Exploring the Frontier of Vision-Language Models: A Survey of Current Methodologies and Future Directions
2404.07214
0
0

Abstract
The advent of Large Language Models (LLMs) has significantly reshaped the trajectory of the AI revolution. Nevertheless, these LLMs exhibit a notable limitation, as they are primarily adept at processing textual information. To address this constraint, researchers have endeavored to integrate visual capabilities with LLMs, resulting in the emergence of Vision-Language Models (VLMs). These advanced models are instrumental in tackling more intricate tasks such as image captioning and visual question answering. In our comprehensive survey paper, we delve into the key advancements within the realm of VLMs. Our classification organizes VLMs into three distinct categories: models dedicated to vision-language understanding, models that process multimodal inputs to generate unimodal (textual) outputs and models that both accept and produce multimodal inputs and outputs.This classification is based on their respective capabilities and functionalities in processing and generating various modalities of data.We meticulously dissect each model, offering an extensive analysis of its foundational architecture, training data sources, as well as its strengths and limitations wherever possible, providing readers with a comprehensive understanding of its essential components. We also analyzed the performance of VLMs in various benchmark datasets. By doing so, we aim to offer a nuanced understanding of the diverse landscape of VLMs. Additionally, we underscore potential avenues for future research in this dynamic domain, anticipating further breakthroughs and advancements.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper provides a comprehensive survey of the current state of vision-language models (VLMs), which are a class of AI models that can understand and generate text based on visual information.
- The paper covers the latest methodologies, architectures, and applications of VLMs, as well as discusses future research directions in this rapidly evolving field.
- Key topics include multimodal learning, concept-based analysis, learning from limited data, and the use of synthetic data to improve VLM performance.
- The paper also addresses the challenges of evaluating large-scale VLMs and provides insights into the future direction of this rapidly evolving field.
Plain English Explanation
Vision-language models (VLMs) are a type of artificial intelligence that can understand and generate text based on visual information. These models have the potential to revolutionize how we interact with technology, enabling more natural and intuitive communication between humans and machines.
The paper provides a comprehensive overview of the current state of VLMs, covering the latest methodologies, architectures, and applications. It delves into how these models are trained to learn the relationship between visual and textual data, allowing them to perform tasks such as image captioning, visual question answering, and visual reasoning.
One key aspect of VLMs is their ability to learn concepts and representations from visual data, which can then be used to enhance language understanding and generation. The paper discusses how researchers are exploring concept-based analysis to better understand the inner workings of these models and improve their performance.
Another important area covered in the paper is the challenge of learning from limited data. VLMs are typically trained on large, diverse datasets, but in many real-world applications, such data may not be available. The paper explores techniques, such as the use of synthetic data, to address this challenge and enable VLMs to perform well even with limited training data.
Additionally, the paper discusses the importance of multimodal learning, where VLMs integrate information from multiple modalities (such as text, images, and audio) to gain a more comprehensive understanding of the world.
Finally, the paper addresses the challenges of evaluating large-scale VLMs and provides insights into the future direction of this rapidly evolving field, including the potential for these models to be used in a wide range of applications, from assistive technology to creative pursuits.
Technical Explanation
The paper presents a comprehensive survey of the current state of vision-language models (VLMs), which are a class of AI models that can understand and generate text based on visual information.
The authors begin by providing an overview of VLMs, explaining their key components and the underlying architectural principles. They discuss how these models are trained to learn the relationship between visual and textual data, enabling them to perform a variety of tasks, such as image captioning, visual question answering, and visual reasoning.
One of the central themes of the paper is the concept-based analysis of VLMs. The authors explore how researchers are using concept-based analysis to better understand the internal representations and decision-making processes of these models. By identifying and analyzing the learned concepts, researchers can gain insights into the models' strengths, weaknesses, and potential biases.
Another key aspect covered in the paper is the challenge of learning from limited data. VLMs are typically trained on large, diverse datasets, but in many real-world applications, such data may not be available. The paper discusses various techniques, including the use of synthetic data, to address this challenge and enable VLMs to perform well even with limited training data.
The paper also delves into the importance of multimodal learning, where VLMs integrate information from multiple modalities (such as text, images, and audio) to gain a more comprehensive understanding of the world. The authors explore how this approach can lead to improved performance and more robust models.
Finally, the paper addresses the challenges of evaluating large-scale VLMs and provides insights into the future direction of this rapidly evolving field. The authors discuss the need for more robust and comprehensive evaluation metrics, as well as the potential for VLMs to be used in a wide range of applications, from assistive technology to creative pursuits.
Critical Analysis
The paper provides a thorough and insightful analysis of the current state of vision-language models, highlighting both the impressive capabilities of these models and the challenges that researchers are working to overcome.
One of the key strengths of the paper is its comprehensive coverage of the latest methodologies and architectures in the field. The authors do an excellent job of explaining the underlying principles and techniques, making the content accessible to a wide audience. However, the paper could have delved deeper into the technical details and specific implementation approaches used by various VLM models.
The discussion of concept-based analysis is particularly compelling, as it underscores the importance of understanding the internal representations and decision-making processes of these complex models. This is an important area of research that can lead to more transparent and trustworthy VLMs. The paper could have explored this topic in greater depth, providing more examples and case studies to illustrate the practical applications of this approach.
The paper's coverage of the challenges associated with learning from limited data is also noteworthy. The authors rightly highlight the importance of addressing this issue, as many real-world applications of VLMs will involve working with relatively small datasets. The discussion of synthetic data generation techniques is a promising direction, but the paper could have provided a more critical evaluation of the strengths and limitations of this approach.
While the paper acknowledges the need for robust evaluation metrics for large-scale VLMs, it could have delved deeper into this topic. As the field continues to evolve rapidly, developing reliable and comprehensive evaluation frameworks will be crucial for ensuring the continued progress and responsible deployment of these models.
Overall, this paper provides a valuable and timely contribution to the ongoing research in the field of vision-language models. By highlighting the current state of the art, as well as the key challenges and future directions, the authors have laid the groundwork for further advancements in this exciting area of artificial intelligence.
Conclusion
This comprehensive survey paper provides a detailed overview of the current state of vision-language models (VLMs), a rapidly evolving field of artificial intelligence that is transforming how humans and machines interact.
The paper covers the latest methodologies, architectures, and applications of VLMs, delving into key topics such as multimodal learning, concept-based analysis, learning from limited data, and the use of synthetic data to improve model performance.
By addressing the challenges of evaluating large-scale VLMs and providing insights into future research directions, the paper serves as a valuable resource for researchers, developers, and practitioners working in this exciting field.
The potential applications of VLMs are vast, ranging from assistive technology and creative pursuits to more natural and intuitive human-machine interaction. As the field continues to evolve, this paper offers a comprehensive understanding of the current state of the art and the key considerations for the responsible development and deployment of these powerful AI models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Vision-Language Models for Medical Report Generation and Visual Question Answering: A Review
Iryna Hartsock, Ghulam Rasool
0
0
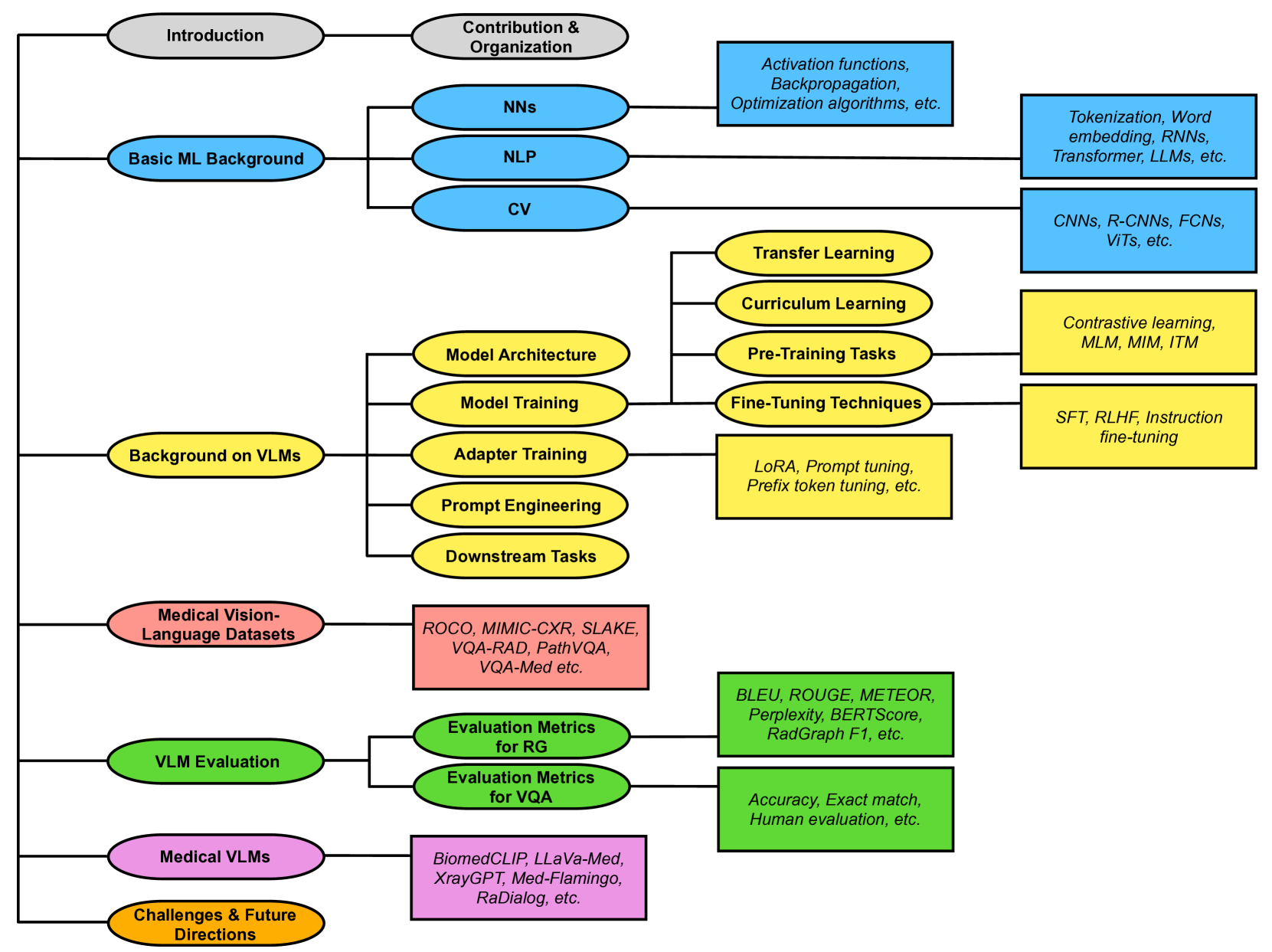
Medical vision-language models (VLMs) combine computer vision (CV) and natural language processing (NLP) to analyze visual and textual medical data. Our paper reviews recent advancements in developing VLMs specialized for healthcare, focusing on models designed for medical report generation and visual question answering (VQA). We provide background on NLP and CV, explaining how techniques from both fields are integrated into VLMs to enable learning from multimodal data. Key areas we address include the exploration of medical vision-language datasets, in-depth analyses of architectures and pre-training strategies employed in recent noteworthy medical VLMs, and comprehensive discussion on evaluation metrics for assessing VLMs' performance in medical report generation and VQA. We also highlight current challenges and propose future directions, including enhancing clinical validity and addressing patient privacy concerns. Overall, our review summarizes recent progress in developing VLMs to harness multimodal medical data for improved healthcare applications.
4/16/2024

A Review of Multi-Modal Large Language and Vision Models
Kilian Carolan, Laura Fennelly, Alan F. Smeaton
0
0
Large Language Models (LLMs) have recently emerged as a focal point of research and application, driven by their unprecedented ability to understand and generate text with human-like quality. Even more recently, LLMs have been extended into multi-modal large language models (MM-LLMs) which extends their capabilities to deal with image, video and audio information, in addition to text. This opens up applications like text-to-video generation, image captioning, text-to-speech, and more and is achieved either by retro-fitting an LLM with multi-modal capabilities, or building a MM-LLM from scratch. This paper provides an extensive review of the current state of those LLMs with multi-modal capabilities as well as the very recent MM-LLMs. It covers the historical development of LLMs especially the advances enabled by transformer-based architectures like OpenAI's GPT series and Google's BERT, as well as the role of attention mechanisms in enhancing model performance. The paper includes coverage of the major and most important of the LLMs and MM-LLMs and also covers the techniques of model tuning, including fine-tuning and prompt engineering, which tailor pre-trained models to specific tasks or domains. Ethical considerations and challenges, such as data bias and model misuse, are also analysed to underscore the importance of responsible AI development and deployment. Finally, we discuss the implications of open-source versus proprietary models in AI research. Through this review, we provide insights into the transformative potential of MM-LLMs in various applications.
4/3/2024
What matters when building vision-language models?
Hugo Laurenc{c}on, L'eo Tronchon, Matthieu Cord, Victor Sanh
0
0
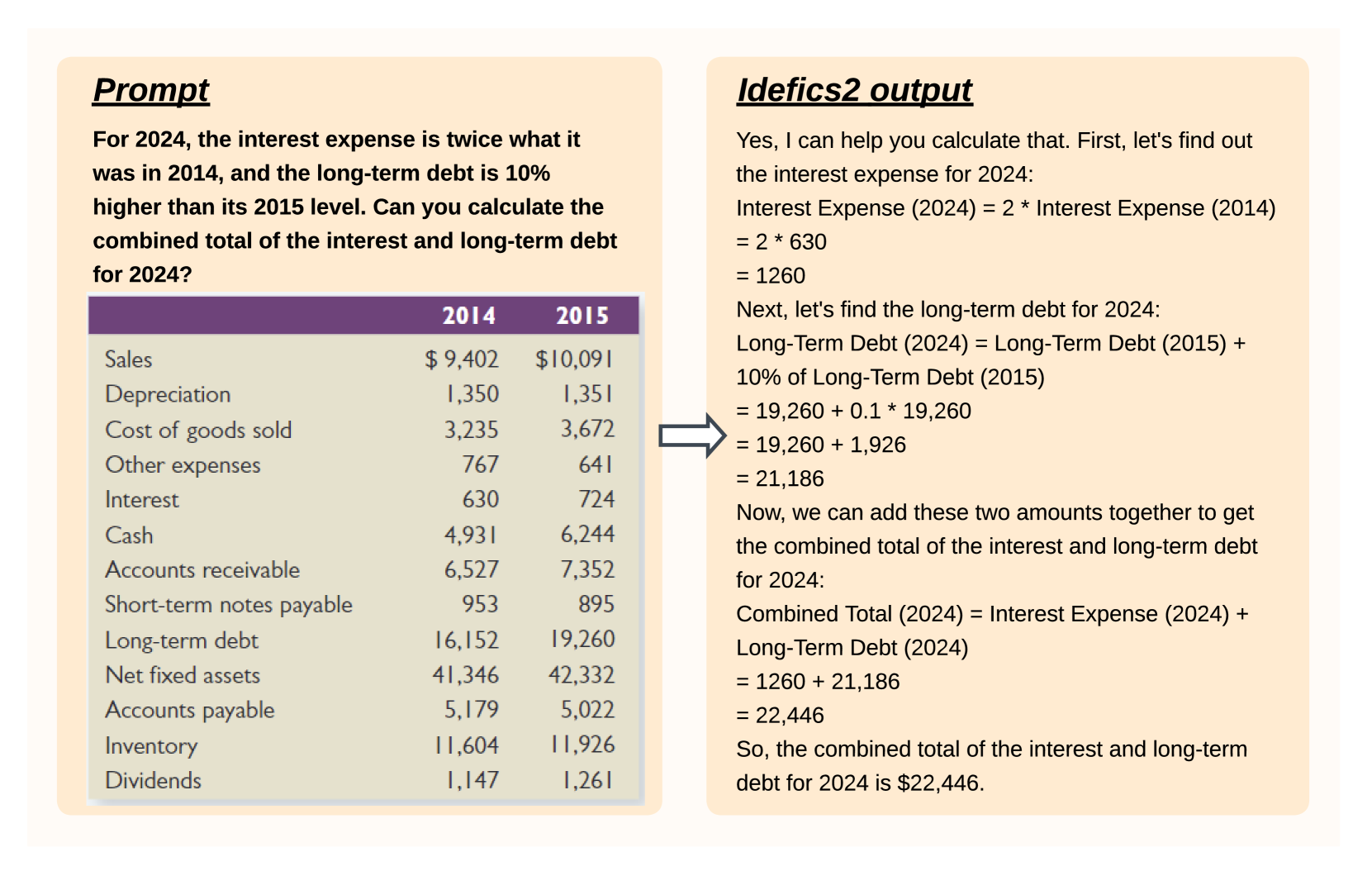
The growing interest in vision-language models (VLMs) has been driven by improvements in large language models and vision transformers. Despite the abundance of literature on this subject, we observe that critical decisions regarding the design of VLMs are often not justified. We argue that these unsupported decisions impede progress in the field by making it difficult to identify which choices improve model performance. To address this issue, we conduct extensive experiments around pre-trained models, architecture choice, data, and training methods. Our consolidation of findings includes the development of Idefics2, an efficient foundational VLM of 8 billion parameters. Idefics2 achieves state-of-the-art performance within its size category across various multimodal benchmarks, and is often on par with models four times its size. We release the model (base, instructed, and chat) along with the datasets created for its training.
5/6/2024
Concept-based Analysis of Neural Networks via Vision-Language Models
Ravi Mangal, Nina Narodytska, Divya Gopinath, Boyue Caroline Hu, Anirban Roy, Susmit Jha, Corina Pasareanu
0
0
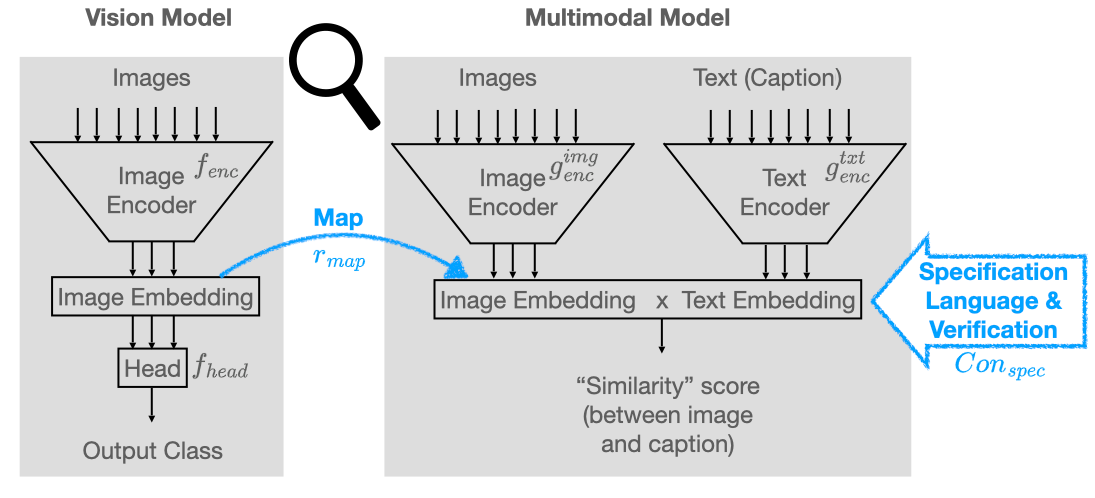
The analysis of vision-based deep neural networks (DNNs) is highly desirable but it is very challenging due to the difficulty of expressing formal specifications for vision tasks and the lack of efficient verification procedures. In this paper, we propose to leverage emerging multimodal, vision-language, foundation models (VLMs) as a lens through which we can reason about vision models. VLMs have been trained on a large body of images accompanied by their textual description, and are thus implicitly aware of high-level, human-understandable concepts describing the images. We describe a logical specification language $texttt{Con}_{texttt{spec}}$ designed to facilitate writing specifications in terms of these concepts. To define and formally check $texttt{Con}_{texttt{spec}}$ specifications, we build a map between the internal representations of a given vision model and a VLM, leading to an efficient verification procedure of natural-language properties for vision models. We demonstrate our techniques on a ResNet-based classifier trained on the RIVAL-10 dataset using CLIP as the multimodal model.
4/12/2024