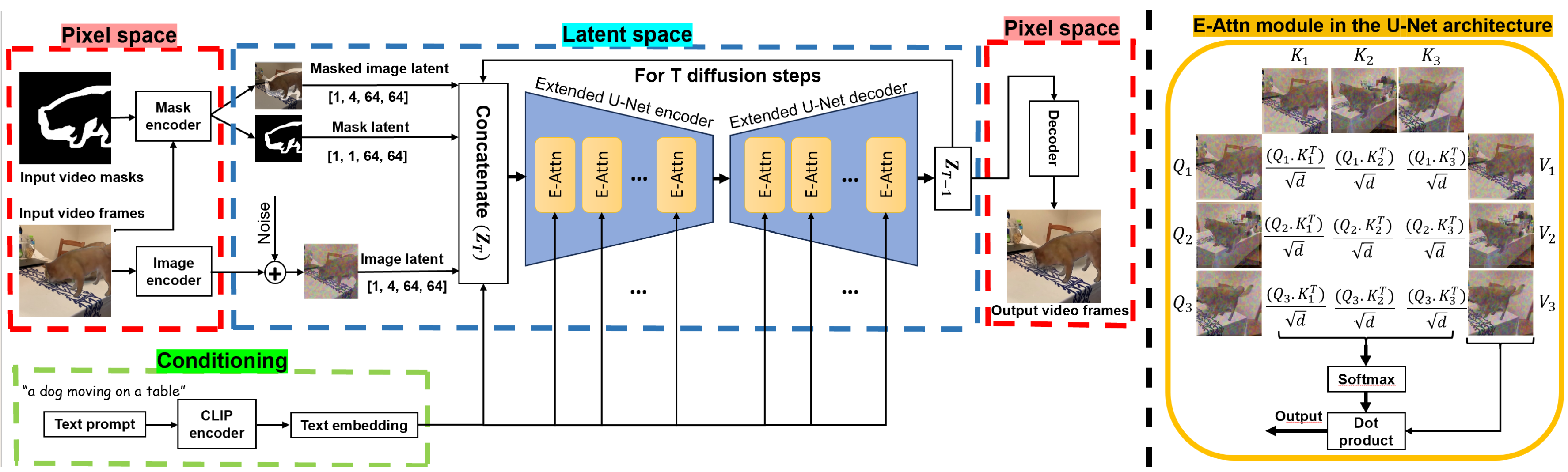
Temporally Consistent Object Editing in Videos using Extended Attention
AmirHossein Zamani, Amir G. Aghdam, Tiberiu Popa, Eugene Belilovsky
0
0
Image generation and editing have seen a great deal of advancements with the rise of large-scale diffusion models that allow user control of different modalities such as text, mask, depth maps, etc. However, controlled editing of videos still lags behind. Prior work in this area has focused on using 2D diffusion models to globally change the style of an existing video. On the other hand, in many practical applications, editing localized parts of the video is critical. In this work, we propose a method to edit videos using a pre-trained inpainting image diffusion model. We systematically redesign the forward path of the model by replacing the self-attention modules with an extended version of attention modules that creates frame-level dependencies. In this way, we ensure that the edited information will be consistent across all the video frames no matter what the shape and position of the masked area is. We qualitatively compare our results with state-of-the-art in terms of accuracy on several video editing tasks like object retargeting, object replacement, and object removal tasks. Simulations demonstrate the superior performance of the proposed strategy.
6/4/2024

I2VEdit: First-Frame-Guided Video Editing via Image-to-Video Diffusion Models
Wenqi Ouyang, Yi Dong, Lei Yang, Jianlou Si, Xingang Pan
0
0
The remarkable generative capabilities of diffusion models have motivated extensive research in both image and video editing. Compared to video editing which faces additional challenges in the time dimension, image editing has witnessed the development of more diverse, high-quality approaches and more capable software like Photoshop. In light of this gap, we introduce a novel and generic solution that extends the applicability of image editing tools to videos by propagating edits from a single frame to the entire video using a pre-trained image-to-video model. Our method, dubbed I2VEdit, adaptively preserves the visual and motion integrity of the source video depending on the extent of the edits, effectively handling global edits, local edits, and moderate shape changes, which existing methods cannot fully achieve. At the core of our method are two main processes: Coarse Motion Extraction to align basic motion patterns with the original video, and Appearance Refinement for precise adjustments using fine-grained attention matching. We also incorporate a skip-interval strategy to mitigate quality degradation from auto-regressive generation across multiple video clips. Experimental results demonstrate our framework's superior performance in fine-grained video editing, proving its capability to produce high-quality, temporally consistent outputs.
5/28/2024

VIA: A Spatiotemporal Video Adaptation Framework for Global and Local Video Editing
Jing Gu, Yuwei Fang, Ivan Skorokhodov, Peter Wonka, Xinya Du, Sergey Tulyakov, Xin Eric Wang
0
0
Video editing stands as a cornerstone of digital media, from entertainment and education to professional communication. However, previous methods often overlook the necessity of comprehensively understanding both global and local contexts, leading to inaccurate and inconsistency edits in the spatiotemporal dimension, especially for long videos. In this paper, we introduce VIA, a unified spatiotemporal VIdeo Adaptation framework for global and local video editing, pushing the limits of consistently editing minute-long videos. First, to ensure local consistency within individual frames, the foundation of VIA is a novel test-time editing adaptation method, which adapts a pre-trained image editing model for improving consistency between potential editing directions and the text instruction, and adapts masked latent variables for precise local control. Furthermore, to maintain global consistency over the video sequence, we introduce spatiotemporal adaptation that adapts consistent attention variables in key frames and strategically applies them across the whole sequence to realize the editing effects. Extensive experiments demonstrate that, compared to baseline methods, our VIA approach produces edits that are more faithful to the source videos, more coherent in the spatiotemporal context, and more precise in local control. More importantly, we show that VIA can achieve consistent long video editing in minutes, unlocking the potentials for advanced video editing tasks over long video sequences.
6/19/2024

Unified Editing of Panorama, 3D Scenes, and Videos Through Disentangled Self-Attention Injection
Gihyun Kwon, Jangho Park, Jong Chul Ye
0
0
While text-to-image models have achieved impressive capabilities in image generation and editing, their application across various modalities often necessitates training separate models. Inspired by existing method of single image editing with self attention injection and video editing with shared attention, we propose a novel unified editing framework that combines the strengths of both approaches by utilizing only a basic 2D image text-to-image (T2I) diffusion model. Specifically, we design a sampling method that facilitates editing consecutive images while maintaining semantic consistency utilizing shared self-attention features during both reference and consecutive image sampling processes. Experimental results confirm that our method enables editing across diverse modalities including 3D scenes, videos, and panorama images.
5/28/2024